【模板】LCA
LCA
简单说一下,LCA(Least Common Ancestors),最近公共祖先,字面上的意思,就是两个节点的公共祖先中,最近的那一个
算法
一、暴力
在线算法
首先dfs预处理出每个点的深度,然后再将u,v中比较深的那个点往上爬,将他们调整到同一深度
然后再一起一步一步地爬树,爬到同一深度
暴力算法的复杂度相比其他算法较高,但由于它非常的简单清晰,所以在时间不够的时候很好写,可以骗分 。
另外,如果树是随机的或者满足一些特定性质,也能用
#include<cstdio>
#include<vector>
using namespace std;
#define MAXN 1005
int dep[MAXN],f[MAXN];
vector<int>G[MAXN];
void dfs(int u,int fa)
{
for(int i=0;i<G[u].size();i++)
{
int v=G[u][i];
if(v==fa) continue;
dep[v]=dep[u]+1;
f[v]=u;
dfs(v,u);
}
}
int lca(int u,int v)
{
while(dep[u]>dep[v]) u=f[u];
while(dep[u]<dep[v]) v=f[v];
if(u==v) return u;
while(u!=v)
u=f[u],v=f[v];
return u;
}
int main()
{
}
二、欧拉序+rmq
在线算法
时间戳和欧拉序
时间戳(st[i]):第i个节点第一次被访问到的时间,即:若访问一个节点需要花费一个单位时间,第一次访问到当前节点是在第几个单位时间被访问到
欧拉序是一棵树按照dfs的顺序产生的序列,相当于模拟dfs的过程
For instance:

比如说,上面的例子的欧拉序就是:
1
1
1
2
2
2
4
4
4
2
2
2
5
5
5
8
8
8
5
5
5
2
2
2
1
1
1
3
3
3
6
6
6
3
3
3
7
7
7
3
3
3
1
1
1
而时间戳st[]:
s
t
[
1
]
=
1
st[1]=1
st[1]=1
s
t
[
2
]
=
2
st[2]=2
st[2]=2
s
t
[
3
]
=
10
st[3]=10
st[3]=10
s
t
[
4
]
=
3
st[4]=3
st[4]=3
s
t
[
5
]
=
5
st[5]=5
st[5]=5
s
t
[
6
]
=
11
st[6]=11
st[6]=11
s
t
[
7
]
=
13
st[7]=13
st[7]=13
s
t
[
8
]
=
6
st[8]=6
st[8]=6
(说白了时间戳就是欧拉序的下标 欧拉序记为seq[] 的话,
s
e
q
[
s
t
[
i
]
]
=
i
seq[st[i]]=i
seq[st[i]]=i
欧拉序的性质:(u,v)的lca一定在欧拉序的[st[u],st[v]]这个区间中
还是比较好理解的,因为访问每一个节点之前要先访问他的爸爸和祖先们,访问完了这个节点之后还要回溯回去再一次地访问他的爸爸和祖先们,所以[st[u],st[v]]内一定有u的祖先,还有v的祖先,所以lca就一定在这个区间之内
有了这个性质,但是我们还是不能准确地找出lca
经过仔细观察研究推敲思考对比得出:
**敲黑板划重点:lca是[st[u],st[v]]中深度最小的那个点
注意是 深度最小
可以这么理解
因为lca相当于这两个点互相联通的一个桥梁,假设在dfs的过程中,我们只有先通过了[st[u],st[v]]中深度最小的那个点才能到达另外那个点,而不过[st[u],st[v]]中深度最小的那个点,我们是到不了另外那个点的(dfs的性质)
(这里有点不好说,仔细体会一下)
由上,我们已经有了一个比较清晰的思路
在搞欧拉序的同时我们搞一个序列存与之对应的点的深度
然后用rmq求出深度最小的那个点,就是lca
还是这个例子
设e[]为欧拉序,dep[i]为节点e[i]的深度 st[i]为节点i在e[]中第一次出现的下标


rmq
RMQ可以用数据结构,比如线段树,也可以用st表
st表
这里主要说一下st表
复杂度
O
(
n
+
n
l
o
g
n
)
O(n+nlogn)
O(n+nlogn),询问
O
(
1
)
O(1)
O(1)
st表的思想其实也就是dp和倍增
设
f
(
i
