

08 分布式计算MapReduce--词频统计
1.用你最熟悉的编程环境,编写非分布式的词频统计程序。
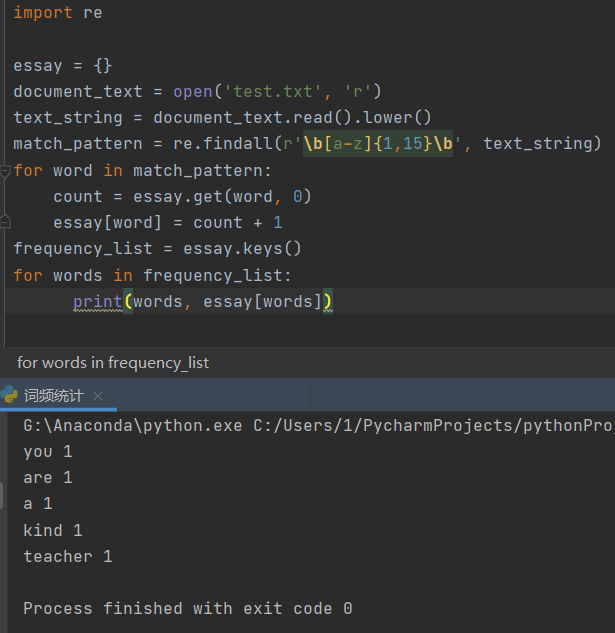
在Ubuntu中实现运行。
- 准备txt文件
- 编写py文件
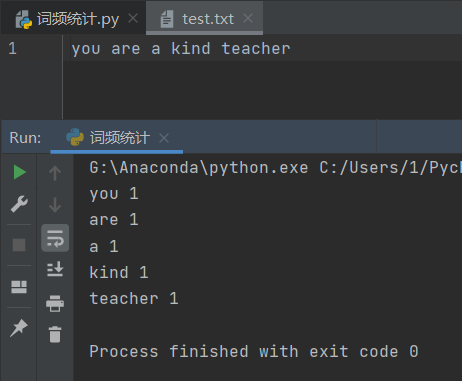
- python3运行py文件分析txt文件。
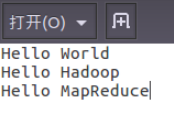
①txt文件

②py文件

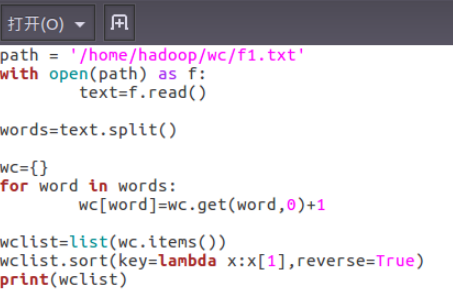
③python3运行py文件

2.用MapReduce实现词频统计
2.1编写Map函数
- 编写mapper.py
- 授予可运行权限
- 本地测试mapper.py
①编写mapper.py
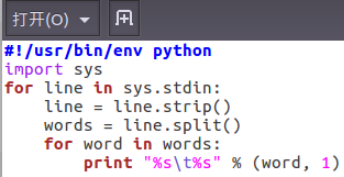
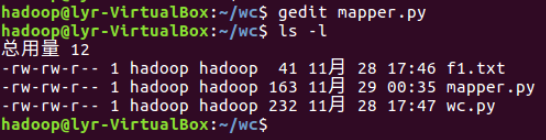
②授予可运行权限

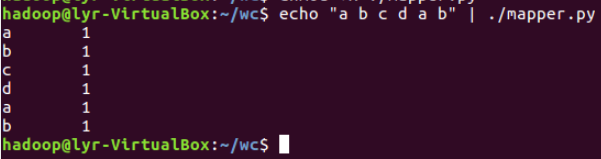
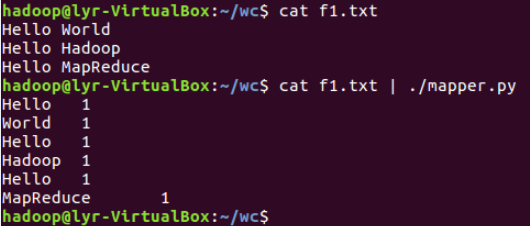
③本次测试mapper.py
2.2编写Reduce函数
- 编写reducer.py
- 授予可运行权限
- 本地测试reducer.py
①编写reducer.py

