
网易云音乐评论 可视化分析
之前已经用python获取了网易云音乐的评论数据,下一步的工作就是数据分析了。一般数据分析无非是采用(统计)数字、图或者表的形式来展现数据之中隐含的信息。其中图和表显然是最直观的了。所以这里我使用可视化的方法即用图形来展示从评论中挖掘到的各种信息。
可视化的工具有很多,比如常见的有excel还有一些专门的绘图软件,各个编程语言当然也有很多可视化的包或者库,比如统计上使用很多的R语言就有很多可视化的库,我最喜欢的就是ggplot2了,我使用R语言主要用于数据的清洗以及可视化,其丰富的包(package)大大简化了数据分析的工作量,而且可以绘制非常复杂、精美的图表,以后有机会可以给大家专门介绍一下。python中可视化的库也很多,最著名的的莫过于matplotlib了,这是一个面向对象的绘图库,很多方面的用法和matlab类似(从matlab的绘图风格借鉴而来),由于我以前使用过一段时间的matlab,所以上手还是比较快,其他的还有seaborn(据说是对matplotlib的改进和封装,使用起来更加方便,没用过,有时间再研究下)、pygraph等。但是使用最广泛的还是matplotlib。javascript有Echarts(百度的)等,这个我还没接触过,是一个可以网页上进行可视化的函数库,据说很棒。其他的当然还有特别多,这里我就不一一列举了。有兴趣的小伙伴可以自行去查阅资料。这里我决定使用matplotlib,主要是因为最近主要接触的就是python,但是数据可视化方面的库用的不多,刚好可以拿这次的数据来练练手,其次我接触过matlab,相信对matplotlib入手会更快一点。
这次主要分析的有以下几个方面:1、一首歌曲评论数目随时间变化的趋势,比如每天的评论数变化,每月的评论数变化等等。2、一首歌曲点赞数目分布的情况,比如0-10赞有多少个,占多少比例,1000赞以上占多大比例等等。3、热门评论词云的制作,主要想通过词云,将文本挖掘的结果可视化,可以看出哪些是高频词汇等。4、一首歌曲评论者的基本信息的情况展示,比如评论者的地区分布,年龄分布、累计听歌数目分布、动态分布、粉丝数分布等等。通过这些信息,可以直观看出一首歌曲被哪些地区、哪些年龄段的人所喜爱,以及听歌的人具有什么的特点等等。
好了,废话不多说了,直接上图吧。
首先来看一些歌曲评论数随时间的变化。
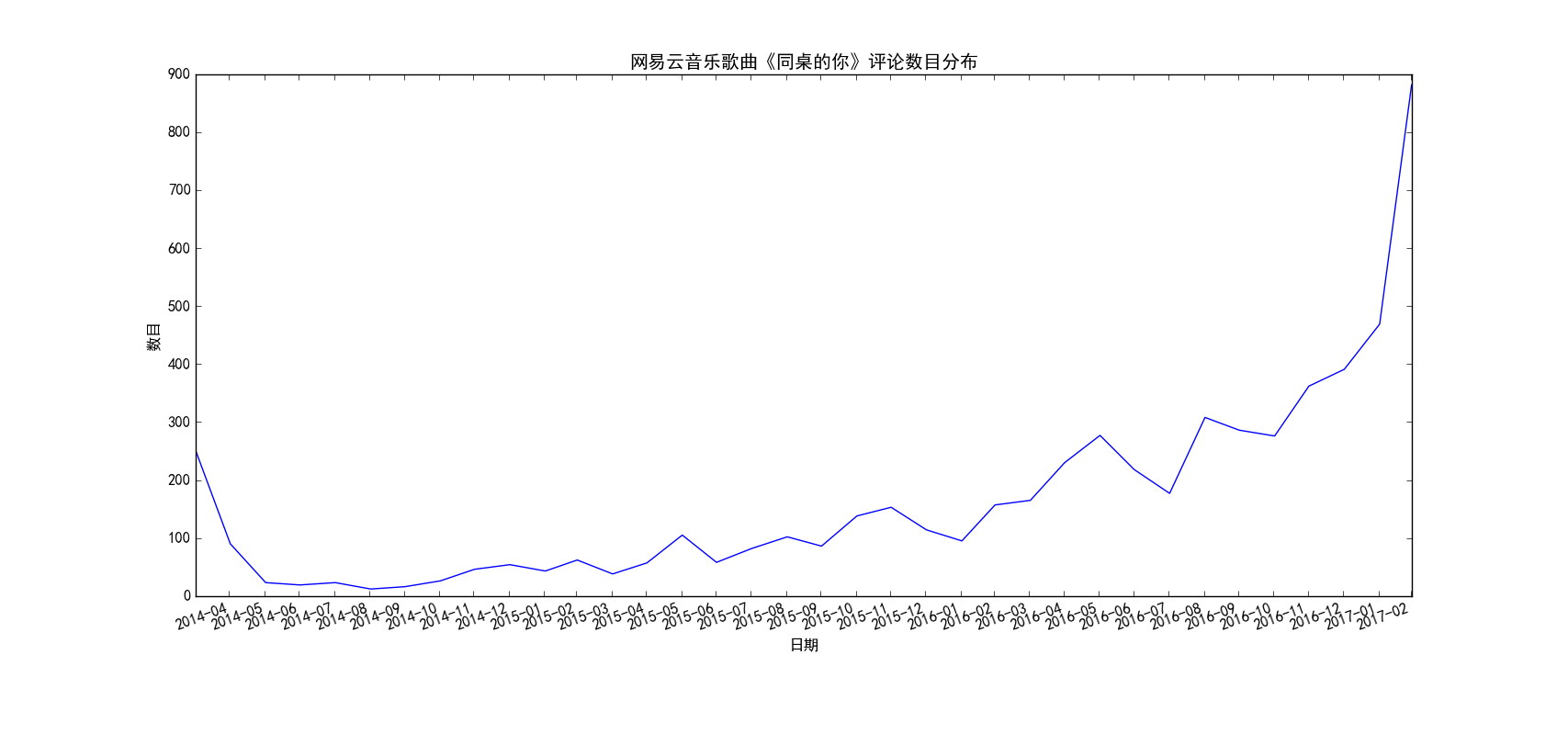
图 1

图 2
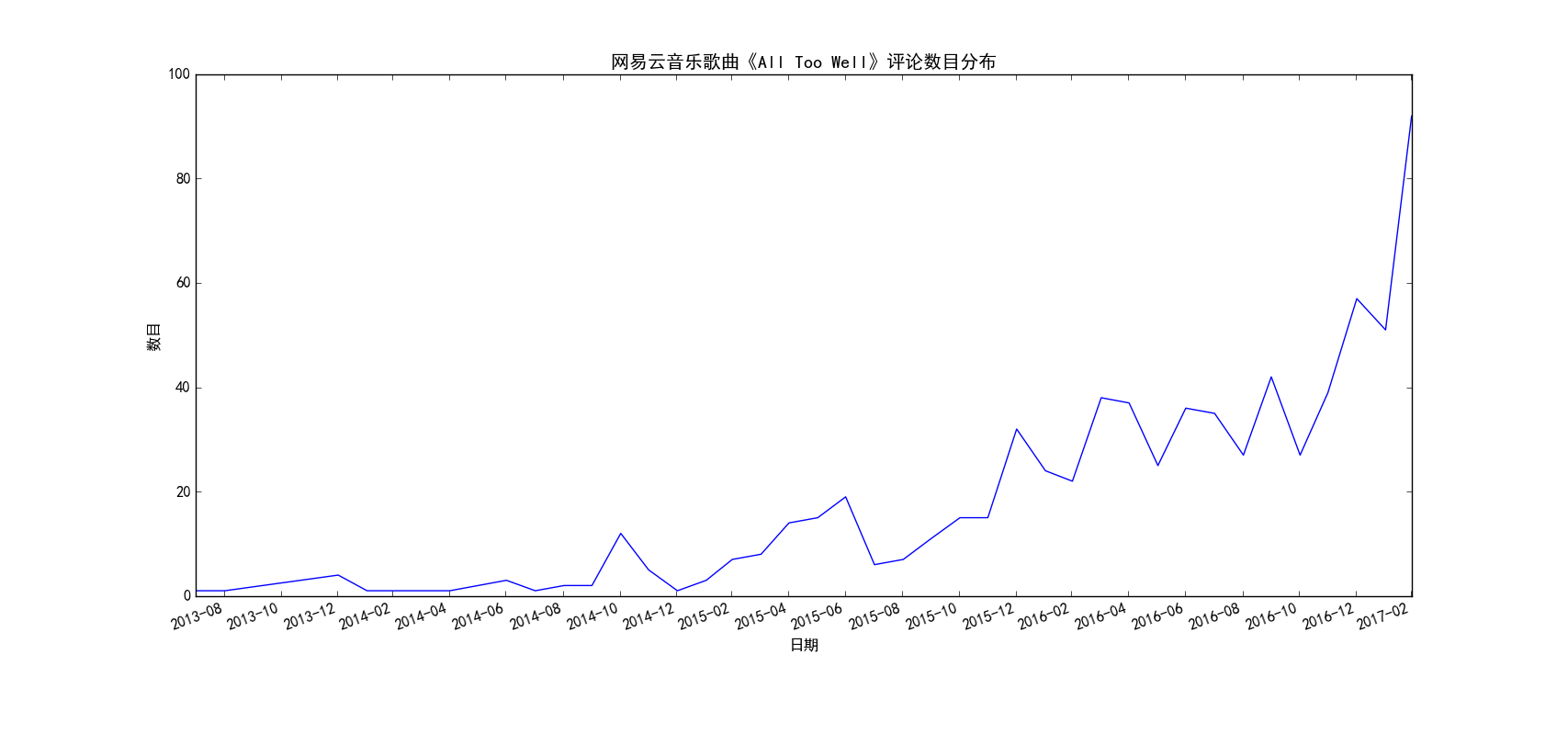
图 3
