
odoo中对多条数据按条件进行分类汇总 read_group的用法总结并抽取出公式
今天在工作中遇到一个这样的问题。要求:做一个打印模板实现下面图中的分类汇总
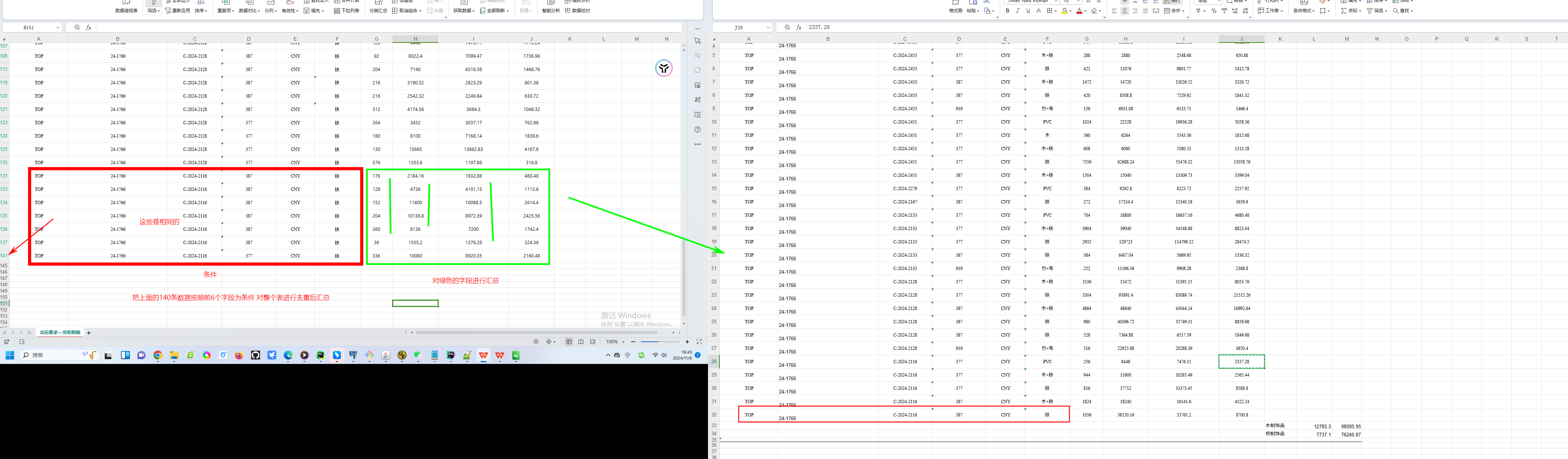
py3o://for="o in object.delivery_containers_line.read_group(domain=[('delivery_order_id','=',object.id)], fields=['customer_id', 'delivery_order_id', 'sales_order_id', 'supplier_id','purchase_currency','customer_material','outstock_qty:sum','outstock_purchase_amount:sum','outstock_purchase_utaamount:sum','outstock_sale_amount:sum'],groupby=['customer_id', 'delivery_order_id', 'sales_order_id', 'supplier_id','purchase_currency','customer_material'], lazy=False)"
我用的是odoo12中py3o的模板
下面来分析上面代码的作用
1. read_group 方法:
read_group 是 Odoo 的一个用于对模型数据进行分组和聚合的方法。它通常用于生成报表时需要对数据进行按字段分组的场景。
语法:
read_group(domain, fields, groupby, lazy=False)
参数解释:
domain: 查询的过滤条件。domain=[('delivery_order_id','=',object.id)]指定了只有与当前delivery_order_id匹配的记录才会被选中。fields: 需要返回的字段和汇总的字段。例如:'customer_id','delivery_order_id','sales_order_id', 等这些字段将按组进行分组。outstock_qty:sum,outstock_purchase_amount:sum等这些字段将在每组中进行汇总,汇总方法是sum。
groupby: 指定用于分组的字段。这里的数据会按照customer_id,delivery_order_id,sales_order_id, 等字段进行分组,意味着数据会被按这些字段的不同组合拆分。lazy=False: 指定是否使用懒加载,False代表一次性加载所有数据。
2. 字段汇总(聚合):
在 fields 中,字段后面加上 :sum 是 Odoo 提供的一种简便方式来进行汇总操作。例如:
outstock_qty:sum:表示对所有outstock_qty字段进行求和。outstock_purchase_amount:sum:表示对所有outstock_purchase_amount字段进行求和。
3. for="o in object.delivery_containers_line.read_group(...)":
这个 for 循环是用来遍历 read_group 返回的聚合数据结果。每一项 o 代表一个分组的结果对象。在这个对象中:
o['customer_id']:是分组依据的字段之一。o['outstock_qty:sum']:是该组所有outstock_qty字段的汇总值。
4. 模板中的数据展示:
模板中的数据展示逻辑会依赖于 read_group 返回的结果。比如,我们可以将汇总的字段显示在模板中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号