
爬虫综合大作业
爬虫综合大作业
作业要求来自于:
一.把爬取的内容保存取MySQL数据库
import pandas as pd
import pymysql
from sqlalchemy import create_engine
conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
engine = create_engine(conInfo,encoding='utf-8')
df = pd.DataFrame(allnews)
df.to_sql(name = 'news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
选择一个热点或者你感兴趣的主题。
选择爬取的对象与范围。
了解爬取对象的限制与约束。
爬取相应内容。
做数据分析与文本分析。
形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
文章公开发布。
三.爬虫注意事项
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
import time
import random
time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
首先打开你的浏览器输入:about:version。
用户代理:
收集一些比较常用的浏览器的user-agent放到列表里面。
然后import random,使用随机获取一个user-agent
定义请求头字典headers={'User-Agen':}
发送request.get时,带上自定义了User-Agen的headers
3.需要登录
发送request.get时,带上自定义了Cookie的headers
headers={'User-Agen':
'Cookie': }
4.使用代理IP
通过更换IP来达到不断高 效爬取数据的目的。
headers = {
"User-Agent": "",
}
proxies = {
"http": " ",
"https": " ",
}
response = requests.get(url, headers=headers, proxies=proxies)
正文:
一、爬取的网站:中国传媒大学南广学院
爬取范围:中国传媒大学南广学院的新闻
爬取要求:对新闻信息进行词云分析,新闻时间与事件点击量排序,词频统计。
二、详细爬取过程:
1.首先需要对每个新闻页面信息的爬取:alist
代码如下:
def alist(url): ''' 获取页面的各种新闻,然后逐条进入 :param url: listUrl :return: newsList ''' res=requests.get(listUrl) res.encoding='utf-8' soup = BeautifulSoup(res.text,'html.parser') newsList=[] for news in soup.select('li'):#获取li元素 if len(news.select('.text-list'))>0:#如果存在新闻题目 newsUrl = news.select('a')[0]['href']#获取新闻的链接 newsDesc = news.select('span')[0].text#获取时间 newsDict = anews(newsUrl)#通过进入链接获取详细信息 newsDict['time'] = newsDesc newsList.append(newsDict)#把每个新闻的信息放进字典扩展到列表里 return newsList
2.然后再获取新闻页面的url进入新闻详细页面,对新闻详细页面信息的爬取:anews
代码如下:
def anews(url): ''' 进入后爬取主要内容 :param url: url :return: newsDetail ''' newsDetail = {} res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') newsDetail['newsTitle'] = soup.select('.zw-title h2')[0].text#题目 newsDetail['newsClick'] = soup.select('.liulan')[0].text # 点击次数 a = len(soup.select('.zw-text p'))#获取存放内容的p标签 c = ""#后面用来进行每个p标签的内容相加 for i in range(0,a):#获取每个p标签的文本内容 if soup.select('.zw-text p')[i].text != "\n\n":#剔除空内容 b = ( soup.select('.zw-text p')[i].text) c = c+b#文本内容衔接 newsDetail['newstext'] = c#将文本内容放进字典 return newsDetail
3.对新闻新信息进行简单数据处理:更新时间与点击量的排序
代码如下:
newsdf = pd.DataFrame(allnews) print(newsdf) print(newsdf.sort_values(by=['time'],ascending=False))#按更新时间降序排列 print(newsdf.sort_values(by=['newsClick'],ascending=False))#按点击量降序排列
4.对新闻文本信息进行数据清洗
代码如下:
# 加载停用词表 stopwords = [line.strip() for line in open('stops_chinese1.txt', encoding='utf-8').readlines()] # 分词 zhuanhua = str(allnews)#将字典转化为string格式 wordsls = jieba.lcut(zhuanhua) wcdict = {} for word in wordsls: # 不在停用词表中 if word not in stopwords: # 不统计字数为一的词 if len(word) == 1: continue else: wcdict[word] = wcdict.get(word, 0) + 1
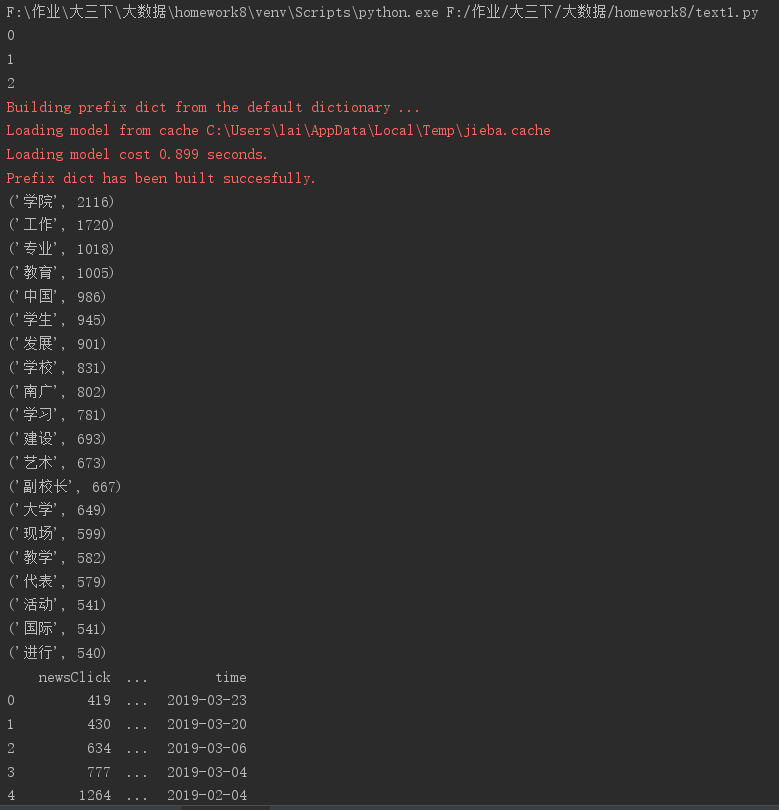
5.对文本信息进行词频排序:
代码如下:
wcls=list(wcdict.items()) wcls.sort(key=lambda x:x[1],reverse=True) #输出词频最大TOP20 for i in range(20): print(wcls[i])
6. 生成词云
代码如下:
cut_text = " ".join(wcdict)#join返回通过指定字符连接序列中元素后生成的新字符串 mywc = WordCloud(font_path = 'msyh.ttc').generate(cut_text) plt.imshow(mywc) plt.axis("off") plt.show()
7. 设置合理的爬取间隔
代码如下:
for i in range(3): print(i) time.sleep(random.random()*3)#沉睡随机数的3倍秒数
8. 保存到csv与sql文件
代码如下:
newsdf.to_csv(r'F:\作业\大三下\大数据\homework8\cucn.csv',encoding='utf_8_sig')#保存成csv格式,为避免乱码,设置编码格式为utf_8_sig with sqlite3.connect(r'F:\作业\大三下\大数据\homework8\cucnsql.sqlite') as db:#保存文件为sql newsdf.to_sql('gzccnewsdb',db)
三、运行截图:


词云生成如下图所示:

保存成csv文件截图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号