,
j
)
f(i,j)
f(i,j)表示
[
i
,
i
+
2
j
−
1
]
[i,i+2^j-1]
[i,i+2j−1]的最小值
[
i
,
i
]
[i,i]
[i,i]的最小值就是
a
[
i
]
a[i]
a[i],所以
f
(
i
,
0
)
=
a
[
i
]
f(i,0)=a[i]
f(i,0)=a[i]
转移的时候将
[
i
,
i
+
2
j
−
1
]
[i,i+2^j-1]
[i,i+2j−1]平均分成两部分:
[
i
,
i
+
2
j
−
1
−
1
]
[i,i+2^{j-1}-1]
[i,i+2j−1−1]和
[
i
+
2
j
−
1
,
i
+
2
j
−
1
]
[i+2^{j-1},i+2^j-1]
[i+2j−1,i+2j−1]
[
i
,
i
+
2
j
−
1
]
[i,i+2^j-1]
[i,i+2j−1]的最小值是
[
i
,
i
+
2
j
−
1
−
1
]
[i,i+2^{j-1}-1]
[i,i+2j−1−1]和
[
i
+
2
j
−
1
,
i
+
2
j
−
1
]
[i+2^{j-1},i+2^j-1]
[i+2j−1,i+2j−1]中的最小值的最小值
即 f ( i , j ) = m i n ( f ( i , j − 1 ) , f ( i + 2 j − 1 , j − 1 ) ) f(i,j)=min(f(i,j-1),f(i+2^{j-1},j-1)) f(i,j)=min(f(i,j−1),f(i+2j−1,j−1))
查询的时候 因为查询的区间 [ l , r ] [l,r] [l,r]的长度不一定就是2的整数次幂,所以我们就取区间长度的log值 (要下取整,不能上取整,否则会涉及到其他区间的数,可能会影响答案) 。由于不一定会覆盖到整个区间,我们把它劈成两部分,一部分以l为起点,另一部分以r为终点。由于是求最值,所以区间的重叠并没有什么影响。
另外,相邻两节点的深度的变化量为1,±1RMQ(约束RMQ)有更优的解法,这里先不展开
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
#define MAXN 50005
int n,m;
struct node{
int v,w;
};
vector<node>G[MAXN];//邻接表
int dp[MAXN*2][20];//st表
int dis[MAXN];//每个点到根节点的距离
int cnt=1,seq[MAXN*2-1]/*欧拉序*/,dep[MAXN*2-1],st[MAXN];
//dfs 得到dis seq dep st
void dfs(int u,int p,int d)
{
seq[cnt]=u,st[u]=cnt,dep[cnt++]=d;
for(int i=0;i<G[u].size();i++)
{
int v=G[u][i].v,w=G[u][i].w;
if(v==p) continue;
dis[v]=dis[u]+w;
dfs(v,u,d+1);
seq[cnt]=u;
dep[cnt++]=d;
}
}
//st表
void RMQ(int k)
{
for(int i=1;i<=k;i++)
dp[i][0]=i;
for(int j=1;(1<<j)/*2^j*/<=k;j++)
for(int i=1;i+(1<<j)-1<=k;i++)
{
int a=dp[i][j-1],b=dp[i+(1<<(j-1))][j-1];
if(dep[a]<dep[b])
dp[i][j]=a;
else dp[i][j]=b;
//这里的st表存的是深度最低的点的seq的下标
}
}
//询问最小值
int Query(int l,int r)
{
int k=0;
while(1<<(k+1)<=r-l+1)
k++;
int a=dp[l][k],b=dp[r-(1<<k)+1][k];
if(dep[a]<dep[b])
return a;
return b;
}
int lca(int u,int v)
{
return seq[Query(min(st[u],st[v]),max(st[u],st[v]))];
}
int main()
{
}
三、倍增
在线算法
和st表求区间最值类似
暴力求区间最值需要一个一个比较