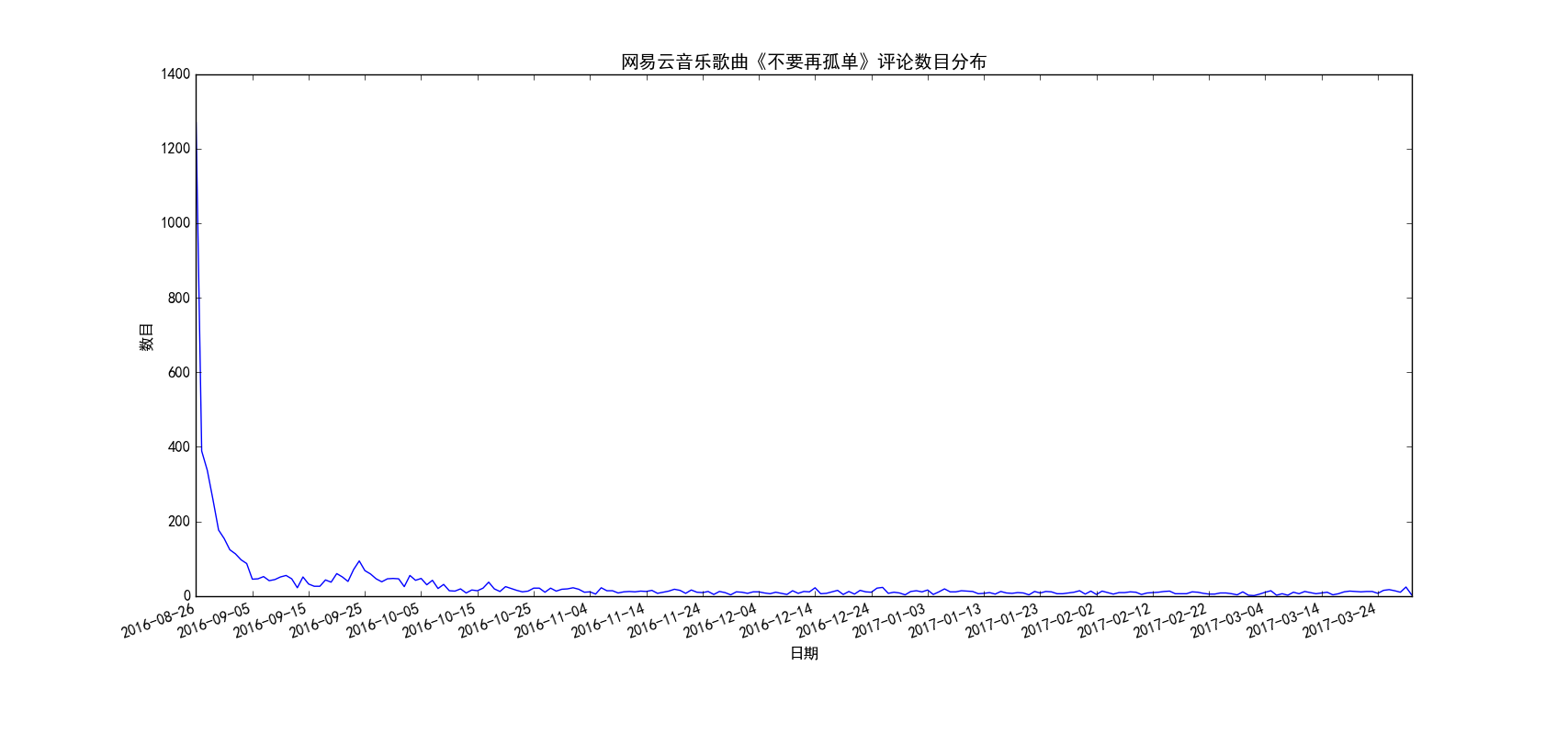
图 4
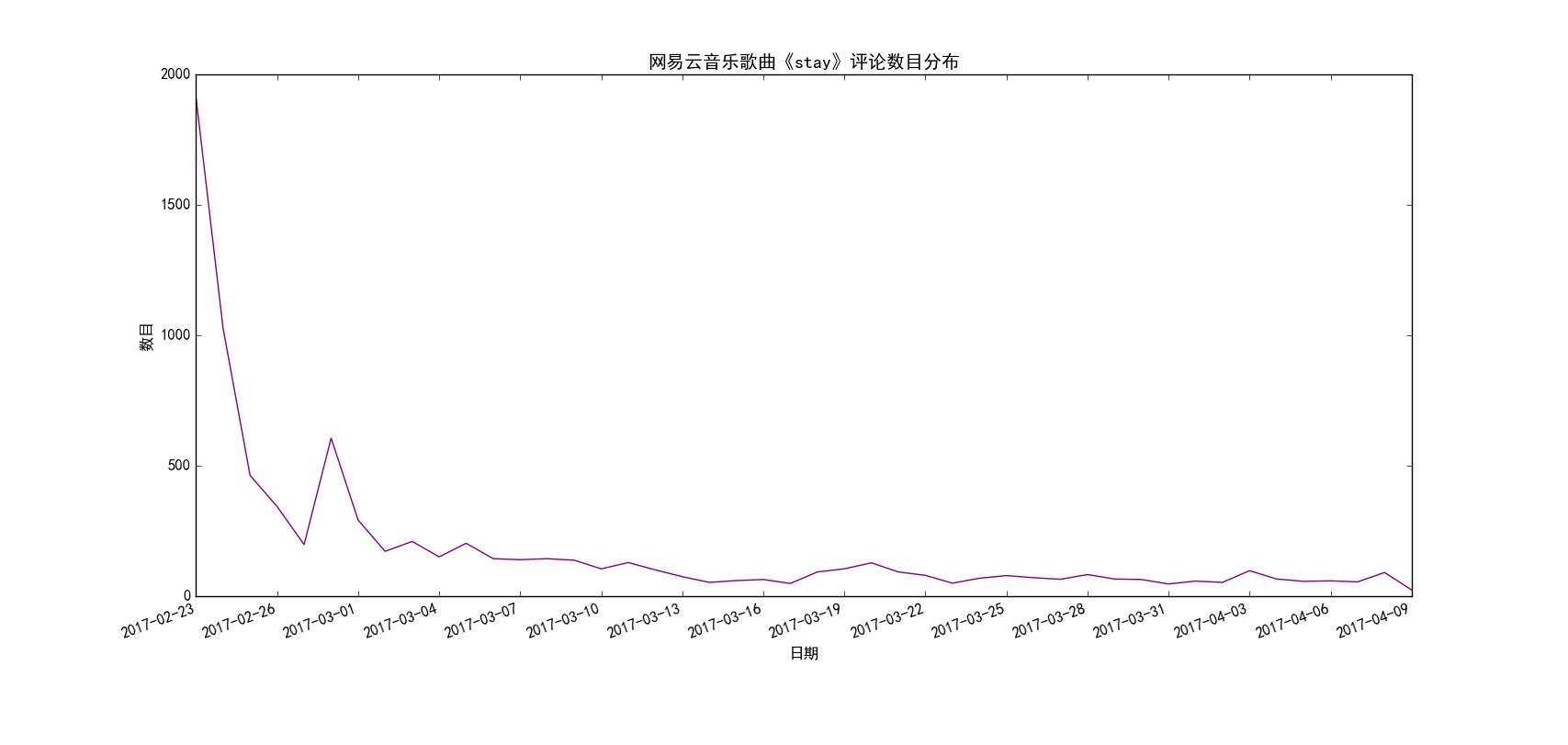
图 5
上面的5张图我分别选取了5首不同的歌曲,有华语歌曲也有英文歌曲,有的起止时间很长(从13年就开始),也有的起止时间很短(从最近几个月才开始)。总的来说可以分为两种模式,一种是开始一段时间评论数很少,后来逐渐呈现爆发式地增长,前面三首歌《同桌的你》、《七里香》、《All Too Well》都是这种模式,而后面两首歌《不要再孤单》、《stay》则是恰好相反,歌曲刚刚出来的那几天评论数猛增,后面评论数逐渐下降,之后趋于平稳。通过分析,其实也很好理解,第一种模式的歌曲,往往都是早期曲库中就存在的歌曲(也可以称之为“老歌”),那个时候网易云音乐才刚刚出来,用户数目还很少,所以这些歌曲每天的评论数很少(没记错的话网易云应该是12、13年左右才出来的吧),后来网易云一路走红,直至现在号称有2亿用户,由于用户基数大,所以这些经典的老歌自然评论数猛增了,可以想见,这种评论爆发式增长和网易云音乐用户的增长趋势应该是基本一致的。而至于第二种模式,出现这种模式的歌曲往往都是比较新的歌曲,而且往往伴随着影视剧的火热突然火起来,比如《不要再孤单》就是电影的主题曲,电影刚上映的那段时间,歌随影热,评论数自然爆发式增长,后来这段热潮过去了,评论数自然就降下来了(当然这种歌曲应该以网络歌曲居多,只是某一段时间特别火,不黑,我觉得真正的经典评论数应该不会大起大落,比如《晴天》、《see you again》等)。当然我只是分析了两种典型的评论随时间变化的模式,实际肯定不止这两种模式,大家可以自行去探索。
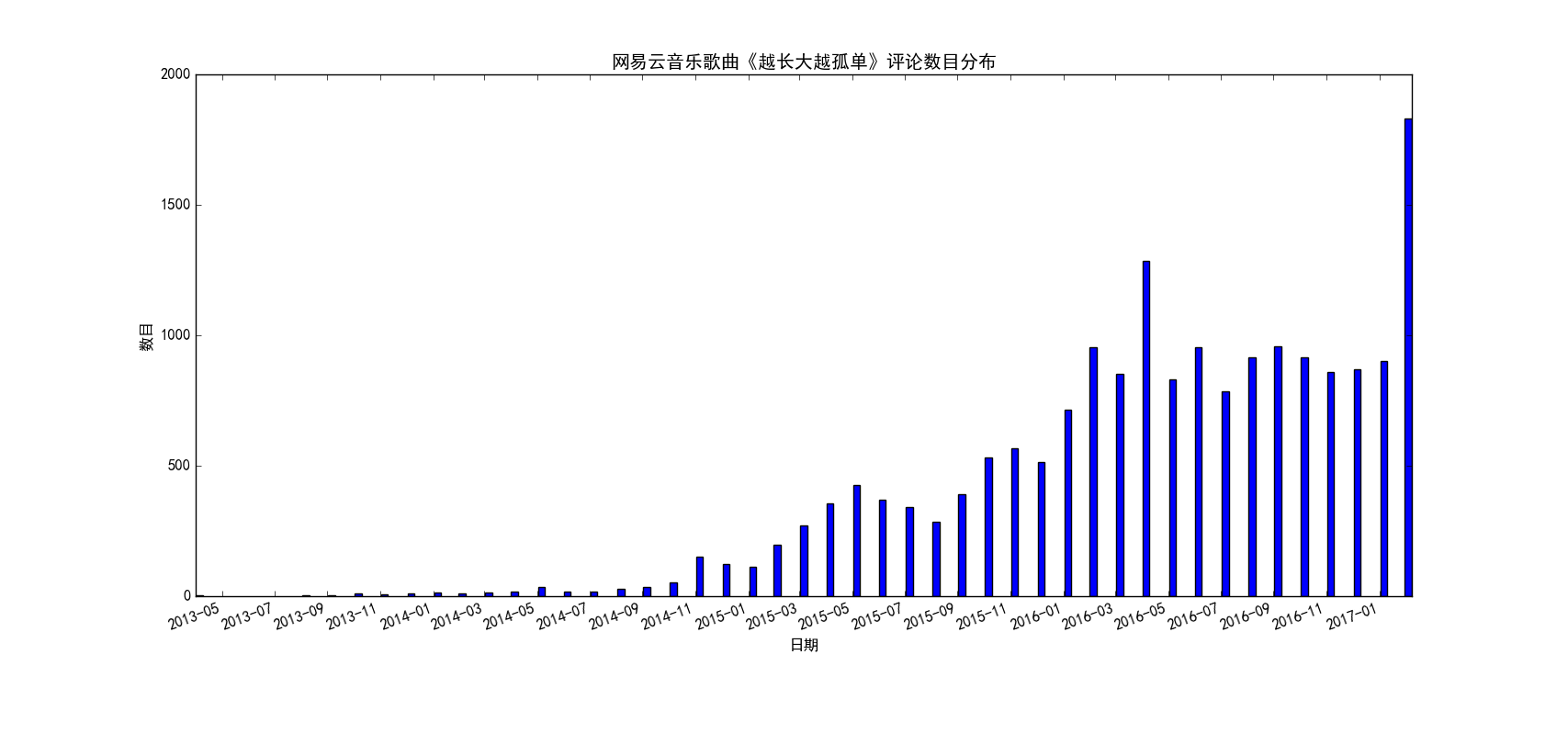
图 6
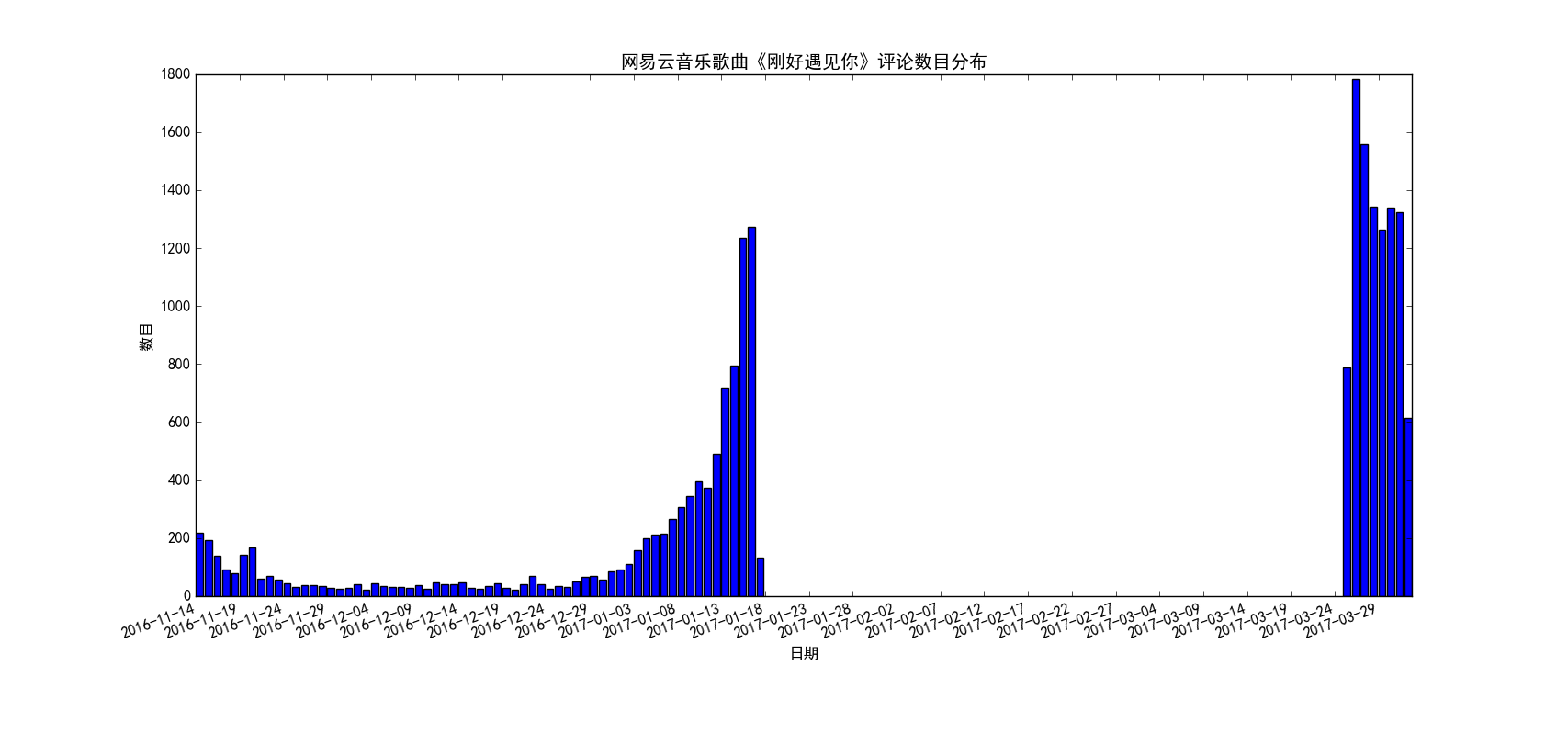
图 7
前面5张图都是使用折线图来展示的,图6使用的是柱状图。我们来看下图7,图7展示的最近一段时间比较火的李玉刚的歌曲《刚好遇见你》的评论数随时间的分布,让人感到奇怪的是,中间从大约1月23日到3月24日的每天的评论量竟然是0!这怎么可能呢?难道真的是这样么?当然不是。我解释一下原因,这是程序本身的bug,我在抓取评论数过10W的歌曲的过程中发现,我最终看似抓取了全部的评论,但是实际上在去除重复之后,我只得到了部分的数据,每次大概只能得到2W到3W左右的数据,其他的数据就缺失了。至今我也没能解决这个问题,个人觉得是服务器做了什么限制,如果有朋友知道该怎么解决这个问题,望能不吝赐教!
