【单调队列优化dp】jzoj4883灵知的太阳信仰 纪中集训提高B组
【NOIP2016提高A组集训第12场11.10】灵知的太阳信仰
(File IO): input:array.in output:array.out
Time Limits: 1000 ms Memory Limits: 131072 KB Detailed Limits
Description
在炽热的核熔炉中,居住着一位少女,名为灵乌路空。
据说,从来没有人敢踏入过那个熔炉,因为人们畏缩于空所持有的力量——核能。
核焰,可融真金。
咳咳。
每次核融的时候,空都会选取一些原子,排成一列。然后,她会将原子序列分成一些段,并将每段进行一次核融。
一个原子有两个属性:质子数和中子数。
每一段需要满足以下条件:
1、同种元素会发生相互排斥,因此,同一段中不能存在两个质子数相同的原子。
2、核融时,空需要对一段原子加以防护,防护罩的数值等于这段中最大的中子数。换句话说,如果这段原子的中子数最大为x,那么空需要付出x的代价建立防护罩。求核融整个原子序列的最小代价和。
Input
第一行一个正整数N,表示原子的个数。
接下来N行,每行两个正整数pi和ni,表示第i个原子的质子数和中子数。
Output
输出一行一个整数,表示最小代价和。
Sample Input
5
3 11
2 13
1 12
2 9
3 13
Sample Output
26
Data Constraint
对于20%的数据,1<=n<=100
对于40%的数据,1<=n<=1000
对于100%的数据,
1
<
=
n
<
=
1
0
5
,
1
<
=
p
i
<
=
n
,
1
<
=
n
i
<
=
2
∗
1
0
4
1<=n<=10^5,1<=pi<=n,1<=ni<=2*10^4
1<=n<=105,1<=pi<=n,1<=ni<=2∗104
先放一波官方题解:
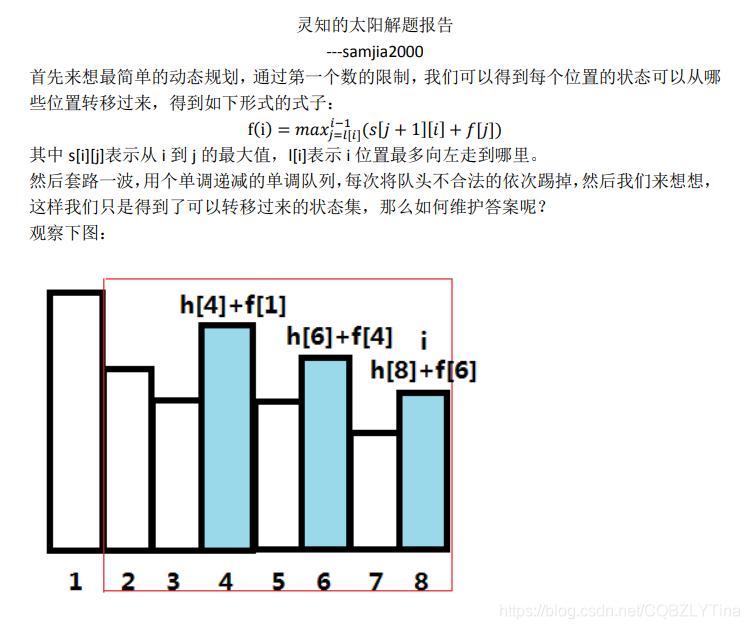

考场上其实连最简单的那个dp都没有想到,想的二维的状态,时间和空间都是
n
2
n^2
n2的,后来发现其实有一维无用状态。
然后最简单的那个
n
2
n^2
n2dp非常好理解对吧。
但是这样的转移时间复杂度非常高。(虽然我还码了一遍)
//
#include<queue>
#include<cstring>
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
#define N 100005
#define INF 0x3f3f3f3f
#define ll long long
struct node{
int a,b;
}at[N];
int n;
int last[N]/*这个点最左可以到哪里*/,pos[N]/*对应编号上一次出现的位置*/,dp[N];
inline int rd()
{
int f=1,x=0;char c=getchar();
while(c<'0'||'9'<c){if(c=='-')f=-1;c=getchar();}
while('0'<=c&&c<='9') x=(x<<3)+(x<<1)+(c^48),c=getchar();
return f*x;
}
int main()
{
freopen("array.in","r",stdin);
freopen("array.out","w",stdout);
n=rd();
for(register int i=1;i<=n;i++)
{
scanf("%d %d",&at[i].a,&at[i].b);
last[i]=last[i-1];
if(pos[at[i].a]) last[i]=max(last[i],pos[at[i].a]+1);
pos[at[i].a]=i;
}
for(register int i=1;i<=n;i++)
{
int mx=at[i].b;
dp[i]=dp[i-1]+at[i].b;
for(register int j=i-1;j>=last[i];j--)
{
mx=max(mx,at[j].b);
dp[i]=min(dp[i],dp[j-1]+mx);
}
}
printf("%d\n",dp[n]);
return 0;
}
然后发现转移后面那一坨
d
p
[
j
−
1
]
+
m
x
dp[j-1]+mx
dp[j−1]+mx的复杂度非常高,想到单调队列优化。
发现当右端点i固定左端点j向左扫时其间b的最大值mx是不减的
这就相当于在找到下一个更大值之前mx不会变
这里维护一个递减的单调队列表示从i向左扫到那些位置会使mx发生变化
由于dp是单调不减的,在mx不变时用最左边的dp一定是最小值
这就相当于在单调队列中的每一项的f加上下一位的mx
然后就可以单调队列优化一下。
但是看题解的意思,好像暴力(正常)维护单调队列会造成没有必要的入队,所以还要用其他数据结构维护?
蒟蒻没有看懂,不会写,所以写了一个正常(暴力)的单调队列,过了,541ms,虽然跑得不快,但是看起来也不像是卡过去的,所以就这样吧。。。
//单调队列优化dp
#include<queue>
#include<cstring>
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
#define N 100005
#define INF 0x3f3f3f3f
#define ll long long
inline int rd()
{
int f=1,x=0;char c=getchar();
while(c<'0'||'9'<c){if(c=='-')f=-1;c=getchar();}
while('0'<=c&&c<='9') x=(x<<3)+(x<<1)+(c^48),c=getchar();
return f*x;
}
int n;
int Q[N],head,tail;
int a[N],b[N],dp[N],pos[N],last[N];
int main()
{
freopen("array.in","r",stdin);
freopen("array.out","w",stdout);
n=rd();
for(int i=1;i<=n;i++)
{
a[i]=rd(),b[i]=rd();
if(!pos[a[i]])
pos[a[i]]=i,last[i]=0;
else last[i]=pos[a[i]],pos[a[i]]=i;
last[i]=max(last[i],last[i-1]);//不能越过上一个数不能到达的位置
}
head=tail=1;
Q[tail]=1;
dp[1]=b[1];
for(int i=2;i<=n;i++)
{
while(head<=tail&&last[i]>Q[head])
head++;
while(head<=tail&&b[Q[tail]]<=b[i])
tail--;
Q[++tail]=i;//先更新 可以从自己更新
dp[i]=INF;
for(int j=head+1;j<=tail;j++)
dp[i]=min(dp[i],dp[Q[j-1]]+b[Q[j]]);
dp[i]=min(dp[i],dp[last[i]]+b[Q[head]]);//单独处理队头
}
printf("%d\n",dp[n]);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号