


Spring Cloud 经典面试题
一、谈谈Spring Cloud优缺点?
Spring Cloud 的优点是:集成度高、生态丰富、可扩展性强、功能全面。
Spring Cloud 的缺点是:学习曲线陡峭、有一定的性能开销、组件迭代快版本多、管理复杂。
- 集成度高:Spring Cloud 集成了多个成熟的微服务组件(如 Eureka、Zuul、Ribbon、Hystrix、Sleuth 等),与 Spring Boot 无缝结合,开发者可以快速上手并构建微服务架构。其组件化设计使得开发者可以根据需求选择合适的模块进行使用。
- 生态丰富:Spring Cloud 拥有一个庞大的开源生态系统和活跃的社区支持。无论是官方提供的组件还是社区扩展的库,都能够很好地满足不同的微服务需求。此外,Spring Cloud 还与 Kubernetes 等云原生技术紧密集成,适合云原生应用的开发和部署。
- 可扩展性强:Spring Cloud 提供了多种 SPI(Service Provider Interface)接口,开发者可以根据实际需求定制自己的服务发现、负载均衡和熔断策略,极大地增强了系统的灵活性和可扩展性。
- 功能全面:Spring Cloud 为微服务提供了全方位的支持,包括服务注册与发现(Eureka/Nacos)、负载均衡(Ribbon)、断路器(Hystrix/Resilience4j)、API 网关(Zuul/Spring Cloud Gateway)、链路追踪(Sleuth/Zipkin)等,减少了开发者选择和集成第三方组件的复杂性。
- 学习曲线陡峭:尽管 Spring Cloud 提供了丰富的功能,但其组件众多且配置较多,开发者需要掌握每个模块的配置和使用方式,对初学者来说,存在一定的学习难度。尤其是需要理解微服务架构的设计理念和各组件之间的交互。
- 性能开销:Spring Cloud 的部分组件(如 Zuul 1.x、Ribbon)在高并发场景下的性能表现一般,可能成为系统的瓶颈。此外,服务之间的调用通常是基于 HTTP 的 REST 调用,相较于传统的单体应用,网络开销和序列化/反序列化的性能开销会显著增加。
- 组件迭代快,管理复杂:Spring Cloud 的版本更新速度较快,且每个模块的版本管理有时不统一。开发者需要关注版本兼容性问题,不同版本之间的升级可能会引入兼容性问题,导致项目的升级和维护工作量较大。
二、怎么理解微服务?
微服务(Micreoservies)是一种软件架构风格,它的主要目的就是将一个复杂应用程序拆分成多个职责单一的服务。
微服务的核心思想是“单一职责原则”,即每个服务专注于完成一个特定的任务,确保服务的高内聚性和低耦合性。
这会使得开发、部署、维护更加灵活和高效。针对不同服务可以进行不同技术或者语言选型,比如机器学习可以用 Python、一些嵌入式可以用 c++、其他可以用 Java 或者 Go 等等。
服务之间的通信一般使用 RPC (远程调用),相比单体应用会带来网络的开销。
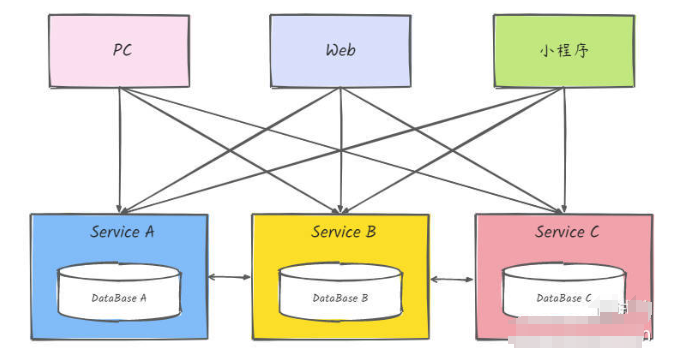
微服务的优点
- 独立部署:微服务可以独立部署,减少了系统整体部署的复杂度。如果某个服务需要更新或修复问题,只需重新部署该服务,而无需重新部署整个系统。
- 技术多样性:不同的微服务可以使用不同的技术栈(编程语言、数据库、框架等),根据各自的需求选择最合适的技术。
- 灵活扩展:微服务架构允许按需扩展特定的服务,而不需要扩展整个系统。例如,如果某个服务的负载较高,可以单独扩展该服务的实例数量。
- 容错性:如果一个微服务出现故障,通常不会影响整个系统的运行,其他服务依然可以正常工作。
微服务的典型技术栈