除了可以从宏观上看一首歌曲每天或者每月的评论数分布之外,我们还可以将不同的歌曲评论随时间变化放到一起对比,或者将一首歌曲每月的评论数放在一起进行对比。
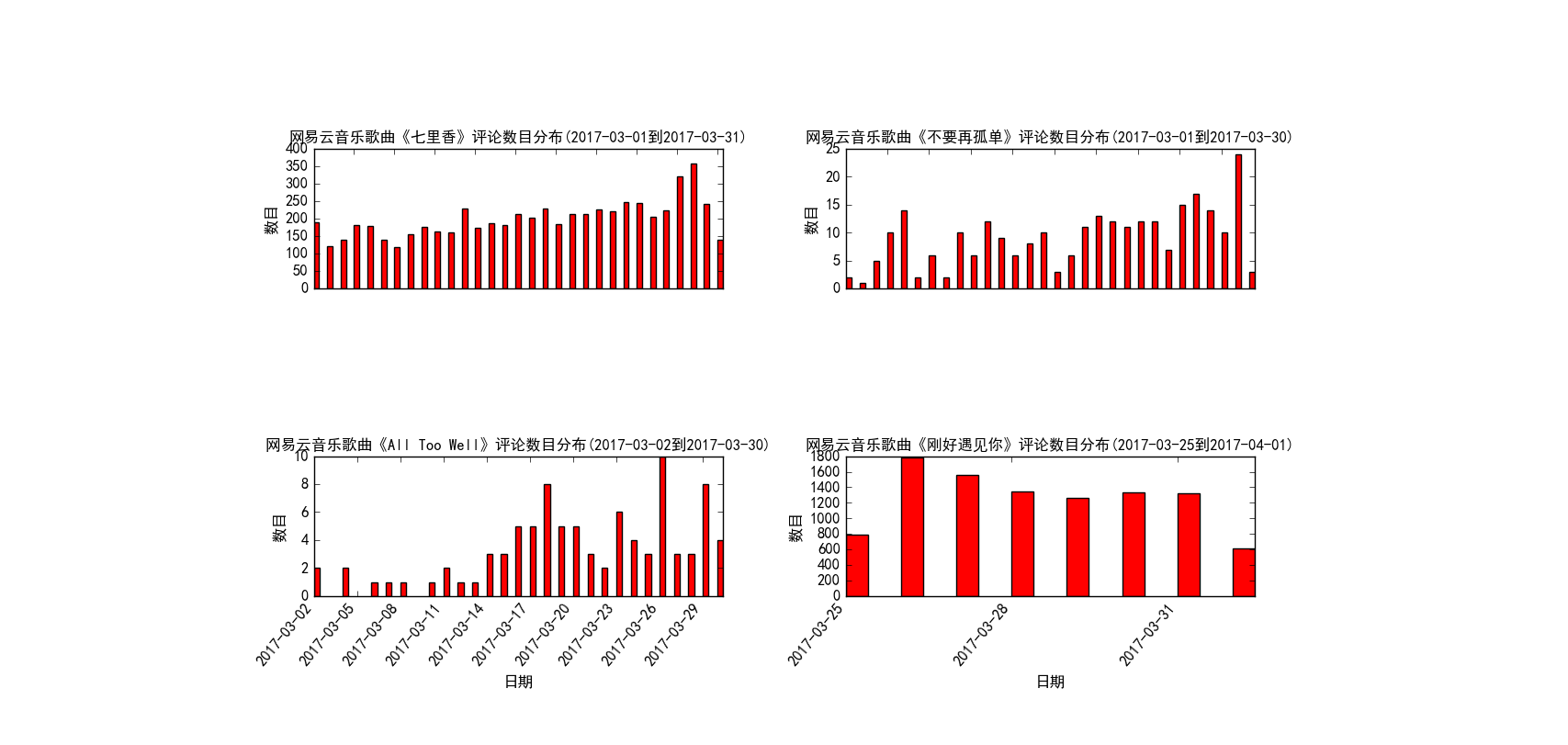
图 8
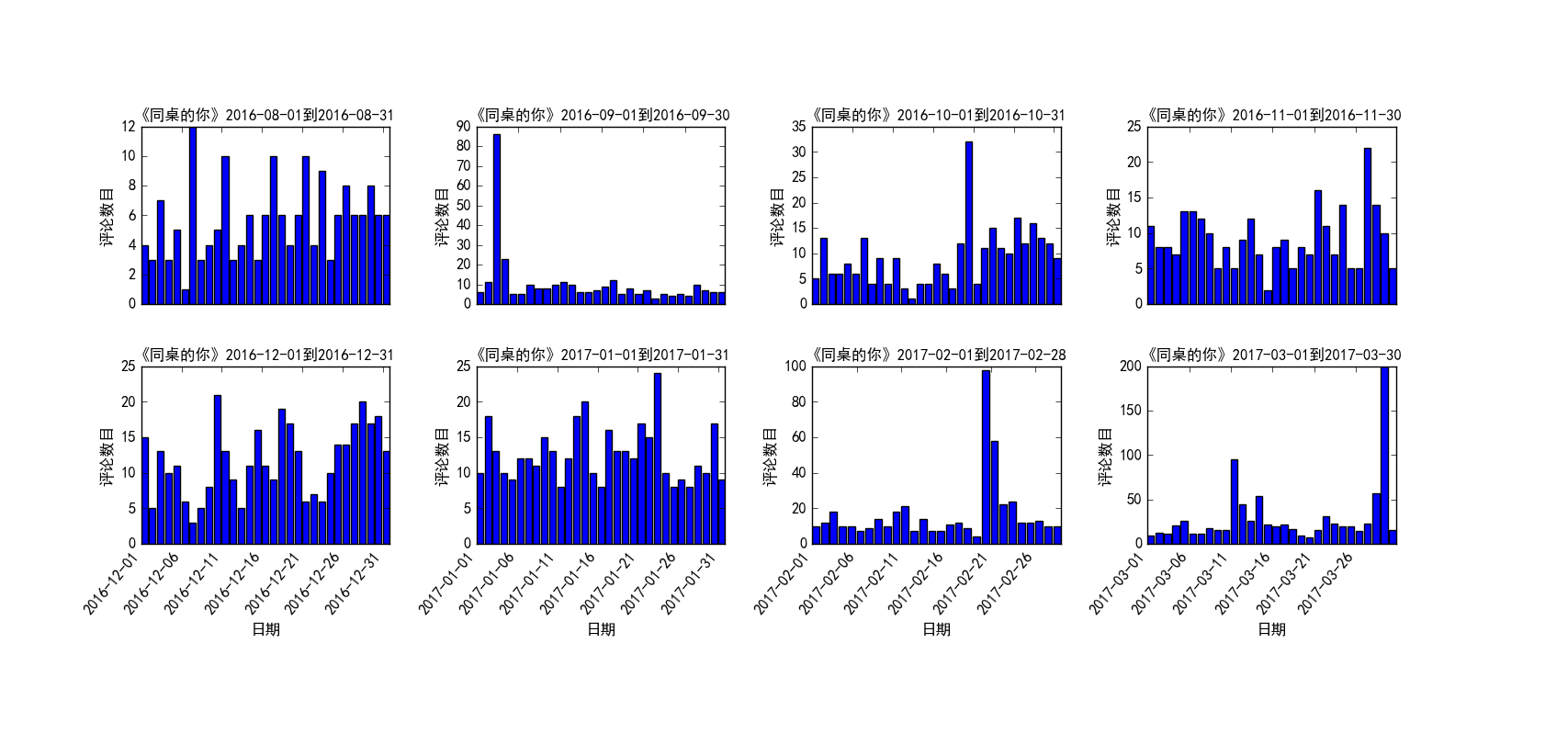
图 9

图 10
图 8 就展示了四首不同的歌曲在某一个时间段评论数目随时间变化,图9展示了《同桌的你》从16年8月到17年3月这8个月的时间里每月评论数的分布情况,图10则是《越长大越孤单》从16年4月到17年3月这12个月的每月评论数分布。其实,这种图形很容易做出,因为我已经将绘图函数做了封装,可以设置自定义参数字典,来生成自己想要的不同的图形,也可以选择绘制图形的种类、颜色以及绘制的时间段、时间间隔等,在文末我会说明这一点。
接下来,看一下评论点赞数目的分布情况。
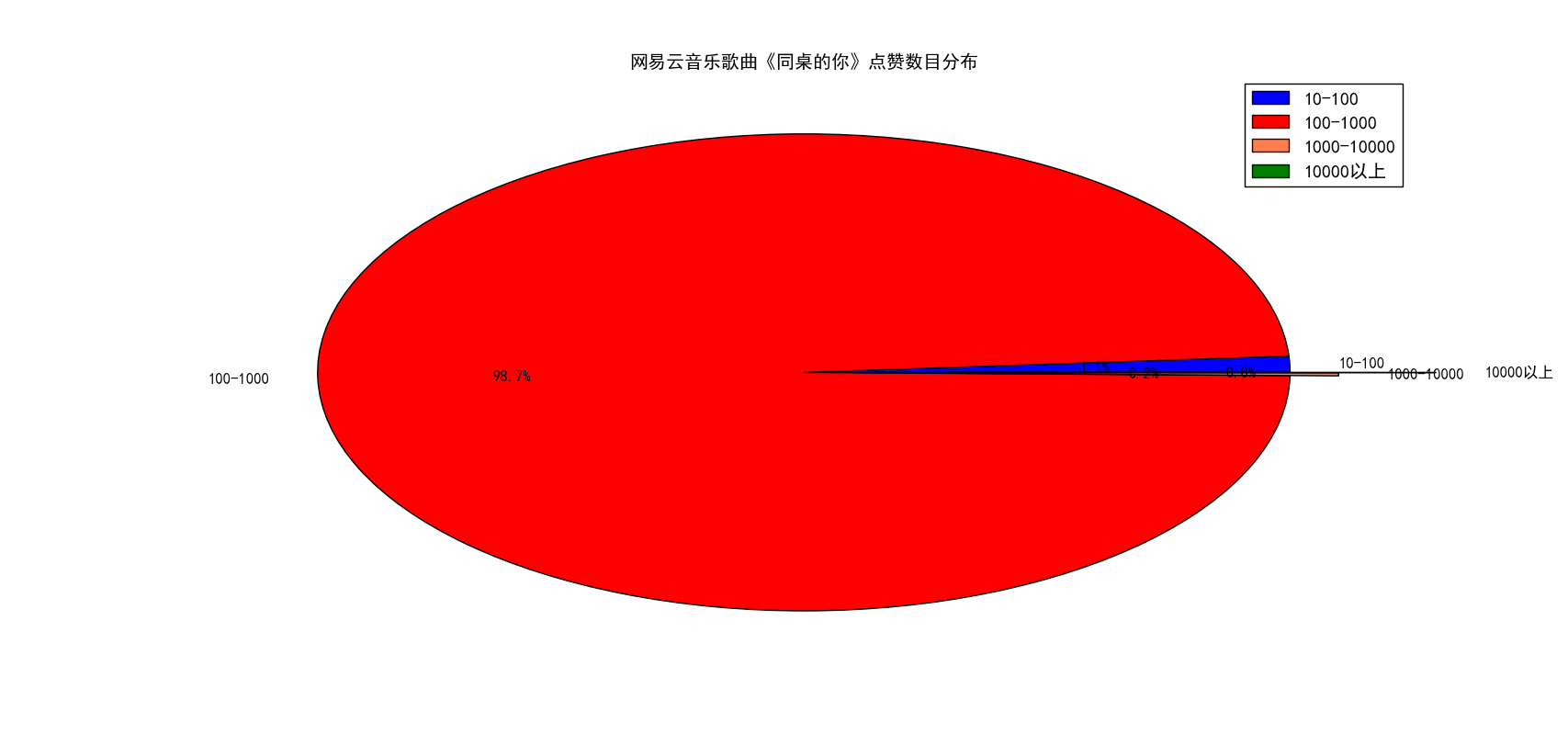
图 11
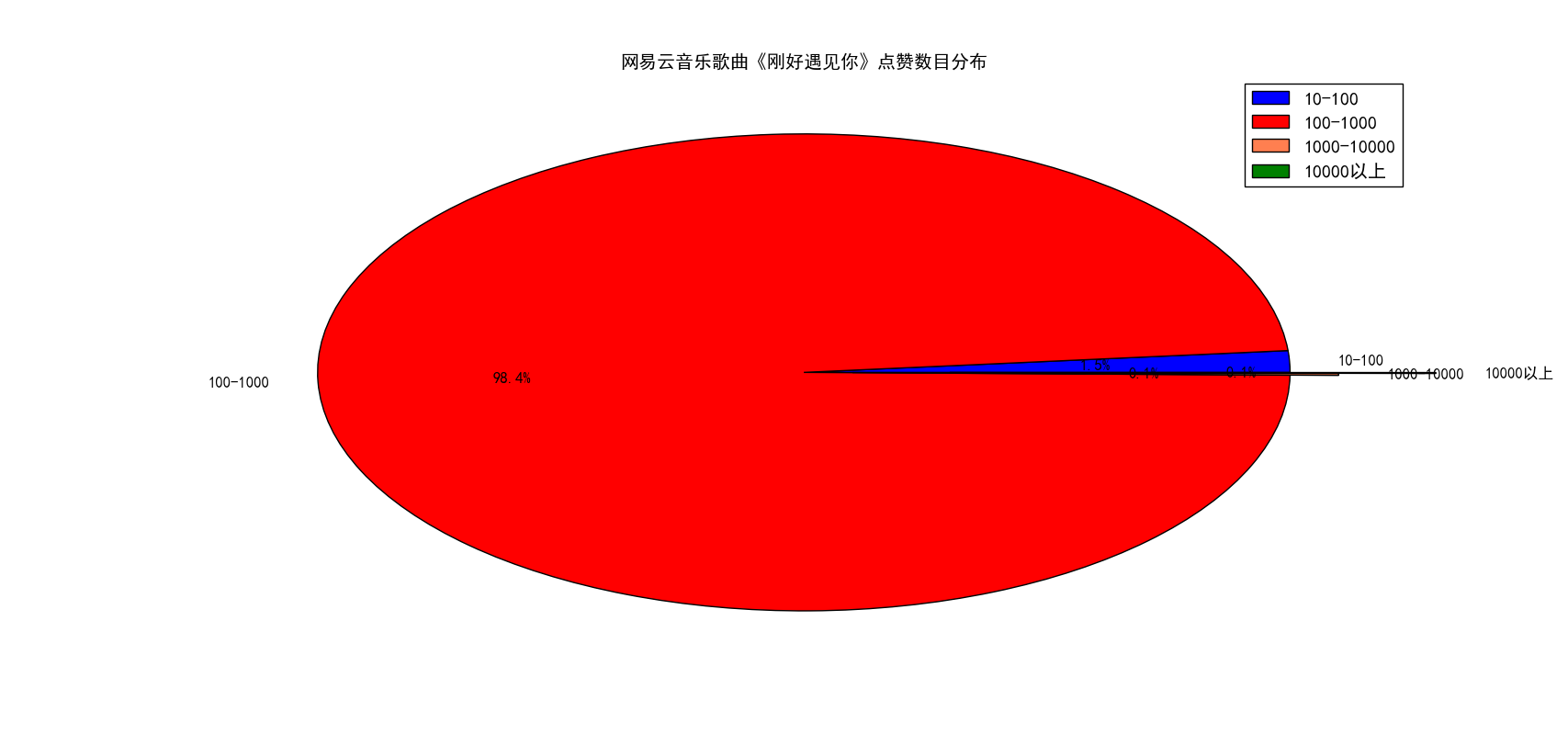
图 12
图10和图11展示的点赞数目分布我去除了10赞以下的,原因是我发现一首歌曲绝大部分的点赞数目(超过99%)都是10赞以下的,这也与我们的常识相一致,所以为了方便我就直接去除了。通过上面的两张图我们可以看出,红色区域面积最大,即100赞到1000占据了全部10赞以上评论的绝大部分,其次是10到100赞,然后是1000赞到10000赞,最少的是1W赞以上,我发现大部分歌曲基本都是呈现这个规律,所以只在这里简单提一下,就不做详细分析了。
接下来分析歌曲热门评论的词云展示,其实python的词云,我之前的一篇随笔也有提到过,使用wordcloud(绘制词云)和jieba(中文分词)即可。这里就不细说了。直接看图吧。

图 13 《不要再孤单》词云

图 14 周杰伦热门50首歌曲热门评论词云

图 15 Taylor Swift 热门歌曲热门评论词云
从以上的词云中还是可以看出一首歌曲或者一位歌手,评论区中出现频率最高的是哪些词的。比如杰伦 的热门评论中反复出现的词就有周杰伦、青春、喜欢、女朋友、故事等等,一股青春怀旧风扑面而来啊。哈哈,其他有意思的大家自己去分析吧。
最后,我想重点来分析一下,一首歌曲的评论者个人信息具有什么样的特点。我将这些特点放在一张图中,通过多张饼图来展示了,见下。
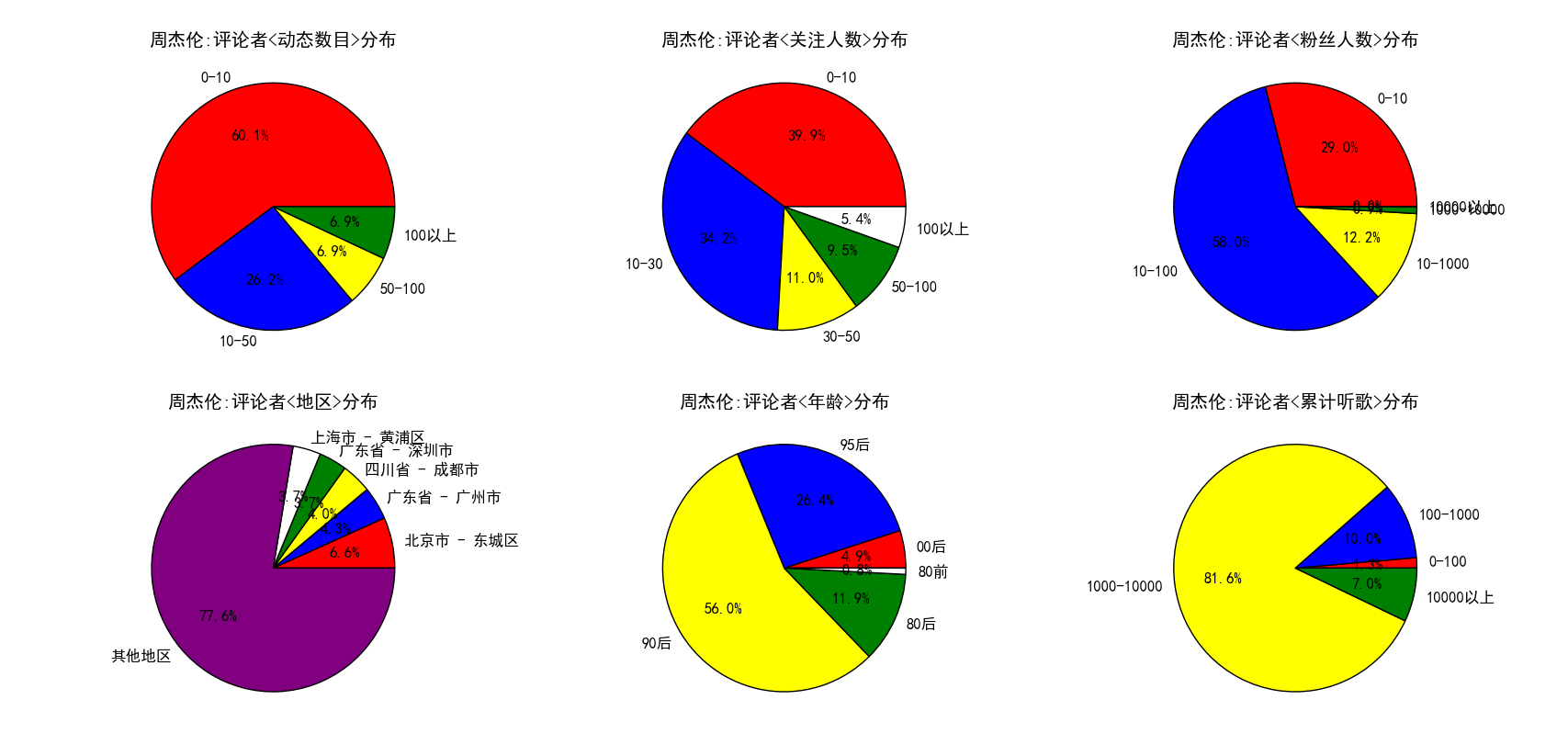
图 16
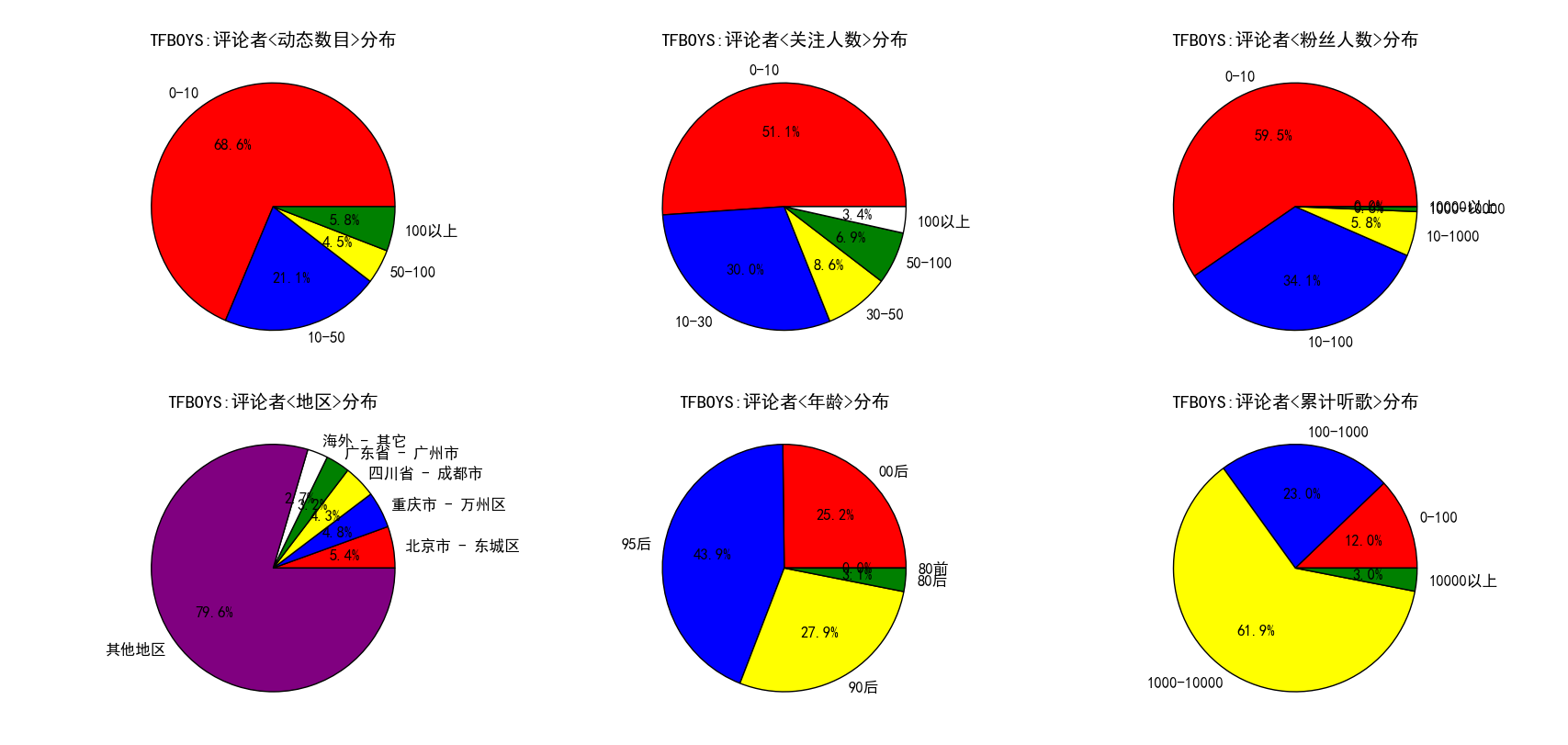
图 17
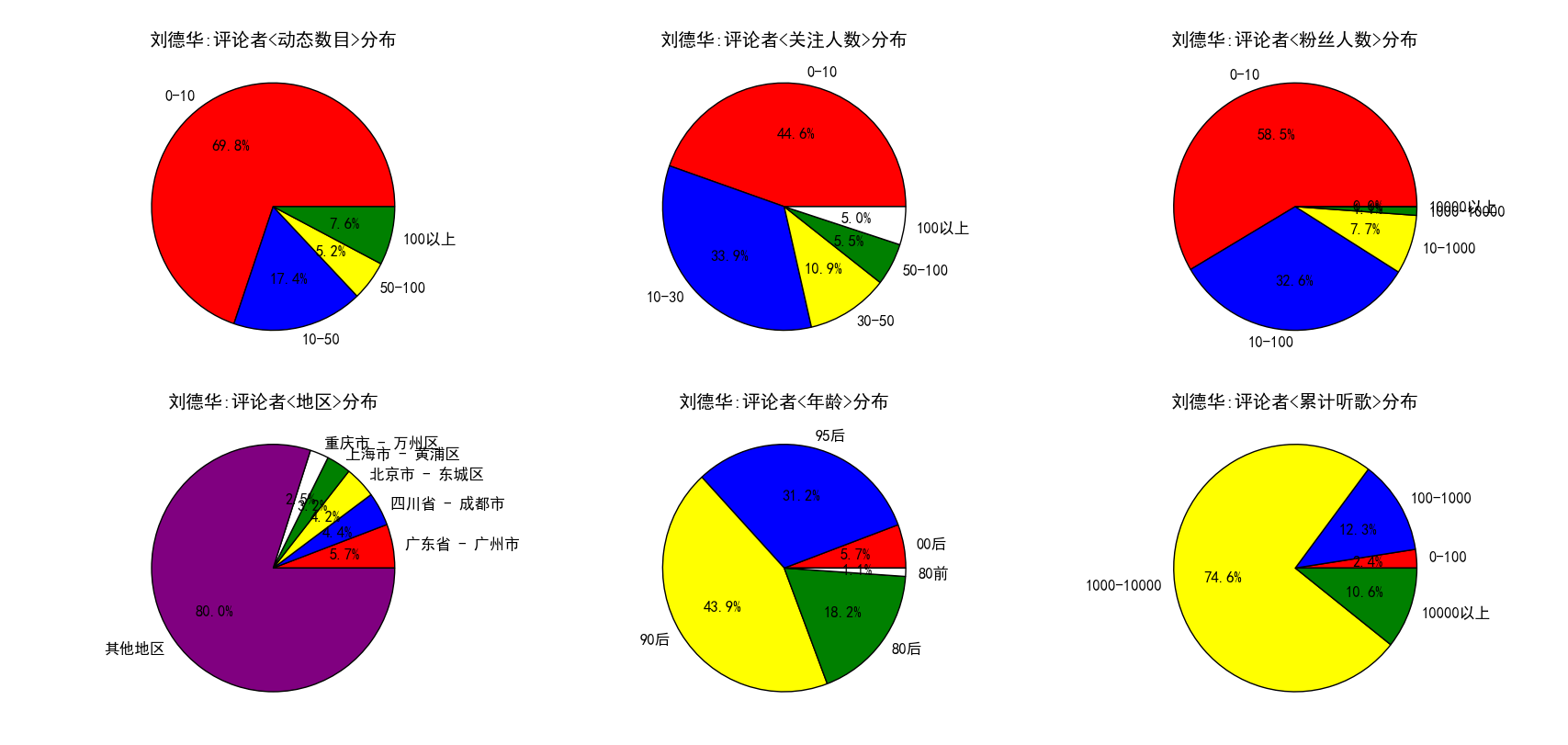
图 18
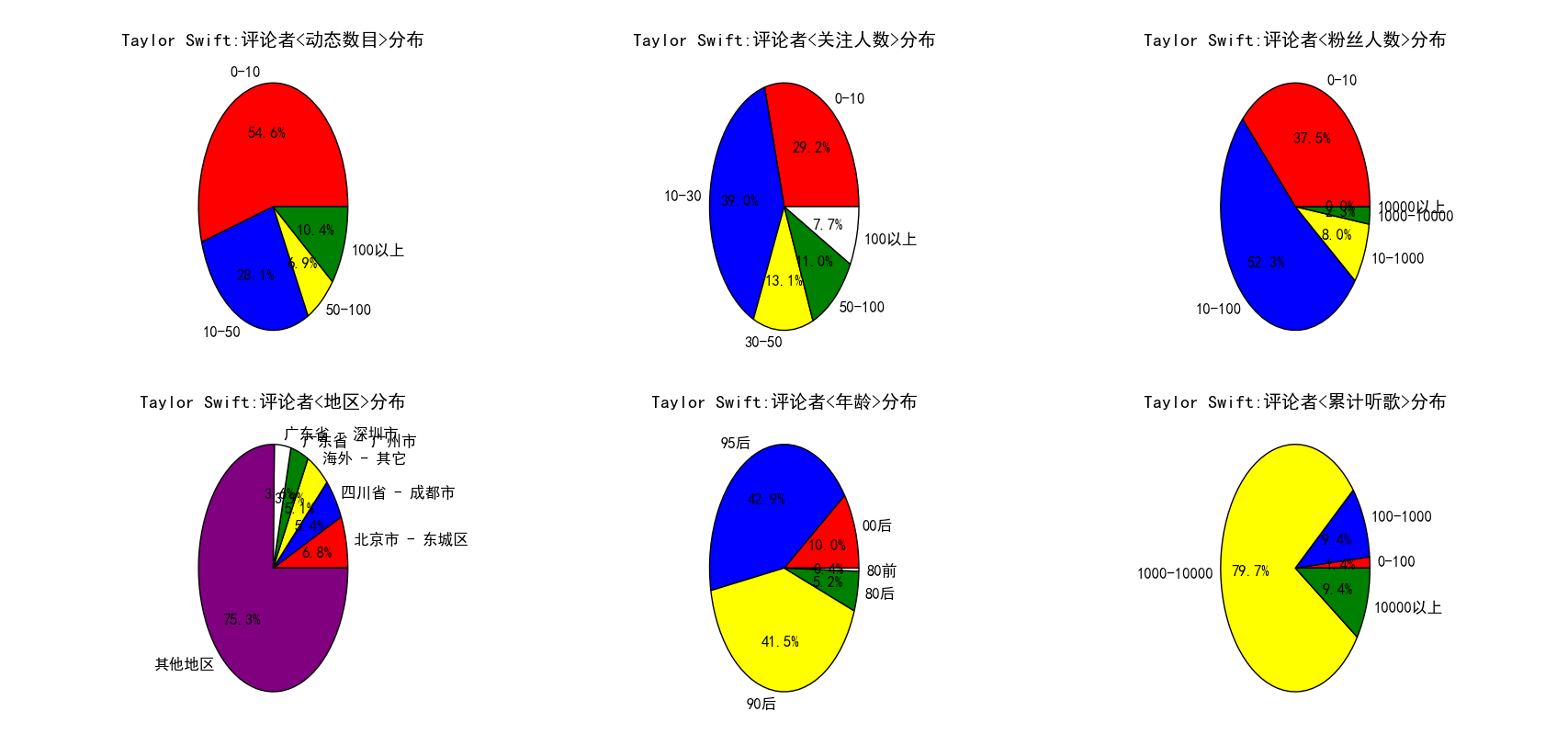
图 19
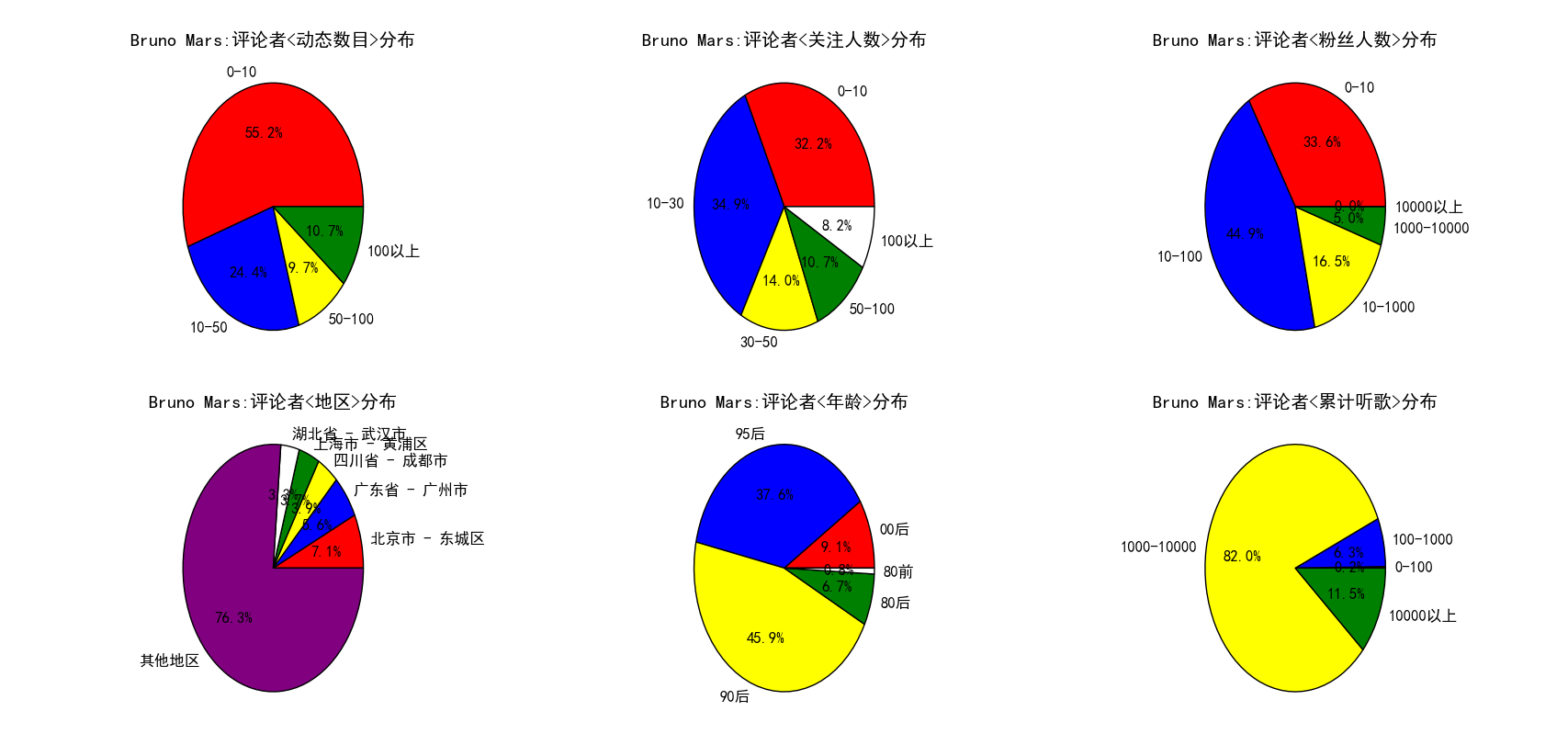
图 20
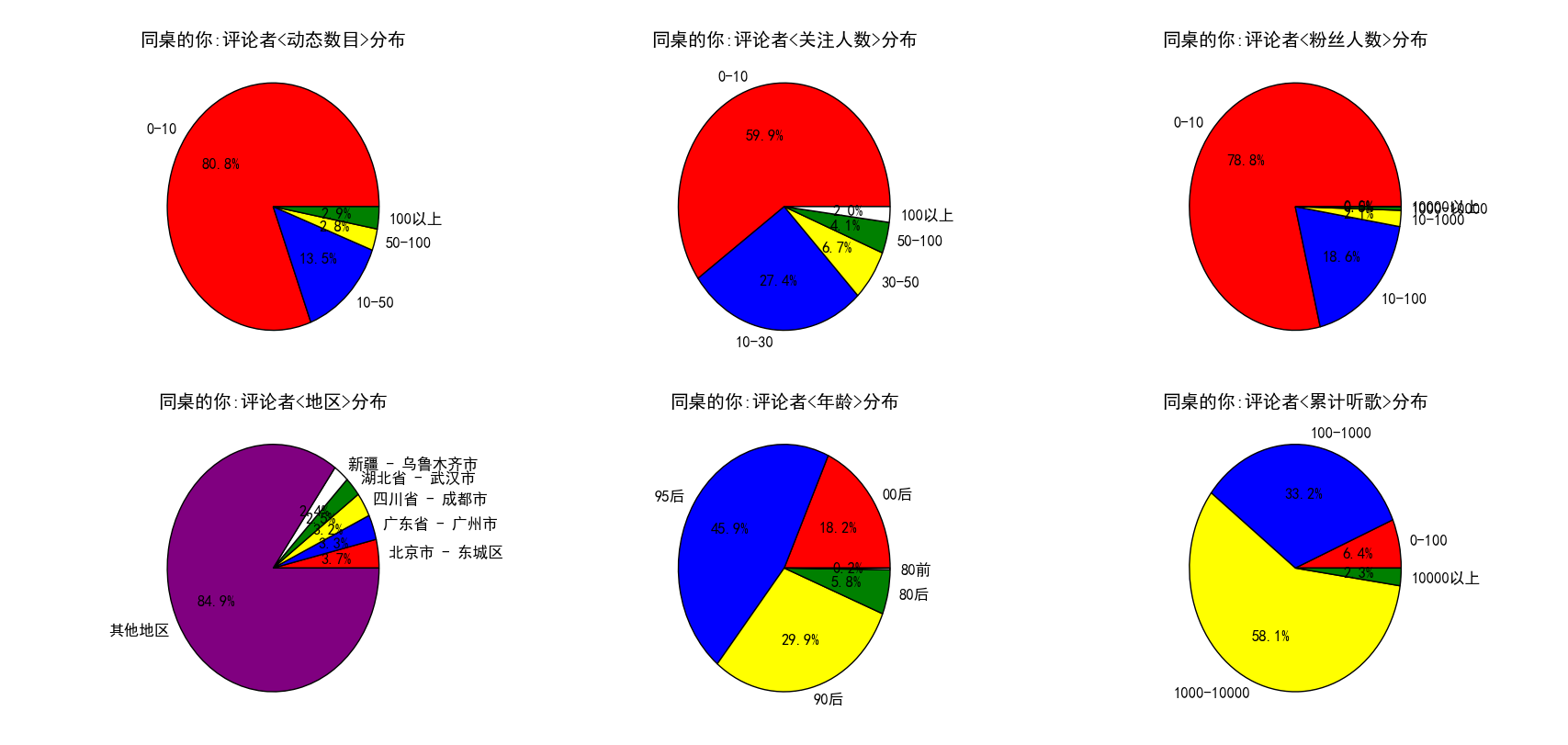
图 21

图 22
图 16 到 图 22 展示了不同的歌手(有中有外,有老有少)以及不同的歌曲(老歌和新歌)评论者多方面的信息分布。通过对比不难发现如下的规律。周杰伦粉丝主要还是以90后和95后为主,这二者之和超过80%。周杰伦、Taylor Swift、Bruno Mars 这三位歌手评论者累计听歌在1000到10000之间的人数(1000-10000算是累计听歌较多)占比要显著高于其他几个歌手,粉丝人数在10-100以及100-1000的比例也是如此,这几位都可以称得上时下的歌坛巨星,评论者的听歌数目以及粉丝人数可以在一定程度上反映出对音乐的喜爱程度以及对音乐的鉴赏力吧(不黑)。TFboys评论者中00后的比例高达25%,为列举的所有歌手中最高,其他歌手00后的比例均不超过10%,不过考虑到tf是美少男组合,这也就可以说的通了。刘德华歌曲的评论者中80后以及80前的比例之和近20%,而其他歌手这一数字基本在7%左右,这在一定程度上可以说明刘天王的粉丝最多的还是而立之后的中年人啊。再来看地区,一眼望去,无论是歌手还是歌曲,地区分布的前五中都出现了一个共同的身影,那就是北京市东城区,看来网易云上有相当一部分用户都是来自北京市东城区啊,不过考虑到北京市是我国的文化中心,许多明星、歌手均在北京定居,还有网易云上推荐的一些音乐人很多都在北京(东城区),这点就不难理解了。多次出现的地区还有广州市、成都市等等,这些都是经济较发达的地区,也是文化产业特别是音乐产业发达的地区(广州主要是粤语歌,而且离香港也很近,成都民谣应该很丰富(猜测))。这么一考虑,这些结果就不难理解了。当然,可以挖掘的其他信息还有很多,比如还有动态的分布等等,还可以按照音乐的类别进行对比等等,如果有兴趣,大家可以自己去完成这个工作。
到这里,其实评论数据的可视化就差不多结束了。其实我做得很粗糙,很多分析也纯属我个人的臆测,大家随便看看就好。最后我还有几点要补充的。
在这次写代码的过程中,我一开始觉得应该写不了几行应该就把数据可视化搞定了,没想到最终还花了我挺长的时间,加到一起代码有七八百行,当然,很多东西都是可以精简的,我懒得去弄了。我将绘图的几个函数抽象了出来,可以通过简单地配置参数字典(settings)传入函数来配置自己想要的图形,比如可以控制要绘制散点图还是柱状图,控制颜色、时间间隔等等,只需要更改相应的参数字典就可以了。主要有两个类,一个是NetCloudCrawl类,主要用于歌曲评论数的抓取,还有一个是NetCloudProcessor,主要用于生成相关文件以及绘制可视化图形。几个主要的函数如下:1 create_all_necessary_files(song_id,song_name) 这个函数可以自动完成评论数据的抓取(包括热门评论)、保存到文件,生成必要的统计txt文件,生成词云等。只需要传入歌曲id(song_id)以及歌曲名字(song_name)即可。2 plot_comments(song_name,settings)函数,用于绘制基本的评论或者点赞图形,settings为参数字典,用于控制绘图方式以及呈现结果。3 sub_plot_comments(song_names_list,settings,row,col)用于在一张图中绘制多个歌曲的评论分布,song_names_list 为歌曲名字列表,settings 为绘图参数字典,row为子图行数,col为子图列数。 4 draw_wordcloud 用于绘制词云 5 sub_plot_months 用于在一张图中绘制某一首歌曲在某几个月(按月绘制)中的评论分布。6 sub_plot_commenters_info 用于绘制歌曲评论者的各项信息分布 。 还有三个 测试函数,分别是 sub_plot_months_test、subplot_test、plot_comments_test 直接调用相应的绘图函数,可以方便地在其中配置参数字典,然后直接调用测试函数即可绘制图形。所以绘制图形其实只有简单的两步:第一步,确定歌曲名称以及id(直接去网易云音乐上找相应歌曲链接即可,?id= 后面的数字就是歌曲id),然后调用create_all_necessary_files 生成所需要的文件;第二步:调用相应的绘图函数,一般只需要传入歌曲名字以及参数字典即可。
最后还是附上全部的代码如下:
NetCloud_spider3.py
1 #!/usr/bin/env python2.7 2 # -*- coding: utf-8 -*- 3 # @Time : 2017/3/28 8:46 4 # @Author : Lyrichu 5 # @Email : 919987476@qq.com 6 # @File : NetCloud_spider3.py 7 ''' 8 @Description: 9 网易云音乐评论爬虫,可以完整爬取整个评论 10 部分参考了@平胸小仙女的文章(地址:https://www.zhihu.com/question/36081767) 11 post加密部分也给出了,可以参考原帖: 12 作者:平胸小仙女 13 链接:https://www.zhihu.com/question/36081767/answer/140287795 14 来源:知乎 15 ''' 16 from Crypto.Cipher import AES 17 import base64 18 import requests 19 import json 20 import codecs 21 import time 22 import os 23 24 # 定义抓取评论类NetCloudCrawl 25 class NetCloudCrawl(object): 26 def __init__(self): 27 # 头部信息 28 self.headers = { 29 'Host':"music.163.com", 30 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0", 31 'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3", 32 'Accept-Encoding':"gzip, deflate", 33 'Content-Type':"application/x-www-form-urlencoded", 34 'Cookie':"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820", 35 'Connection':"keep-alive", 36 