NetCloud——一个网易云音乐评论抓取和分析的Python库
在17的四月份,我曾经写了一篇关于网易云音乐爬虫的文章,还写了一篇关于评论数据可视化的文章。在这大半年的时间里,有时会有一些朋友给我发私信询问一些关于代码方面的问题。所以我最近抽空干脆将原来的代码整理了一下,做成了一个Python模块NetCloud放在Pypi上了。目前只是对原来的代码做了一些整理与重构,功能还很不完善,后续打算抽空继续完善,如果有人用的话可能会长期维护下去。
目前只需要使用命令pip install NetCloud 即可以完成模块的安装,支持Windows与Linux系统,以前代码是基于python2的,现在支持Python3(我简单测试了一下python3.6应该也没问题了),python2下运行应该也基本没问题,但是考虑到编码问题,以及Python社区即将在2020年不再支持2.x的版本,所以强烈建议使用Python3.x运行模块。代码github的地址是Netcloud
关于实现功能以及一些主要接口的说明:
1.主要实现了:
- 对于一首歌曲全部评论的抓取,保存为csv文件格式
- 对于一个歌手全部热门评论的抓取,存为csv文件
- 对于一首歌曲下全部评论用户基本信息的抓取,包括:用户主页url,用户年龄,听歌次数,动态次数,用户所在地区,用户动态总数等,这些信息也存为csv文件格式
- 利用全部评论以及热门评论分词生成词云,统计关键词的频率
- 利用一首歌曲全部评论用户的信息,基于pyecharts可视化,包括:用户所在地区分布使用geo表示(地图),用户年龄的分布,用户听歌数目的分布,用户动态的数目分布,歌曲评论数量关于时间的分布等等。以前是基于matplotlib来做的,但是只能生成静态的图片,而pyecharts可以产生基于网页的交互式的显示效果,我感觉效果可能会更好一点。
- 以前抓取是单线程的,效率较低,现在支持多线程了,可以极大地提高抓取效率
2.还需要去完善的(Todolist)
- 如何很好的应对反爬。我实验发现,在开启多线程的情况下,抓取一段时间服务器可能会限制抓取(封ip),目前应对的措施主要是开启代理ip,不过如何找到较高质量的代理ip地址,就只能自己去想办法了
-目前还不支持模拟登录网易云音乐,查看个人信息,听歌记录等,不过Python里应该已经有其他模块做到了这一点,而且这个应该也不是特别难,后面有空会加上。
-目前还不支持对于歌单的批量抓取,以及获取用户听歌的详细记录,后续考虑增加。如果有这部分数据,可以深挖更多东西,比如预测用户听歌风格,对用户按听歌洗喜好分类,以及做推荐等等。
-目前的分析仅限于简单的分析统计等等,后续考虑加入更深入的NLP分析。
3.安装以及主要的函数接口
- 安装很简单,只需要 pip install NetCloud,因为模块以来于一些第三方库,所以在安装这些第三方库的时候可能会出现问题,可以参考4的说明
- 快速使用,一个简单的例子如下:
from NetCloud.NetCloudCrawler import NetCloudCrawl
from NetCloud.NetCloudAnalyse import NetCloudAnalyse
if __name__ == '__main__':
song_name = "敢爱"
song_id = 186888
singer_name = "张国荣"
singer_id = 6457
crawler = NetCloudCrawl(song_name,song_id,singer_name,singer_id)
crawler.generate_all_necessary_files(threads=10)
analyse = NetCloudAnalyse(song_name,singer_name,song_id,singer_id)
analyse.generate_all_analyse_files(threads=20)
3.1 上面的10行左右的代码就完成了对于张国荣的《敢爱》这首歌的全部评论的抓取,张国荣歌曲热门评论的抓取,以及歌曲用户基本信息的抓取,并生成了相应的词云图片,以及一些基本的可视化分析。产生的文件结构如下图所示:
首先生成文件全部都会在songs这个文件夹下,然后对于每一首歌曲会产生以歌手名字命名的文件夹,然后是歌曲名字的文件夹,最后是相应的抓取文件,比如敢爱.csv就是《敢爱》的全部评论文件,敢爱.jpg就是歌曲评论的词云图片,hot_comments.csv是歌手的热门评论文件,最后所有的可视化结果都存放在plots文件夹下,可视化文件为html文件需要在浏览器打开查看可视化结果。
3.2 模块主要是两个类,一个是NetCloudCrawl,用于数据抓取;另一个是 NetCloudAnalyse用于数据的分析。NetCloudCrawl 的 generate_all_necessary_files函数会生成必要的全部评论文件,热门评论文件,支持多线程,默认是开启10个线程抓取。NetCloudAnalyse的 generate_all_analyse_files 顾名思义会产生全部的可视化文件,首先它会抓取用户的全部信息存入文件,然后产生一系列的可视化分析文件(html格式),最后会产生评论的词云文件。基本上调用这两个函数就可以轻松使用NetCloud的主要功能了。
3.3 如果你想自定义抓取,或者不想使用提供的可视化函数接口,也可以使用模块的其他基本函数完成抓取和分析,模块的主要函数接口调用格式说明如下:
NetCloudCrawl类
- AES_encrypt(text,key,iv) 这个函数用于网易云API的解密,基本用不到,不用管
- get_params(page) 获得必要的解密参数
- get_all_comments() 获取全部评论
- get_hot_comments() 获取热门评论
- get_json(url,params, encSecKey) 获取网易API json文件
- threading_save_all_comments_to_file(threads = 10) 使用多线程将全部评论文件存入文件,默认是10个线程
- save_pages_comments(begin_page,end_page) 将 begin_page到end_page页的评论存入文件,主要是供 threading_save_all_comments_to_file 函数调用
- save_to_file(comments_list,filename) 将评论信息列表 comments_list 存入filename 文件
- save_all_comments_to_file() 单线程按顺序保存全部评论文件
- get_singer_hot_songs_ids(singer_url) 得到歌手全部热门歌曲id列表,singer_url为歌手信息页url
- save_singer_all_hot_comments_to_file() 将歌手的全部热门评论存入文件
- generate_all_necessary_files(threads = 10) 生成全部必要的文件,包括歌手的全部热门评论文件,以及歌曲的全部评论文件
- _test 开头的均为测试函数,请不要调用
NetCloudAnalyse类
- load_comments_csv() 加载全部评论文件为dataframe格式(pandas)
- save_users_info_to_file() 保存歌曲评论下全部用户(已去重)的信息到文件(单线程)
- threading_save_users_info_to_file(threads = 10) 采用多线程保存用户信息到文件,默认是10个线程
- save_users_info(users_url,total) 供 threading_save_users_info_to_file调用的中间函数,不用管
- count_comments_lines() 统计全部评论文件的行数
- from_timestamp_to_date(time_stamp,format = "%Y-%m-%d %H:%M:%S") 将时间戳转日期的函数,默认格式是: 年-月-日 时:分:秒
- load_users_url() 返回全部评论用户主页url列表,用于后续用户信息抓取
- load_users_info_csv() 从用户信息csv文件加载用户信息dataframe
- draw_wordcloud(full_comments = True) 绘制评论关键词的词云,full_comments = True 表示绘制 全部评论,False 表示绘制热门评论