暴力求lca需要一步一步爬树
st表用倍增比较一段和一段间的最值
启发我们求lca也用倍增,一次向上爬
2
i
2^i
2i个点
设
f
(
i
,
j
)
f(i,j)
f(i,j)表示点i向上跳
2
j
2^j
2j步之后的点
边界:
f
(
i
,
0
)
=
f
a
[
i
]
f(i,0)=fa[i]
f(i,0)=fa[i] (表示向上跳一步的点)
转移:跳
2
j
2^j
2j步,先跳
2
j
−
1
2^{j-1}
2j−1步,再跳
2
j
−
1
2^{j-1}
2j−1步
f
(
i
,
j
)
=
f
(
f
(
i
,
j
−
1
)
,
j
−
1
)
f(i,j)=f(f(i,j-1),j-1)
f(i,j)=f(f(i,j−1),j−1)
先调整u,v到同一深度(深的点向上爬)
不过别一步一步爬,用f数组向上跳
再让u,v一起向上跳
从大到小枚举j,试图让u和v向上跳2^j步,如果u和v将要跳到同一个点,就不跳(因为可能跳到lca的上面),否则就爬树
最后向上爬一步就是lca,时间复杂度O(logn)
这张图看起来好像到处都是 我也贴一下吧

例题&板子 传送门:poj 1986
#include<cstdio>
#include<vector>
#include<algorithm>
#include<cstring>
using namespace std;
#define MAXN 50005
struct node{
int v,w;
};
int n,m;
vector<node>G[MAXN];
int dis[MAXN],dep[MAXN],f[MAXN][20];
//f[i][j]:点i向上跳2^j步之后的点
void Init()
{
for(int j=1;(1<<j)<=n;j++)//内外层的顺序主要是因为更新时j是由小到大来的,而i(f[i][j-1])相对不确定
for(int i=1;i<=n;i++)//而如果用j为外层 那么也是可以保证i(f[i][j-1])已经被更新
if(f[i][j-1]!=-1)
f[i][j]=f[f[i][j-1]][j-1];
return ;
}
void swp(int &a,int &b)
{
int t=a;
a=b;
b=t;
return ;
}
void dfs(int u,int p,int d)
{
dep[u]=d;
for(int i=0;i<G[u].size();i++)
{
int v=G[u][i].v,w=G[u][i].w;
if(v==p) continue;
f[v][0]=u;
dis[v]=dis[u]+w;
dfs(v,u,d+1);
}
}
int LCA(int u,int v)
{
if(dep[u]<dep[v])
swp(u,v);//u的深度更深
int k=0;
while((1<<k)<=dep[u])//j的范围
k++;
k--;
//较深的那一个点爬到与另一个点相等的深度
for(int j=k;j>=0;j--)
if(dep[u]-(1<<j)>=dep[v])
u=f[u][j];
while(dep[u]>dep[v])
u=f[u][0];
if(u==v) return u;
for(int j=k;j>=0;j--)
{
if(f[u][j]!=f[v][j]&&f[u][j]!=-1&&f[v][j]!=-1)
u=f[u][j],v=f[v][j];
}
return f[u][0];
}
int ans(int u,int v)
{
return dis[u]+dis[v]-2*dis[LCA(u,v)];
}
int main()
{
scanf("%d %d",&n,&m);
for(int i=1;i<=m;i++)
{
int u,v,w;
scanf("%d %d %d %*s",&u,&v,&w);
node t;t.v=v,t.w=w;
G[u].push_back(t);
t.v=u,G[v].push_back(t);
}
memset(f,-1,sizeof(f));//-1的状态即为不合法的状态(比方说,跳出去了
dfs(1,-1,0);
Init();//倍增 处理f函数
int T;
scanf("%d",&T);
while(T--)
{
int u,v;