- 服务通信:使用 RESTful API、gRPC、消息队列(如 Kafka、RabbitMQ)等进行服务间通信。
- 服务发现与负载均衡:使用 Consul、Eureka、Zookeeper 等进行服务发现和负载均衡。
- 配置管理:使用 Spring Cloud Config、Consul 等工具进行配置管理,确保配置的一致性和动态性。
- API 网关:使用 API Gateway(如 Spring Cloud Gateway、Kong、Zuul)统一管理外部请求,提供路由、认证、限流等功能。
- 监控与日志管理:使用 Prometheus、Grafana、ELK(Elasticsearch, Logstash, Kibana)等工具对微服务进行监控和日志管理。
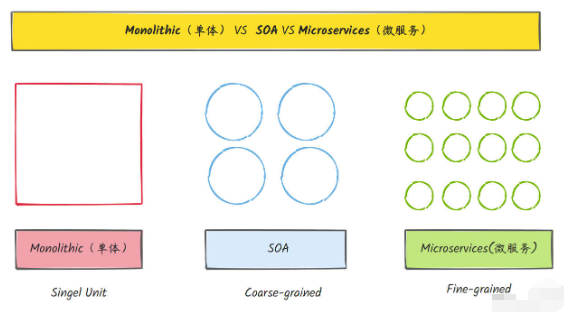
单体、SOA和微服务架构区别
单体应用:适合小型应用或初创项目,架构简单,但不易扩展和维护。
SOA:适合大型企业应用,强调服务复用和标准化,但引入了 ESB 的复杂性。
微服务架构:适合需要高扩展性、高可靠性和快速迭代的大型分布式应用,带来了管理和运维的复杂性。
分布式和微服务有什么区别?
分布式系统和微服务架构是两个相关但不同的概念,它们的注重点其实不太一样。
分布式系统是由多台计算机或多节点组成的系统,各节点之间通过网络进行通信和协作,共同完成一个或多个共享的任务。
也就是说分布式的各个节点其实目标是一致的,之所以要分布式只是为了有更好的能力,能更快、更高效地承接任务。
比如常见的分布式文件系统、分布式数据库。
微服务架构其实是一种服务的架构风格,它主要是为了把一个大而全的服务,拆分成多个可以独立、松耦合的服务单元,为了让这些服务单元可以独立部署、运行、管理。
比如电商服务拆分成微服务,可以分为商品服务、用户服务、订单服务、库存服务等等。
三、对DDD的了解?
DDD 全名叫做 Domain-driven design,即领域驱动设计,它是一种软件开发方法,其主要目的就是让开发人员和领域专家可以更好地协作,从而开发出满足业务需求的系统。
DDD 的关键概念包括领域模型和限界上下文。
- 领域模型描述了业务领域的规则和逻辑,让开发人员能够更好地理解业务需求。
- 限界上下文则定义了一个特定的业务领域内的模型和代码,使得其可以独立于其他上下文进行开发和维护。
除此之外,DDD 还强调分层架构和事件溯源的重要性。分层架构将系统划分为不同层次的结构,每个层次的职责和角色各有不同,从而方便业务代码的开发和维护。事件溯源则是一种存储和处理业务事件的技术,支持审计、合规和业务分析等需求。
总得来说,DDD 是一种设计和开发复杂软件系统的方法,一般情况下 MVC 已经能够完成许多软件业务的开发了,如果项目本身比较简单,引入 DDD 的话不仅不能降低开发成本,还会增加开发的复杂程度,所以 DDD 在使用之前需要一定的思考。
DDD 的核心概念:
领域:领域是一个业务问题所在的范围,即系统所要解决的核心业务问题。它是对系统所处业务环境的抽象和理解。
领域模型:领域模型是对领域的抽象表达,包括实体、值对象、聚合、聚合根、领域服务等概念,用于描述领域中的业务规则和业务逻辑。
Ubiquitous Language(统一语言):在 DDD 中,开发团队和业务专家需要通过统一的业务语言来进行沟通和协作。统一语言体现在领域模型中,并保持与代码一致,使得业务规则和代码实现可以无缝对接。
限界上下文(Bounded Context):限界上下文定义了一个领域模型的边界,即在哪些范围内这个模型是适用的。它帮助我们明确一个领域模型适用的范围,避免模型在不同上下文间的混用。不同的限界上下文之间通过防腐层进行隔离和集成。