- core_visual_analyse() 核心的对于评论用户信息的可视化分析,产生的html文件有12个,说明如下:
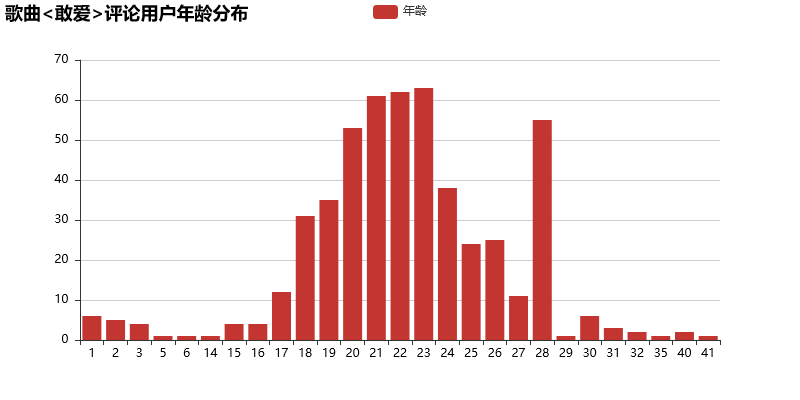
1. age_count_bar.html 年龄分布(bar 为 柱状图表示,下同)
2. agree_count_bar.html 赞同数分布
3. comments_keywords_bar.html 评论关键字分布(已去除停用词)
4. comments_year_month_bar.html 评论数量按年月的分布
5. comments_year_month_day_bar.html 评论数量按年月日的分布
6. description_keywords_bar.html 用户简介关键词分布
7. events_count_bar.html 用户动态数目分布
8. fans_count_bar.html 用户粉丝数量分布
9. follow_count_bar.html 用户关注者数量分布
10. listening_songs_count_bar.html 用户听歌数量分布
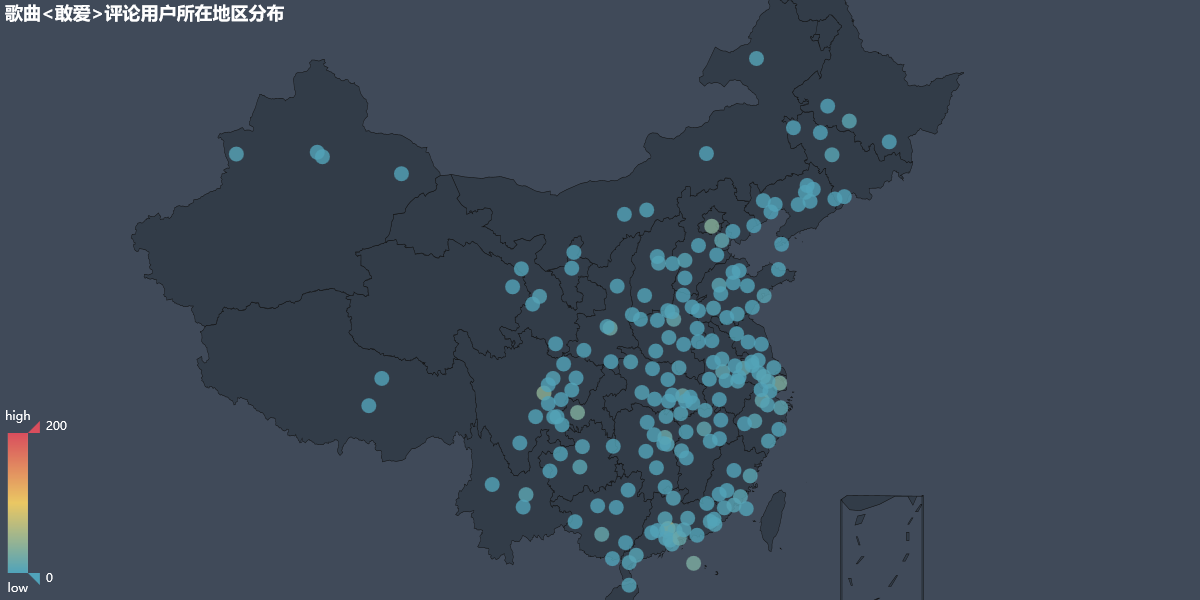
11. users_city_geo.html 用户所在地区分布,使用地图可视化表示
12. users_location_bar.html 用户所在地区分布,使用柱状图表示
一些可视化实际的效果图如下:
- load_stopwords() 加载停用词列表
- load_all_cities() 加载中国全部城市名称列表
- generate_all_analyse_files(threads = 10) 生成全部的分析文件,包括评论关键字词云以及评论用户信息的可视化,默认线程数为10
- _test 开头的为测试文件,请不要调用
--------------------------------------------更新(2018/03/17,新增NetCloudLogin类)------------------------------------------------
- 初始化,NetCloudLogin(phone,password,email = None,rememberLogin = True) 初始化必要的参数有两个,phone表示传入登录的电话号码,password表示密码,也可以使用email登录,但是不保证一定可以登录成功,建议使用
电话号码登录,rememberLogin = True表示记住登录状态
- login()函数,用于登录,返回一个Response object,这个Response 对象主要有:
1. content 属性,返回响应内容
2. heders属性,返回响应的headers
3. status_code属性,返回响应的状态码,比如200表示ok,404代表表示无法找到文件,400表示无效请求等等
4.ok属性,是一个布尔值,表示返回状态是否正常
5.error属性,返回的错误信息,如果没有异常,值为None
6.json()方法,解析返回的内容为json格式
- get_user_play_list(uid,offset=0,limit=1000):获取用户的播放歌单,uid 为用户id,offset表示开始位置,limit表示限制条数(下面的offset和limit参数含义相同,不再赘述),返回Response对象,可以使用json()方法解析
- get_self_play_list(offset=0,limit=1000):获取自己的播放歌单,返回Response对象
- get_user_dj(uid, offset=0, limit=30):获取用户的dj信息,返回Response对象
- get_self_dj(offset=0, limit=30): 获取自己的dj,返回Response对象
- search(keyword,type_=1, offset=0, limit=30):搜索歌手,歌曲,用户或者歌单,keyword表示搜索的关键字,type_表示搜索的类型,1:表示歌曲,100:表示歌手,1000表示歌单,1002表示用户,返回Response对象