scanf("%d %d",&u,&v);
printf("%d\n",ans(u,v));
}
return 0;
}
然后就是 倍增的思想可以解决一些树上路径问题,而之前的RMQ的方法却不能解决
四、tarjan
离线算法
先记录所有询问,然后对树做一次dfs求出所有点对的lca
在进入u这个点的时候,把边(u,fa(u))删除,此时就形成以u为根的一棵子树,并且记录u已被访问过,然后依次遍历u的所有子节点
在遍历结束后,查找所有跟u有关的查询(u,vi),若vi已被访问过,则lca(u,vi)是vi所在子树的根
最后在退出u的时候把边(u,fa(u))重新加上
下面的例子偷了一下学长的ppt

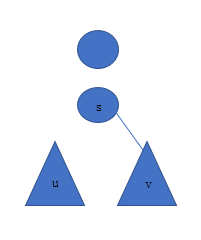
现在先dfs到u,发现v还没访问过,不更新答案




实际上删边,加边和查询所在子树的根都不方便直接实现
假设一开始边都是被删掉的(假设边被删掉了也可以走,只是对查询所在子树的根有影响),在退出的时候才把边加上
现在只加边,且查询所在子树的根,可以用并查集实现
在初始化或者进入u这个点的时候,让f(u)=u(这里的f是并查集中的,不是树上的)
在退出u的时候,让f(u)=fa(u)
查询u所在子树的根就变成find(u)
设并查集时间复杂度为常数,则时间复杂度O(n+m)
板子&例题:Distance Queries
#include<cstdio>
#include<algorithm>
#include<vector>
using namespace std;
#define MAXN 50005
#define MAXK 10005
int n,m,f[MAXN],dis[MAXN],ans[MAXK];
bool vis[MAXN];
struct node{
int v,w;
};
vector<node>G[MAXN];
vector<pair <int,int> >Q[MAXN];
//-----------
int Find(int x)
{
if(f[x]!=x)
return f[x]=Find(f[x]);
return f[x];
}
//-----------
void Tarjan(int u,int fa)
{
f[u]=u;
for(int i=0;i<G[u].size();i++)
{
int v=G[u][i].v,w=G[u][i].w;
if(v==fa) continue;
dis[v]=dis[u]+w;
Tarjan(v,u);
f[v]=u;
}
vis[u]=1;
for(int i=0;i<Q[u].size();i++)
{
int v=Q[u][i].first,id=Q[u][i].second;
if(vis[v])
ans[id]=dis[u]+dis[v]-2*dis[Find(v)];
}
return ;
}
int main()
{
scanf("%d %d",&n,&m);
for(int i=1;i<=m;i++)
{
int u,v,w;
scanf("%d %d %d %*s",&u,&v,&w);
node t;
t.v=v,t.w=w;
G[u].push_back(t);
t.v=u,G[v].push_back(t);
}
int T;
scanf("%d",&T);
for(int i=1;i<=T;i++)
{
int u,v;
scanf("%d %d",&u,&v);
Q[u].push_back(make_pair(v,i));
Q[v].push_back(make_pair(u,i));
}
Tarjan(1,-1);
for(int i=1;i<=T;i++)
printf("%d\n",ans[i]);
return 0;
}
注意我之前写的时候抄了一下并查集的板子
void Union(int x,int y)
{
int u=Find(x),v=Find(y);
if(u==v)
return ;
if(u>v) f[x]=y;
f[y]=x;
}
但是用这个东西是不对的 因为他有压缩合并,并到最上面的节点去了 会破坏原来树的形态 在找根的时候就会错
我们直接很简单地把它连起来就可以了
f[v]=u;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号