'Referer':'http://music.163.com/', 37 'Upgrade-Insecure-Requests':"1" 38 } 39 # 设置代理服务器 40 self.proxies= { 41 'http:':'http://180.123.225.51', 42 'https:':'https://111.72.126.116' 43 } 44 # offset的取值为:(评论页数-1)*20,total第一页为true,其余页为false 45 # first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}' # 第一个参数 46 self.second_param = "010001" # 第二个参数 47 # 第三个参数 48 self.third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7" 49 # 第四个参数 50 self.forth_param = "0CoJUm6Qyw8W8jud" 51 self.encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c" 52 53 # 获取参数 54 def get_params(self,page): # page为传入页数 55 first_key = self.forth_param 56 second_key = 16 * 'F' 57 iv = "0102030405060708" 58 if(page == 1): # 如果为第一页 59 first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}' 60 h_encText = self.AES_encrypt(first_param, first_key,iv) 61 else: 62 offset = str((page-1)*20) 63 first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false') 64 h_encText = self.AES_encrypt(first_param, first_key, iv) 65 h_encText = self.AES_encrypt(h_encText, second_key, iv) 66 return h_encText 67 68 # 解密过程 69 def AES_encrypt(self,text, key, iv): 70 pad = 16 - len(text) % 16 71 text = text + pad * chr(pad) 72 encryptor = AES.new(key, AES.MODE_CBC, iv) 73 encrypt_text = encryptor.encrypt(text) 74 encrypt_text = base64.b64encode(encrypt_text) 75 return encrypt_text 76 77 # 获得评论json数据 78 def get_json(self,url, params, encSecKey): 79 data = { 80 "params": params, 81 "encSecKey": encSecKey 82 } 83 response = requests.post(url, headers=self.headers, data=data,proxies = self.proxies) 84 return response.content 85 86 # 抓取热门评论,返回热评列表 87 def get_hot_comments(self,url): 88 hot_comments_list = [] 89 hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容\n") 90 params = self.get_params(1) # 第一页 91 json_text = self.get_json(url,params,self.encSecKey) 92 json_dict = json.loads(json_text) 93 hot_comments = json_dict['hotComments'] # 热门评论 94 print("共有%d条热门评论!" % len(hot_comments)) 95 for item in hot_comments: 96 comment = item['content'] # 评论内容 97 likedCount = item['likedCount'] # 点赞总数 98 comment_time = item['time'] # 评论时间(时间戳) 99 userID = item['user']['userId'] # 评论者id 100 nickname = item['user']['nickname'] # 昵称 101 avatarUrl = item['user']['avatarUrl'] # 头像地址 102 comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u"\n" 103 hot_comments_list.append(comment_info) 104 return hot_comments_list 105 106 # 抓取某一首歌的全部评论 107 def get_all_comments(self,url): 108 all_comments_list = [] # 存放所有评论 109 all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容\n") # 头部信息 110 params = self.get_params(1) 111 json_text = self.get_json(url,params,self.encSecKey) 112 json_dict = json.loads(json_text) 113 comments_num = int(json_dict['total']) 114 if(comments_num % 20 == 0): 115 page = comments_num / 20 116 else: 117 page = int(comments_num / 20) + 1 118 print("共有%d页评论!" % page) 119 for i in range(page): # 逐页抓取 120 params = self.get_params(i+1) 121 json_text = self.get_json(url,params,self.encSecKey) 122 json_dict = json.loads(json_text) 123 if i == 0: 124 print("共有%d条评论!" % comments_num) # 全部评论总数 125 for item in json_dict['comments']: 126 comment = item['content'] # 评论内容 127 likedCount = item['likedCount'] # 点赞总数 128 comment_time = item['time'] # 评论时间(时间戳) 129 userID = item['user']['userId'] # 评论者id 130 nickname = item['user']['nickname'] # 昵称 131 avatarUrl = item['user']['avatarUrl'] # 头像地址 132 comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u"\n" 133 all_comments_list.append(comment_info) 134 print("第%d页抓取完毕!" % (i+1)) 135 return all_comments_list 136 137 138 # 将评论写入文本文件 139 def save_to_file(self,list,filename): 140 with codecs.open(filename,'a',encoding='utf-8') as f: 141 f.writelines(list) 142 print("写入文件成功!") 143 144 # 抓取歌曲评论 145 def save_all_comments_to_file(self,song_id,song_name): 146 start_time = time.time() # 开始时间 147 url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_%d/?csrf_token=" % song_id 148 if(os.path.exists(song_name)): 149 filename = u"%s/%s.txt" % (song_name,song_name) 150 else: 151 os.mkdir(song_name) 152 filename = u"%s/%s.txt" % (song_name,song_name) 153 all_comments_list = self.get_all_comments(url) 154 self.save_to_file(all_comments_list,filename) 155 end_time = time.time() #结束时间 156 print(u"抓取歌曲《%s》耗时%f秒." % (song_name,end_time - start_time))