- get_user_follows(uid, offset=0, limit=30):获取用户关注列表,返回Response对象
- get_self_follows(offset=0, limit=30):获取自身关注列表,返回Response对象
- get_user_fans(uid, offset=0, limit=30):获取用户粉丝列表,返回Response对象
- get_self_fans(offset=0, limit=30):获取自身粉丝列表,返回Response对象
- get_user_event(uid):获取用户动态,uid为用户id,返回Response对象
- get_self_event(): 获取自身动态
- get_user_record(uid, type_=0):获取用户播放记录,uid为用户id,type_取值可以为0或者1,0表示全部记录,1表示最近一周的记录(这个需要首先登录)
- get_self_record(type_ = 0):获取自身的播放记录
- get_friends_event():获取关注的人的动态,返回Response对象
- get_top_playlist_highquality(cat='全部', offset=0, limit=20):获取高质量的歌单,cat表示类别,可以传入'全部','欧美','华语'等,返回Response对象
- get_play_list_detail(id, limit=20):获取歌单的详细信息,id表示歌单id,返回Response对象
- get_music_download_url(ids=[]):通过id获取音乐的下载链接,传入的为歌曲的id列表,返回对应歌曲的下载链接Response对象
- get_lyric(id):通过歌曲id获取歌曲歌词,返回Response对象
- get_music_comments(id, offset=0, limit=20):通过歌曲id获取歌曲评论信息,返回Response对象
- get_album_comments(id, offset=0, limit=20):通过专辑id获取专辑评论信息,返回Response对象
- get_songs_detail(ids):通过歌曲id列表获取歌曲详细信息,ids表示歌曲id列表,返回Response对象
- get_self_fm():获得自身的私人fm信息,返回Response对象
pretty_ 开头的系列函数可以以友好的形式向屏幕打印出你需要的信息
- pretty_print_self_info(): 打印自身信息
- pretty_print_user_play_list(uid,offset = 0,limit = 1000):打印用户的歌单信息
- pretty_print_self_play_list(offset = 0,limit = 1000): 打印自身的歌单信息
- pretty_print_search_song(search_song_name,offset = 0,limit = 30):打印搜索歌曲的返回结果,search_song_name为搜索的歌曲关键字
- pretty_print_search_singer(search_singer_name,offset = 0,limit = 30):打印搜索歌手的返回结果,search_singer_name为搜索的歌手关键字
- pretty_print_search_play_list(keyword,offset = 0,limit = 30):打印搜索歌单的返回结果,keyword为搜索的歌单关键字
- pretty_print_search_user(keyword,offset = 0,limit = 30):打印搜索用户的返回结果,keyword为搜索的用户关键字
- pretty_print_user_follows(uid,offset = 0,limit = 30):打印用户关注列表
- pretty_print_user_fans(uid,offset = 0,limit = 30):打印用户粉丝列表