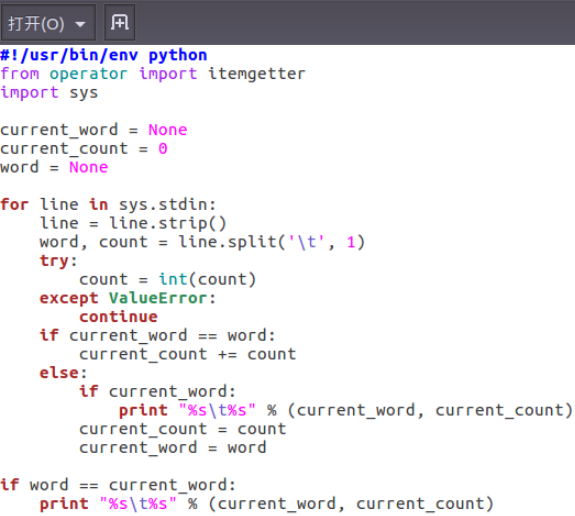
②授予可运行权限

③本地测试reducer.py
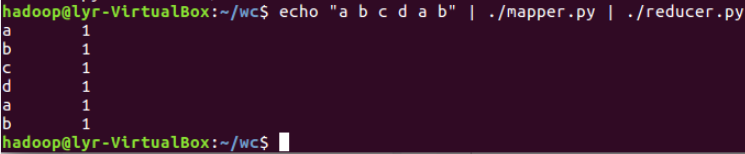


2.3分布式运行自带词频统计示例
- 启动HDFS与YARN
- 准备待处理文件,上传到HDFS上
- 运行实例hadoop-mapreduce-examples-2.7.1.jar
- 查看结果
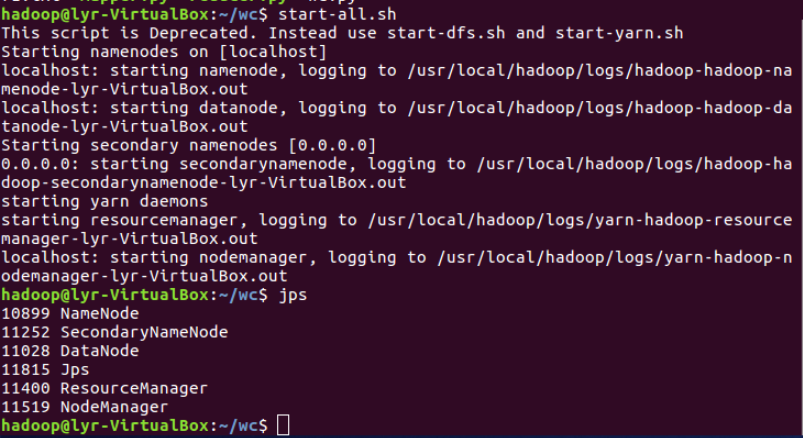
①启动HDFS与YARN
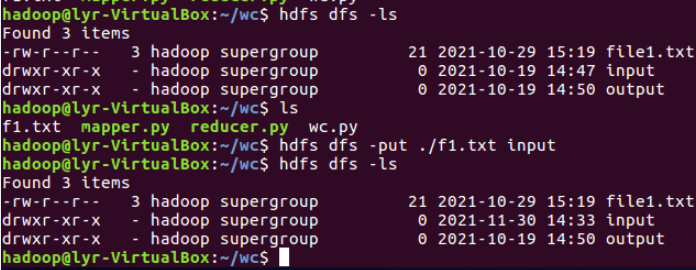
②准备待处理文件,上传到HDFS上
③运行实例hadoop-mapreduce-examples-2.7.1.jar
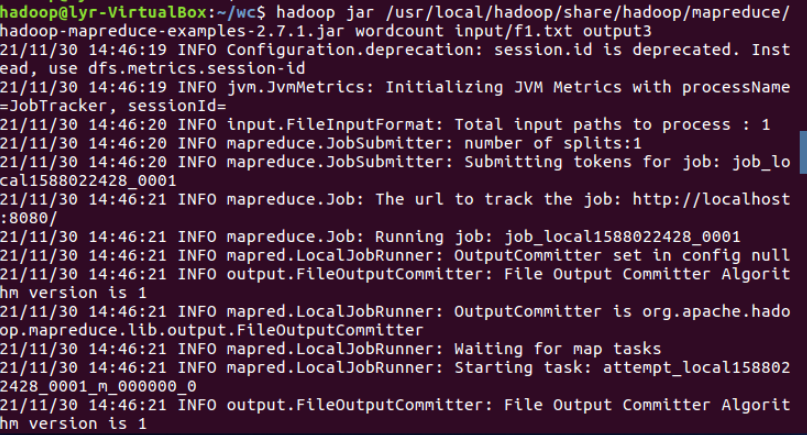
④查看结果
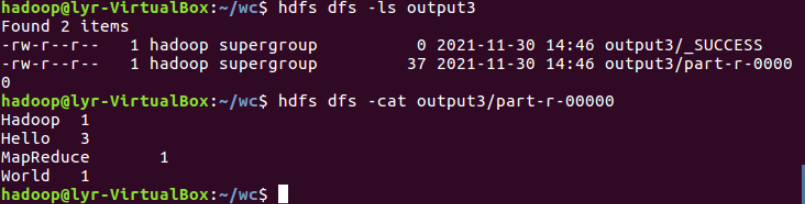
2.4 分布式运行自写的词频统计
- 用Streaming提交MapReduce任务:
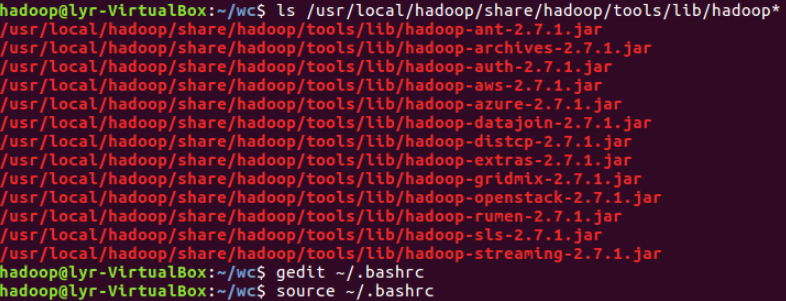
- 查看hadoop-streaming的jar文件位置:/usr/local/hadoop/share/hadoop/tools/lib/
- 配置stream环境变量
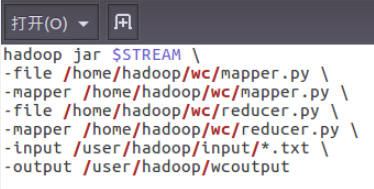
- 编写运行文件run.sh
- 运行run.sh运行
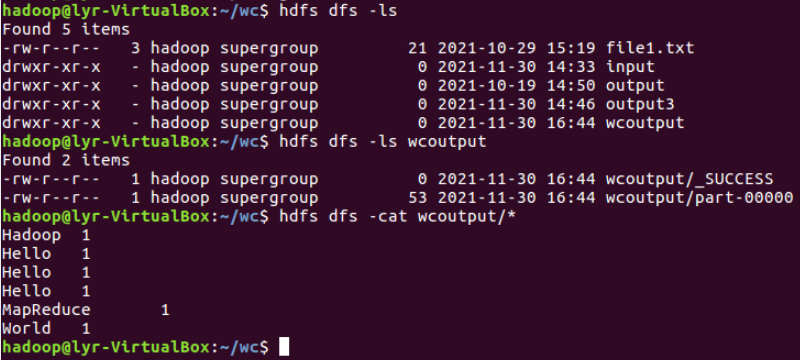
- 查看运行结果
- 停止HDFS与YARN
①查看hadoop-streaming的jar文件位置:/usr/local/hadoop/share/hadoop/tools/lib/,配置stream环境变量
②编写运行文件run.sh
③运行run.sh运行
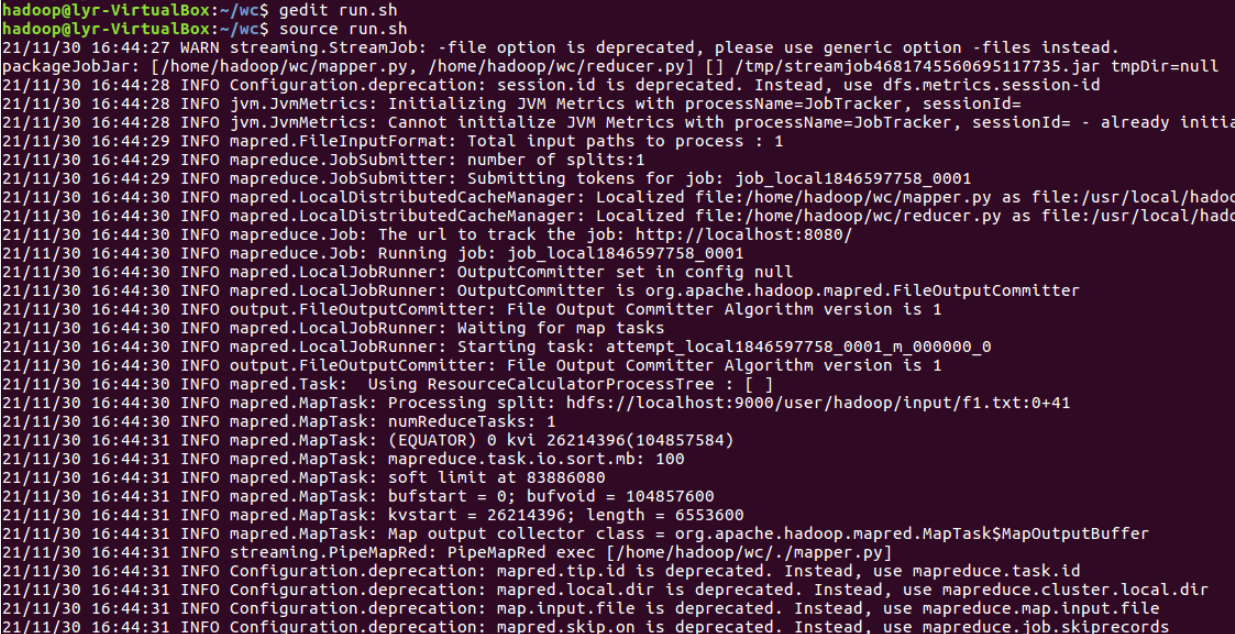
④查看运行结果
⑤停止HDFS与YARN



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库