NetCloud_comments_plot.py
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # @Time : 2017/3/29 9:07 4 # @Author : Lyrichu 5 # @Email : 919987476@qq.com 6 # @File : NetCloud_comments_plot.py 7 ''' 8 @Description: 9 对抓取来的网易云评论数据进行简单的可视化分析 10 ''' 11 from NetCloud_spider3 import NetCloudCrawl 12 import requests 13 import matplotlib.dates as mdates 14 from pylab import * 15 mpl.rcParams['font.sans-serif'] = ['SimHei'] # 防止无法显示中文 16 import matplotlib.pyplot as plt 17 from datetime import datetime 18 import re 19 import time 20 import pandas as pd 21 import codecs 22 import jieba 23 from wordcloud import WordCloud 24 from scipy.misc import imread 25 from os import path 26 import os 27 28 29 class NetCloudProcessor(NetCloudCrawl): 30 # 读取评论文本数据,返回一个列表,列表的每个元素为一个字典,字典中包含用户id,评论内容等 31 def read_comments_file(self,filename): 32 list_comments = [] # 评论数据列表 33 with open(filename,'r') as f: 34 comments_list = f.readlines() # 读取文本,按行读取,返回列表 35 del comments_list[0] # 删除首个元素 36 comments_list = list(set(comments_list)) # 去除重复数据 37 count_ = -1 # 记录评论数 38 for comment in comments_list: 39 comment = comment.replace("\n","") # 去除末尾的换行符 40 try: 41 if (re.search(re.compile(r'^\d+?'),comment)): # 如果以数字开头 42 comment_split = comment.split(' ',5) # 以空格分割(默认) 43 comment_dict = {} 44 comment_dict['userID'] = comment_split[0] # 用户ID 45 comment_dict['nickname'] = comment_split[1] # 用户昵称 46 comment_dict['avatarUrl'] = comment_split[2] # 用户头像地址 47 comment_dict['comment_time'] = int(comment_split[3])# 评论时间 48 comment_dict['likedCount'] = int(comment_split[4])# 点赞总数 49 comment_dict['comment_content'] = comment_split[5] # 评论内容 50 list_comments.append(comment_dict) 51 count_ += 1 52 else: 53 list_comments[count_]['comment_content'] += comment # 将评论追加到上一个字典 54 except Exception,e: 55 print(e) 56 list_comments.sort(key= lambda x:x['comment_time']) 57 print(u"去除重复之后有%d条评论!" % (count_+1)) 58 return (count_+1,list_comments) # 返回评论总数以及处理完的评论内容 59 60 # 将网易云的时间戳转换为年-月-日的日期函数 61 # 时间戳需要先除以1000才能得到真实的时间戳 62 # format 为要转换的日期格式 63 def from_timestamp_to_date(self,time_stamp,format): 64 time_stamp = time_stamp*0.001 65 real_date = time.strftime(format,time.localtime(time_stamp)) 66 return real_date 67 68 69 # 统计相关数据写入文本文件 70 def count_comments_info(self,comments_list,count_,song_name): 71 x_date_Ym = [] # 评论数按年月进行统计 72 x_date_Ymd = [] # 评论数按年月日进行统计 73 x_likedCount = [] # 点赞总数分布 74 for i in range(count_): 75 time_stamp = comments_list[i]['comment_time'] # 时间戳 76 real_date_Ym = self.from_timestamp_to_date(time_stamp,'%Y-%m') # 按年月进行统计 77 real_date_Ymd = self.from_timestamp_to_date(time_stamp,'%Y-%m-%d') # 按年月日统计 78 likedCount = comments_list[i]['likedCount'] # 点赞总数 79 x_date_Ym.append(real_date_Ym) 80 x_date_Ymd.append(real_date_Ymd) 81 x_likedCount.append(likedCount) 82 x_date_Ym_no_repeat = [] 83 y_date_Ym_count = [] 84 x_date_Ymd_no_repeat = [] 85 y_date_Ymd_count = [] 86 x_likedCount_no_repeat = [] 87 y_likedCount_count = [] 88 # 年月 89 for date_ in x_date_Ym: 90 if date_ not in x_date_Ym_no_repeat: 91 x_date_Ym_no_repeat.append(date_) 92 y_date_Ym_count.append(x_date_Ym.count(date_)) 93 # 年月日 94 for date_ in x_date_Ymd: 95 if date_ not in x_date_Ymd_no_repeat: 96 x_date_Ymd_no_repeat.append(date_) 97 y_date_Ymd_count.append(x_date_Ymd.count(date_)) 98 99 for likedCount in x_likedCount: 100 if likedCount not in x_likedCount_no_repeat: 101 x_likedCount_no_repeat.append(likedCount) 102 y_likedCount_count.append(x_likedCount.count(likedCount)) 103 # 将统计的数据存入txt文件 104 with open(u"%s/comments_num_by_Ym.txt" % song_name,"w") as f: 105 f.write("date_Ym comments_num\n") 106 for index,date_Ym in enumerate(x_date_Ym_no_repeat): 107 f.write(x_date_Ym_no_repeat[index] + " " + str(y_date_Ym_count[index]) + "\n") 108 print(u"成功写入comments_num_by_Ym.txt!") 109 with open(u"%s/comments_num_by_Ymd.txt" % song_name,"w") as f: 110 f.write("date_Ymd comments_num\n") 111 for index,date_Ymd in enumerate(x_date_Ymd_no_repeat): 112 f.write(x_date_Ymd_no_repeat[index] + " " + str(y_date_Ymd_count[index]) + "\n") 113 print(u"成功写入comments_num_by_Ymd.txt!") 