- pretty_print_self_fans(offset = 0,limit = 30):打印自身粉丝列表
- get_download_urls_by_ids(ids_list):通过传入歌曲id列表得到歌曲下载链接列表,ids_list为歌曲id列表,返回歌曲下载链接列表
- get_songs_name_list_by_ids_list(ids_list):通过歌曲id列表得到歌曲名字列表
- download_play_list_songs(play_list_id,save_root_dir = "."):下载歌单中的歌曲到本地,play_list_id为传入歌单id,save_root_dir为歌曲保存的根目录,默认为当前目录
- get_singer_id_by_name(singer_name):通过歌手名字得到歌手id,singer_name为歌手名字
- get_song_id_by_name(song_name):通过歌曲名字得到歌曲id,song_name为歌曲名字
- get_lyrics_list_by_id(song_id):通过歌曲id得到歌词列表
- get_lyrics_list_by_name(song_name):通过歌曲名字得到歌词列表
- download_singer_hot_songs_by_name(singer_name,save_root_dir = "."):通过传入歌手名字,下载歌手的热门歌曲到本地,singer_name为歌手名字,save_root_dir为歌曲保存的根目录,默认为当前目录
_test 开头的为测试函数,请不要调用。
一个简单的使用例子如下:
from NetCloud.NetCloudLogin import NetCloudLogin
phone = 'xxxxxxxxxxx'
password = 'xxx'
email = None
rememberLogin = True
login = NetCloudLogin(phone = phone,password = password,email = email,rememberLogin = rememberLogin)
login.pretty_print_self_info()
得到结果为:
Hello,Lyrichu!
Here is your personal info:
avatarUrl:http://p1.music.126.net/OkEDo-a_rHCC1zEDbg7dYg==/8003345140341032.jpg
signature:热爱生活,热爱音乐!
nickname:Lyrichu
userName:0_mxxxxxxxxxxx@163.com
province_id:420000
birthday:1995-02-12
description:
gender:male
userId:xxxxxxxx
cellphone:xxxxxxxxxxx
email:xxxxxxxxxxx@163.com
4. 一些可能会出现的问题
4.1 在pip install NetCloud 的过程中,如果是在Windows下,wordcloud 以及 pycrypto 模块也许会安装失败,此时可以去[python非官方第三方库下载](https://www.lfd.uci.edu/~go hlke/pythonlibs/)下载对应pyhton版本的预编译wheel文件,然后手动pip安装即可。另外,numpy 需要 numpy+mkl形式的库,也可以在这个网站下载。
4.2 由于我没有测试完全,而且代码水平有限,因此代码肯定存在一些意想不到的bug,如果您对这个模块感兴趣,在使用的过程中出现任何问题或者有任何建议,欢迎给我留言,当然最好的方式是去github提issue,地址是NetCloud,同时欢迎star 和fork,谢谢支持。
热爱编程,热爱机器学习!
github:http://www.github.com/Lyrichu
github blog:http://Lyrichu.github.io
个人博客站点:http://www.movieb2b.com(不再维护)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号