DDD 的设计原则:
- 高内聚、低耦合:在 DDD 中,聚合的设计要遵循高内聚、低耦合的原则,使得聚合内部的对象关系紧密,而聚合之间的依赖尽量松散。这样设计能够提高系统的可维护性和扩展性。
- 领域驱动:业务逻辑的实现应当基于领域模型的设计,而非数据库模型。开发者需要将核心业务逻辑集中在领域模型中,而不是放在服务层或控制器中。
- 模块化:通过将领域分割为多个限界上下文,每个限界上下文成为一个独立的模块或微服务。这样可以更好地管理领域模型的复杂性,并方便系统的演进和扩展。
DDD 的构建模块:
- 实体(Entity):实体是具有唯一标识符的对象,其生命周期和身份是持久化的。例如,在订单系统中,订单实体具有唯一的订单号,它的状态可以随时间发生变化。
- 值对象(Value Object):值对象是不可变的、没有唯一标识的对象,它更关注对象的属性和值,而不是身份。值对象通常用于描述实体的某些属性,如地址、坐标等。
- 聚合(Aggregate):聚合是一个或多个实体和值对象的集合,它们围绕一个聚合根(Aggregate Root)进行管理。聚合根负责保证聚合内部的一致性,外部只能通过聚合根来访问聚合中的其他对象。
- 领域服务(Domain Service):当某些业务逻辑无法归属于某个实体或值对象时,可以放在领域服务中。领域服务是无状态的,并且只与领域逻辑相关。
- 工厂(Factory):工厂用于创建复杂对象和聚合,以确保对象在创建时满足业务规则。
- 仓储(Repository):仓储用于封装对聚合根的持久化操作,提供数据的存储和查询能力,从而将数据访问逻辑与业务逻辑解耦。
限界上下文与上下文映射:
- 限界上下文(Bounded Context):它定义了一个领域模型的适用范围,每个限界上下文可以独立演进,并且模型在不同上下文间不应混用。例如,"订单管理" 和 "库存管理" 是两个不同的限界上下文,它们各自有自己的领域模型。
- 上下文映射(Context Map):在大型系统中,多个限界上下文之间需要进行集成和通信。上下文映射描述了这些上下文之间的关系和集成方式,包括共享内核、反腐层、客户-供应者模式等。
四、什么情况下需要使用分布式事务,有哪些方案?
一般在跨多个数据库、或者不同服务的情况下需要用到分布式事务,比如订单服务和库存服务,下订单和扣库存属于不同服务的方法,因此本地事务无法保证一致性,需要引入分布式服务。
分布式事务是由多个本地事务组成的,分布式事务跨越了多设备,之间又经历的复杂的网络,可想而知想要实现严格的事务道路阻且长。
常见的分布式事务方案:
- 2PC:基于两阶段提交(2PC,Two-Phase Commit)的分布式事务协议。协调者(Transaction Manager)管理全局事务,所有参与的资源管理器(如数据库)在第一阶段准备事务,在第二阶段提交事务。
- 3PC:3PC 也就是多了一个阶段,一个询问的阶段,分别是准备、预提交和提交这三个阶段。它的引入是为了解决 2PC 同步阻塞和减少数据不一致的情况。
- TCC:将事务操作拆分为 Try、Confirm、Cancel 三个步骤。Try 阶段是预留资源,Confirm 阶段是实际提交,Cancel 阶段是回滚操作。每个步骤都需要由业务自己实现。
- 本地消息:将每个参与的子事务设计为独立的本地事务,通过对状态表进行记录,并采用定时任务或回调机制来检查和补偿,确保最终一致性
- 事务消息:通过消息中间件(如 RocketMQ)将业务操作和消息发送绑定在一起,确保消息发送和业务操作的原子性。接收方在处理消息时,保证消息的消费与业务操作一致


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!