114 with open(u"%s/likedCount.txt" % song_name,"w") as f: 115 f.write("likedCount count_num\n") 116 for index,likedCount in enumerate(x_likedCount_no_repeat): 117 f.write(str(x_likedCount_no_repeat[index]) + " " + str(y_likedCount_count[index]) + "\n") 118 print(u"成功写入likedCount.txt!") 119 # 得到处理过的x_date 和 count 统计信息 120 def get_xdate_ycount(self,count_file_name,date_type,min_date_Ym,max_date_Ym,min_date_Ymd,max_date_Ymd): 121 with open(count_file_name,'r') as f: 122 list_count = f.readlines() 123 # comment_or_like = list_count[0].replace("\n","").split(" ")[1] # 判断是评论数还是点赞数 124 # song_name = count_file_name.split("/")[0] # 歌曲名字 125 del list_count[0] 126 x_date = [] 127 y_count = [] 128 for content in list_count: 129 content.replace("\n","") 130 res = content.split(' ') 131 if(date_type == '%Y-%m-%d'): 132 if(int("".join(res[0].split("-"))) >= int("".join(min_date_Ymd.split("-"))) and int("".join(res[0].split("-"))) <= int("".join(max_date_Ymd.split("-")))): 133 x_date.append(res[0]) 134 y_count.append(int(res[1])) 135 else: 136 if(int("".join(res[0].split("-"))) >= int("".join(min_date_Ym.split("-"))) and int("".join(res[0].split("-"))) <= int("".join(max_date_Ym.split("-")))): 137 x_date.append(res[0]) 138 y_count.append(int(res[1])) 139 return (x_date,y_count) 140 141 142 # 绘制图形展示歌曲评论以及点赞分布 143 # plot_type:为 'plot' 绘制散点图 为 'bar' 绘制条形图 144 # date_type 为日期类型 145 # time_distance 为时间间隔(必填)例如:5D 表示5天,1M 表示一个月 146 # min_liked_num 为绘图时的最小点赞数 147 # max_liked_num 为绘图时的最大点赞数 148 # min_date_Ym 为最小日期(年-月形式) 149 # max_date_Ym 为最大日期(年-月形式) 150 # min_date_Ymd 为最小日期(年-月-日形式) 151 # max_date_Ymd 为最大日期(年-月-日形式) 152 def plot_comments(self,song_name,settings): 153 comment_type = settings['comment_type'] 154 date_type = settings['date_type'] 155 plot_type = settings['plot_type'] 156 bar_width = settings['bar_width'] 157 rotation = settings['rotation'] 158 time_distance = settings['time_distance'] 159 min_date_Ymd = settings['min_date_Ymd'] 160 max_date_Ymd = settings['max_date_Ymd'] 161 min_date_Ym = settings['min_date_Ym'] 162 max_date_Ym = settings['max_date_Ym'] 163 if(comment_type): # 评论 164 if(date_type == '%Y-%m-%d'): 165 count_file_name = u"%s/comments_num_by_Ymd.txt" % song_name 166 else: 167 count_file_name = u"%s/comments_num_by_Ym.txt" % song_name 168 else: 169 count_file_name = u"%s/likedCount.txt" % song_name 170 with open(count_file_name,'r') as f: 171 list_count = f.readlines() 172 del list_count[0] 173 if(comment_type): # 如果是评论 174 x_date = [] 175 y_count = [] 176 for content in list_count: 177 content.replace("\n","") 178 res = content.split(' ') 179 if(date_type == '%Y-%m-%d'): 180 if(int("".join(res[0].split("-"))) >= int("".join(min_date_Ymd.split("-"))) and int("".join(res[0].split("-"))) <= int("".join(max_date_Ymd.split("-")))): 181 x_date.append(res[0]) 182 y_count.append(int(res[1])) 183 else: 184 if(int("".join(res[0].split("-"))) >= int("".join(min_date_Ym.split("-"))) and int("".join(res[0].split("-"))) <= int("".join(max_date_Ym.split("-")))): 185 x_date.append(res[0]) 186 y_count.append(int(res[1])) 187 else: # 如果是点赞 188 # 分为10-100,100-1000,1000-10000,10000以上这5个区间,由于绝大多数歌曲评论点赞数都在10赞一下 189 # 超过99%,所以10赞以下暂时忽略 190 x_labels = [u'10-100',u'100-1000',u'1000-10000',u'10000以上'] 191 y_count = [0,0,0,0] 192 for content in list_count: 193 content.replace("\n","") 194 res = content.split(' ') 195 if(int(res[0]) <= 100 and int(res[0]) >= 10): 196 y_count[0] += int(res[1]) 197 elif(int(res[0]) <= 1000): 198 y_count[1] += int(res[1]) 199 elif(int(res[0]) <= 10000): 200 y_count[2] += int(res[1]) 201 else: 202 y_count[3] += int(res[1]) 203 # 如果是评论 204 if(comment_type): 205 type_text = u"评论" 206 x = [datetime.strptime(d, date_type).date() for d in x_date] 207 # 配置横坐标为日期类型 208 plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%s' % date_type)) 209 if(date_type == '%Y-%m-%d'): 210 plt.gca().xaxis.set_major_locator(mdates.DayLocator()) 211 else: 212 plt.gca().xaxis.set_major_locator(mdates.MonthLocator()) 213 if(plot_type == 'plot'): 214 plt.plot(x,y_count,color = settings['color']) 215 elif(plot_type == 'bar'): 216 plt.bar(x,y_count,width=bar_width,color = settings['color']) 217 else: 