

二叉搜索树
博客参考B站视频:https://www.bilibili.com/video/BV1UJ411J7CU
一、二叉搜索树的定义
二叉搜索树是一种有顺序的特殊的二叉树,它有以下要求
1,若它的左子树不空,则左子树所有的结点的值均小于根结点的值
2. 若它的右子树不空,则右子树所有的结点的值均大于根节点的值
3. 左右子树也分别为二叉搜索树。
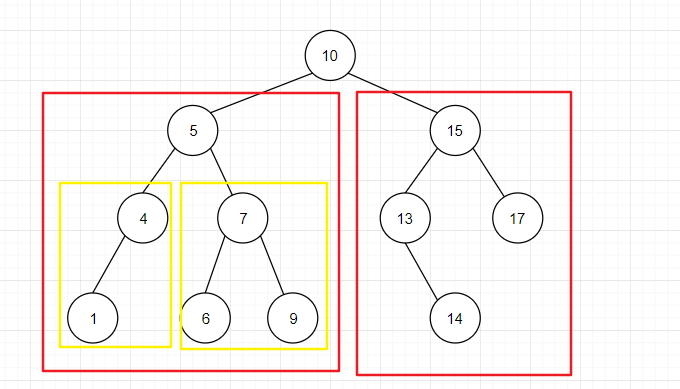
上图就是一颗二叉搜索树,左边红框中的结点的值均小于根结点 10 ,右边红框中的结点的值均大于根结点 10;黄框则是相对于结点 5 的二叉搜索树。
至于值与根结点的值相等的结点,可以放在左边,也可以放在右边,在没有外在干扰的情况下,这个是可以由你自己编写二叉树代码时决定的。
二、查找结点
从根结点开始遍历
1. 若查找值比当前结点值大,则搜索右子树;
2. 若查找值比当前结点值小,则搜索左子树;
3. 若查找值与当前结点值相等,停止搜索(终止条件)
4. 做最后遍历到 null 结点前都没有找到相等结点,则该二叉搜索树中无该值的结点。
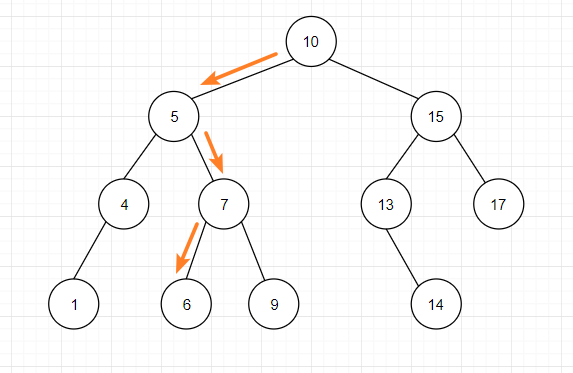
例如:在上图的二叉搜索树中查找 6 ,
(1)从根结点开始,根结点为 10 ,6 < 10 所以搜索左子树;(右子树直接排除可能,减少了一半的数据量)
(2)当前结点为 5,6 > 5 所以搜索右子树;
(3)当前结点为 7 ,6 < 7 所以搜索左子树
(4)当前结点为 6,查找值与当前结点值相同,查找成功。
三、插入结点
要插入结点,必须先找到插入的位置,这个查找过程与上面描述的过程类似。
从分界点开始进行比较,小于根结点则与根结点的左子树进行比较,否则与右子树进行比较,直到左子树为空或右子树为空,则插入到相应为空的位置。
四、遍历结点
遍历二叉树有三种遍历方法:
1. 中序遍历:左子树 --》 根结点 --》右子树
2. 前序遍历:根结点 --》 左子树 --》右子树
3. 后序遍历:左子树 --》 右子树 --》 根结点
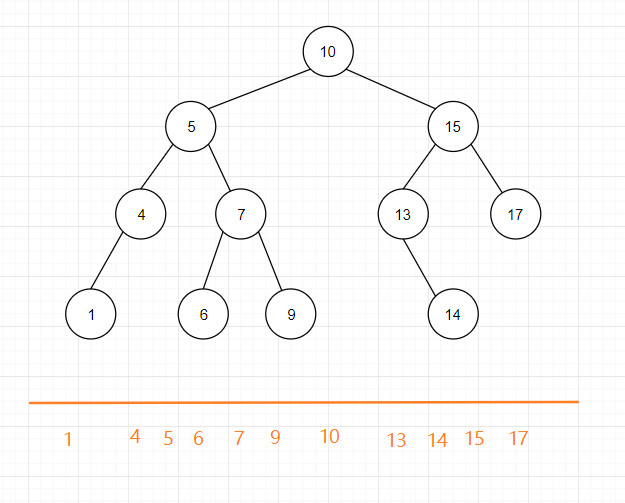
二叉搜索树一般采用中序遍历,因为这样遍历读取出来的数是有顺序的。
例如上图例子,根据中序遍历出来的结果就是:(可以看到是按照从小到大的顺序进行排序的)。
五、查找最大最小值
根据上面遍历的结果可以看出,最小值在最左边,最大值在最右边。
所以,查找最小值,就是沿着根结点不断向左结点遍历,直到某个结点的左结点为 null,则找到最小值,最大值同理。
六、删除结点
删除的节点一共有三种情况:
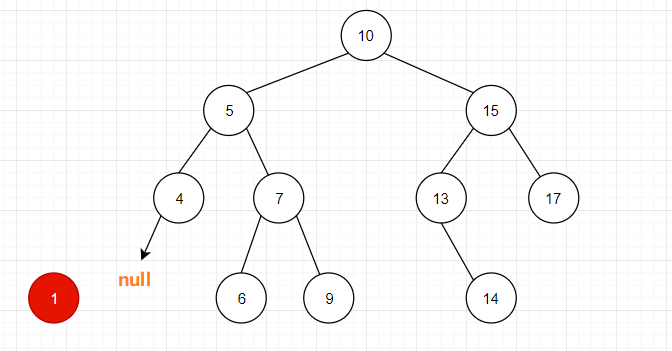
1. 删除没有节点的结点。
当删除的结点为叶子节点时,直接将其删除即可,也就是将父节点原本指向删除节点的指针重新指向 null。(java 没有指针概念,但是姑且可以这么理解)
2. 删除有一个节点的节点。
这个也比较容易,删除有一个节点的节点时,只要将删除节点的父节点中原本指向删除节点的指针重新指向删除节点的子节点就可以了。
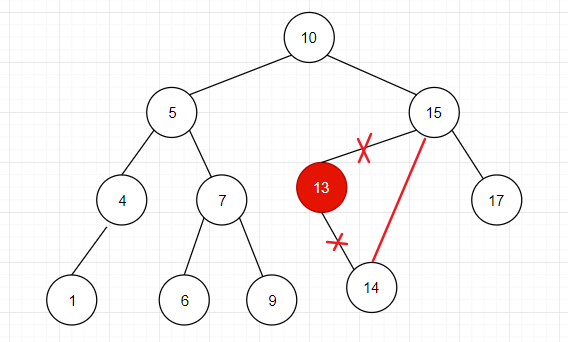
3. 删除有两个节点的节点。
这个相较于前两个会稍微复杂一点,但是原理都不难理解。
例如,要删除值为 5 的节点,该节点既有左节点又有右节点,当我们删除该节点后,以这个节点为根结点的数就“失联”了,因此需要另一个节点来代替这个节点的位置,选什么样的节点比较好呢?
我们知道二叉搜索树中的节点时按照关键字来进行排序的,某个节点的关键字次时它的中序遍历的后继节点
后继节点就是大于这个节点的最小节点,因此在该例子中, 5 的后继节点就是值为 6 的节点,因此,将值为 6 的节点提到原本 5 的位置即可。
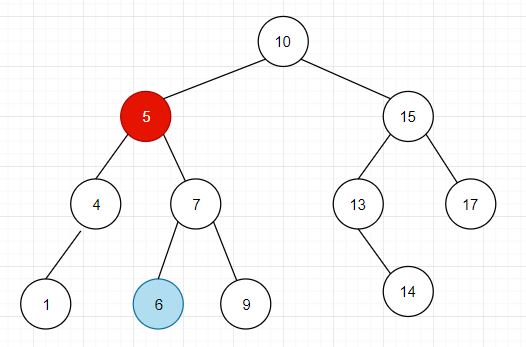
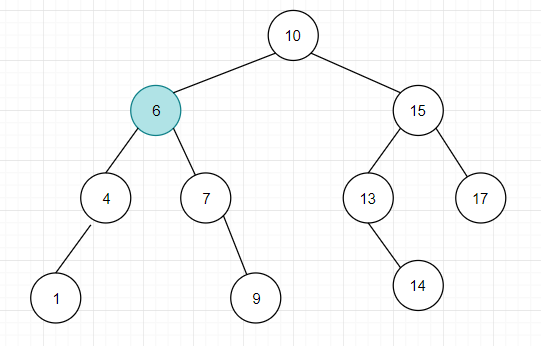
但是由于删除节点不仅要判断节点类型,还要调整位置,所以一般情况下不会真的在物理上将其删除,只是在该节点做一个标记说明该节点已被删除,即只在逻辑上将该节点删除。
七、二叉搜索树-时间复杂度分析
1. 二分查找算法
[1,2,3,4,5,6,7,8,9,...,99,100]
/** * 二分查找算法 * @param array 有序数组 * @param data 要查找的数据 * @return 返回要查找数据在数组中的下标,如果查找失败,返回 -1 */ public int binarySearch(int[] array, int data) { int low = 0; int height = array.length - 1; while (low <= height) { int mid = low + ((height - low) >> 1); if (array[mid] < data) { low = mid + 1; } else if (array[mid] == data) { return mid; } else { height = mid - 1; } } return -1; }
二分查找算法:数据源必须是有序数组,性能非常不错,每次迭代查询可以排除一半的结果。
2. 二分查找算法最大的缺陷是什么?
