
复合数据类型,英文词频统计
复合数据类型,英文词频统计
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
一、列表,元组,字典,集合的增删改查及遍历
1.列表
(1)增:


1 dict={'tom':1,'ben':5,'amy':3,'jack':7,'yang':6,'wang':9} 2 dict['li']=8 3 print(dict)
运行截图:

(2)删除:
1 dict={'tom':1,'ben':5,'amy':3,'jack':7,'yang':6,'wang':9} 2 del dict['ben'] 3 print(dict)
运行截图:

(3)修改:
1 dict={'tom':1,'ben':5,'amy':3,'jack':7,'yang':6,'wang':9} 2 dict['ben']=8 3 print(dict)
运行截图:

(4)查找:
1 dict={'tom':1,'ben':5,'amy':3,'jack':7,'yang':6,'wang':9} 2 print(dict['ben'])
运行截图:

(5)遍历:
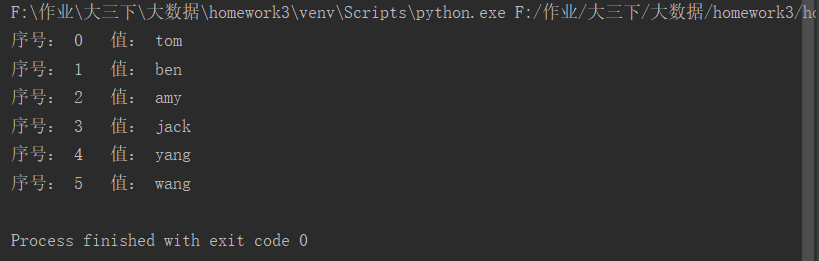
list=['tom','ben','amy','jack','yang','wang'] for i in range(len(list)): print("序号:", i, " 值:", list[i])
运行截图:
2.元组
(1)增:
tup1=('tom','ben','amy','jack','yang','wang') tup2=('tang','hong') tup=tup1+tup2 print(tup)
运行截图:

(2)删除:
tup=('tom','ben','amy','jack','yang','wang') print(tup) del tup print(tup)
运行截图:

(3)修改:
tup=('tom','ben','amy','jack','yang','wang') tup=list(tup) tup[0]='张四' tup[1]='Jacky' tup=tuple(tup) print(tup)
运行截图:

(4)查找:
tup=('tom','ben','amy','jack','yang','wang') print(tup[2])
运行截图:

(5)遍历:
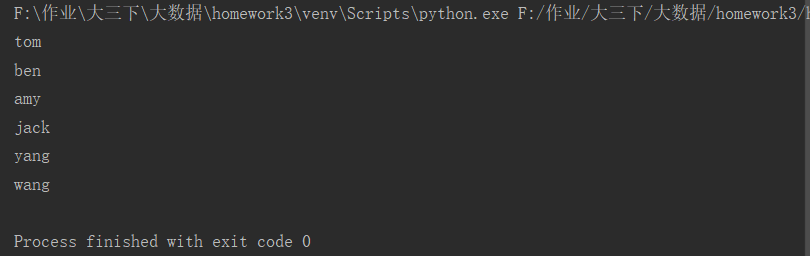
tup=('tom','ben','amy','jack','yang','wang') for x in (tup): print(x)
运行截图:
3.字典
(1)增:
zeng2 运行截图:

(2)删除:
shanchu2
运行截图:
(3)修改:
xiugai2
运行截图:
(4)查找:
查找2
运行截图:
(5)遍历:
bianli2
运行截图:
4.集合
(1)增:
1 s=set(['tom','ben','amy','jack','yang','wang']) 2 s.add('meng') 3 print(s)
运行截图:

(2)删除:
1 s=set(['tom','ben','amy','jack','yang','wang']) 2 s.remove('ben') 3 print(s)
运行截图:

(3)修改:
1 s=set(['tom','ben','amy','jack','yang','wang']) 2 s=list(s) 3 s[2]='li' 4 s=set(s) 5 print(s)
运行截图:

(4)遍历:
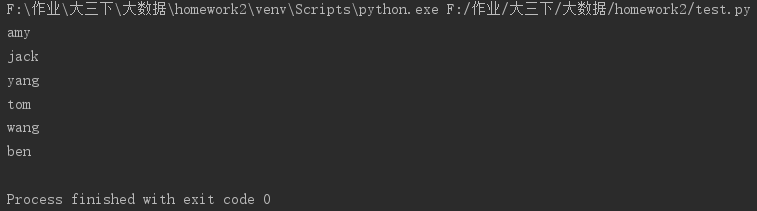
1 s=set(['tom','ben','amy','jack','yang','wang']) 2 for x in s: 3 print(x)
运行截图:
二、总结列表,元组,字典,集合的联系与区别。
1.列表
(1)括号【中括号】
(2)有序无序【有序】
(3)可变不可变【可变】
(4)重复不可重复【可重复】
(5)存储与查找方式【存储时每一个元素被标识一个索引,程序只需处理对象的操作】
2.元组
(1)括号【小括号】
(2)有序无序【有序】
(3)可变不可变【不可变】
(4)重复不可重复【可重复】
(5)存储与查找方式【同列表】
3.字典
(1)括号【大括号】
(2)有序无序【无序】
(3)可变不可变【因为是无序,故不能进行序列操作,但可以在远处修改,通过键映射到值】
(4)重复不可重复【不可重复】
(5)存储与查找方式【和列表一样】
4.集合
(1)括号【小括号】
(2)有序无序【无序】
(3)可变不可变【可变】
(4)重复不可重复【不可重复】
(5)存储与查找方式【和列表一样】
三、词频统计
源代码如下:
# 读取文件 f = open("lem.txt","r") text = f.read() f.close() # 转为小写 text = text.lower() # 将所有其他做分隔符(,.?!)替换为空格 text = text.replace(","," ").replace("."," ").replace("?"," ").replace("!"," ") # 分割为单词 text = text.split() setText = set(text) exclude = {'a','the','and','i','you','in','but','not','with','by','its','for','of','an','to'} setText = setText-exclude # 转为字典 textDict = {} for word in setText: textDict[word] = text.count(word) # 转为列表 word = list(textDict.items()) word.sort(key = lambda x:x[1],reverse=True) print(word[:20]) # 生成excel import pandas as pd pd.DataFrame(data=word).to_csv('lem.csv',encoding='utf-8')
词云如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号