218 plt.scatter(x,y_count,color = settings['color']) 219 plt.gcf().autofmt_xdate(rotation=rotation) # 自动旋转日期标记 220 plt.title(u"网易云音乐歌曲《" + song_name + u"》" + type_text + u"数目分布") 221 plt.xlabel(u"日期") 222 plt.ylabel(u"数目") 223 plt.xticks(pd.date_range(x[0],x[-1],freq="%s" % time_distance)) # 设置日期间隔 224 plt.show() 225 else: # 如果是点赞 226 x = y_count 227 type_text = u"点赞" 228 pie_colors = settings['pie_colors'] 229 auto_pct = settings['auto_pct'] # 百分比保留几位小数 230 expl = settings['expl'] # 每块距离圆心的距离 231 plt.pie(x,labels = x_labels,explode=expl,colors = pie_colors,autopct = auto_pct) 232 plt.title(u"网易云音乐歌曲《" + song_name + u"》" + type_text + u"数目分布") 233 plt.legend(x_labels) 234 plt.show() 235 plt.close() 236 237 238 # 生成某个歌曲的统计信息文件 239 def generate_count_info_files(self,song_name): 240 filename = "%s/%s.txt" %(song_name,song_name) 241 count_,list_comments = self.read_comments_file(filename) 242 print(u"%s有%d条评论!" % (song_name,count_)) 243 self.count_comments_info(list_comments,count_,song_name) 244 245 # 一步完成数据抓取,生成统计信息文件的工作 246 def create_all_necessary_files(self,song_id,song_name): 247 start_time = time.time() 248 # 数据抓取并写入文件 249 self.save_all_comments_to_file(song_id,song_name) 250 # 生成热门评论文件 251 url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_%d/?csrf_token=" % song_id 252 hot_comments_list = self.get_hot_comments(url) 253 self.save_to_file(hot_comments_list,u"%s/hotcomments.txt" % song_name) 254 # 生成统计信息文件(3个) 255 self.generate_count_info_files(song_name) 256 # 生成所有评论者信息文件 257 self.save_commenters_info_to_file(song_name) 258 # 生成 评论词云(全部评论) 259 self.draw_wordcloud(song_name,singer_name=False) 260 end_time = time.time() 261 print(u"任务完成!程序耗时%f秒!" %(end_time - start_time)) 262 # 得到某首歌曲下所有评论者(需要去除重复)的主页信息 263 def get_commenters_info(self,filename): 264 commenters_info_list = [] # 存放评论用户信息 265 with codecs.open(filename,"r",encoding= 'utf-8') as f: 266 lists = f.readlines() 267 del lists[0] # 删除第一行 268 commenters_urls_list = [] # 评论者列表 269 for info in lists: 270 if(re.match(r'^\d.*?',info)): 271 commenters_urls_list.append(u"http://music.163.com/user/home?id=" + info.split(" ")[0]) # 评论者主页地址 272 commenters_urls_list = list(set(commenters_urls_list)) # 去除重复的人 273 print("共有%d个不同评论者!" % len(commenters_urls_list)) 274 for index,url in enumerate(commenters_urls_list): 275 try: 276 info_dict = {} # 评论用户个人信息字典 277 user_id_compile = re.compile(r'.*id=(\d+)') 278 user_id = re.search(user_id_compile,url).group(1) 279 html = requests.get(url,headers = self.headers).text 280 event_count_compile = re.compile(r'<strong id="event_count">(\d+?)</strong>') 281 event_count = re.search(event_count_compile,html).group(1) # 个人动态数目 282 follow_count_compile = re.compile(r'<strong id="follow_count">(\d+?)</strong>') 283 follow_count = re.search(follow_count_compile,html).group(1) # 关注人数 284 fan_count_compile = re.compile(r'<strong id="fan_count">(\d+?)</strong>') 285 fan_count = re.search(fan_count_compile,html).group(1) 286 location_compile = re.compile(u'<span>所在地区:(.+?)</span>') # 注意需要使用unicode编码,正则表达式才能匹配 287 location_res = re.search(location_compile,html) 288 if(location_res): 289 location = location_res.group(1) 290 else: 291 location = u"未知地区" 292 self_description_compile = re.compile(u'<div class="inf s-fc3 f-brk">个人介绍:(.*?)</div>') 293 if(re.search(self_description_compile,html)): # 如果可以匹配到 294 self_description = re.search(self_description_compile,html).group(1) 295 else: 296 self_description = u"未知个人介绍" 297 age_compile = re.compile(r'<span.*?data-age="(\d+)">') 298 if(re.search(age_compile,html)): 299 age_time = re.search(age_compile,html).group(1) # 这个得到的是出生日期距离unix时间戳起点的距离 300 # 需要将其转换为年龄 301 age = (2017-1970) - (int(age_time)/(1000*365*24*3600)) # 真实的年龄 302 else: 303 age = u"未知年龄" 304 listening_songs_num_compile = re.compile(u'<h4>累积听歌(\d+?)