强制依赖 有序数组,性能才能不错
3. 数组有什么缺陷?
在这篇博客中提到了数组的缺陷,如果还不太清楚的可以看一下。 https://www.cnblogs.com/lyw-hunnu/p/12599967.html
4. 用链表可以比较好的掩盖数组的缺点,但是链表不利于查找,怎么样才可以拥有二分查找的高性能又能拥有链表一样的灵活呢?
使用二分搜索树就可以。
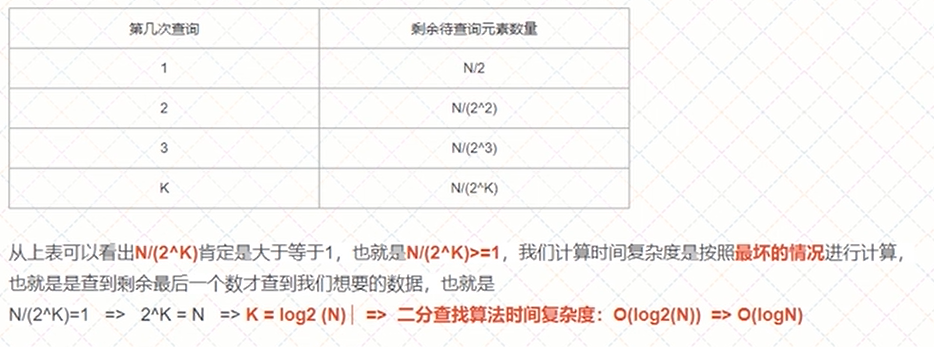
5. 二分查找树算法时间复杂度推算过程。(这里的图来自上方提供的视频)
八、普通二分搜索树的缺陷
普通的二叉搜索树可能会失衡,导致如下图所示的情况,此时二叉搜索树相当于链表,查找速率将为 O(n)
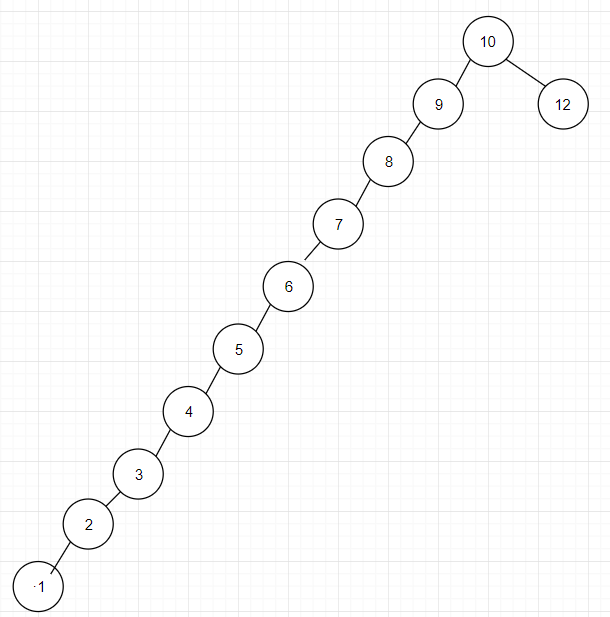
怎么才能更好的解决这个问题呢?
如果在插入节点时,可以自动调整两边平衡,就会保持不错的性能。
九,AVL 树
1. AVL树具有什么特点呢?
具有二叉搜索树的全部特性
每个节点的左子树和右子树的高度相差至多等于1.
平衡树基于这种特点就可以保证不会出现大量节点偏向于一边的情况了
因为 插入和删除时,会发生左旋、右旋操作,使得这棵树再次左右保持一致。
2. 为什么又了平衡树还需要红黑树?
虽然平衡树解决了二叉树退化为近似链表的缺点,能够把查找时间控制在 O(logN) ,不过却不是最佳的
因为平衡树要求每个节点的左子树和右子树的高度差至多等于 1,这个要求实在是太严了,导致每次进行插入或删除节点的时候,
几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁地进行调整,这回使平衡树地性能大打折扣,为了解决这个问题,于是提出了红黑树。