首</h4>') 305 if(re.search(listening_songs_num_compile,html)): 306 listening_songs_num = re.search(listening_songs_num_compile,html).group(1) # 听歌总数 307 else: 308 listening_songs_num = u'未知听歌总数' 309 info_dict['user_id'] = user_id 310 info_dict['event_count'] = event_count # 动态总数 311 info_dict['follow_count'] = follow_count # 关注总数 312 info_dict['fan_count'] = fan_count # 粉丝总数 313 info_dict['location'] = location # 所在地区 314 info_dict['self_description'] = self_description # 个人介绍 315 info_dict['age'] = age # 年龄 316 info_dict['listening_songs_num'] = listening_songs_num # 累计听歌总数 317 commenters_info_list.append(info_dict) 318 print("成功添加%d个用户信息!" % (index+1)) 319 except Exception,e: 320 print e 321 return commenters_info_list # 返回评论者用户信息列表 322 323 # 保存评论者的信息 324 def save_commenters_info_to_file(self,song_or_singer_name): 325 if(os.path.exists(u"%s/%s.txt" % (song_or_singer_name,song_or_singer_name))): 326 filename = u"%s/%s.txt" % (song_or_singer_name,song_or_singer_name) 327 else: 328 filename = u"%s/hotcomments.txt" % song_or_singer_name 329 commenters_info_lists = self.get_commenters_info(filename) # 得到用户信息列表 330 with codecs.open(u"%s/commenters_info.txt" % song_or_singer_name,"w",encoding='utf-8') as f: 331 f.write(u"用户ID 动态总数 关注总数 粉丝总数 所在地区 个人介绍 年龄 累计听歌总数\n") 332 for info in commenters_info_lists: 333 user_id = info['user_id'] # 用户id 334 event_count = info['event_count'] # 动态数目 335 follow_count = info['follow_count'] # 关注的人数 336 fan_count = info['fan_count'] # 粉丝数 337 location = info['location'] # 所在地区 338 self_description = info['self_description'] # 个人介绍 339 age = unicode(info['age']) # 年龄 340 listening_songs_num = info['listening_songs_num'] # 累计听歌总数 341 full_info = unicode(user_id) + u" " + event_count + u" " + follow_count + u" " + fan_count + u" " + location + u" " + self_description + u" " + age + u" " + listening_songs_num + u"\n" 342 f.write(full_info) 343 print(u"成功写入文件%s/commenters_info.txt" % song_or_singer_name) 344 345 # 得到某个歌手全部热门歌曲id列表 346 def get_songs_ids(self,singer_url): 347 ids_list = [] 348 html = requests.get(singer_url,headers = self.headers,proxies = self.proxies).text 349 re_pattern = re.compile(r'<a href="/song\?id=(\d+?)">.*?</a>') 350 ids = re.findall(re_pattern,html) 351 for id in ids: 352 ids_list.append(id) 353 return ids_list 354 # 得到某个歌手所有歌曲的热门评论 355 def get_singer_all_hot_comments(self,singer_name,singer_id): 356 singer_url = 'http://music.163.com/artist?id=%d' % singer_id 357 song_ids = self.get_songs_ids(singer_url) # 得到歌手所有热门歌曲id列表 358 for song_id in song_ids: 359 url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_%d/?csrf_token=" % int(song_id) 360 hot_comments_list = self.get_hot_comments(url) 361 if(os.path.exists(singer_name)): 362 self.save_to_file(hot_comments_list,u"%s/hotcomments.txt" % singer_name) 363 else: 364 os.mkdir(singer_name) 365 self.save_to_file(hot_comments_list,u"%s/hotcomments.txt" % singer_name) 366 print(u"成功写入%s的%d首歌曲!" %(singer_name,len(song_ids))) 367 368 # 在一张图中绘制多个歌曲的评论分布 369 # song_names_list 为多个歌曲名字的列表 370 # settings 为含有字典元素的列表,每个字典含有每个子图的配置项 371 def sub_plot_comments(self,song_names_list,settings,row,col): 372 n = len(song_names_list) # 歌曲总数 373 row = row 374 col = col 375 for i in range(n): 376 plt.subplot(row,col,i+1) 377 if(settings[i]['date_type'] == '%Y-%m-%d'): 378 count_file_name = u"%s/comments_num_by_Ymd.txt" % song_names_list[i] 379 else: 380 count_file_name = u"%s/comments_num_by_Ym.txt" % song_names_list[i] 381 date_type = settings[i]['date_type'] 382 min_date_Ym = settings[i]['min_date_Ym'] 383 max_date_Ym = settings[i]['max_date_Ym'] 384 min_date_Ymd = settings[i]['min_date_Ymd'] 385 max_date_Ymd = settings[i]['max_date_Ymd'] 386 x_date,y_count = self.get_xdate_ycount(count_file_name,min_date_Ym = min_date_Ym,max_date_Ym = max_date_Ym, 387 min_date_Ymd = min_date_Ymd,max_date_Ymd = max_date_Ymd,date_type = date_type) 388 389 x = [datetime.strptime(d, date_type).date() for d in x_date] 390 # 配置横坐标为日期类型 391 plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%s' % date_type)) 392 if(date_type == '%Y-%m-%d'): 393 plt.gca().xaxis.set_major_locator(mdates.DayLocator()) 394 else: 395 plt.gca().xaxis.set_major_locator(mdates.MonthLocator()) 396 plot_type = settings[i]['plot_type'] 397 if(plot_type == 'plot'): 398 plt.plot(x,y_count,color = settings[i]['color']) 399 elif(plot_type == 'bar'): 400 plt.bar(x,y_count,width=settings[i]['bar_width'],color = settings[i]['color']) 401 else: 402 plt.scatter(x,y_count,color = settings[i]['color']) 403 plt.gcf().autofmt_xdate(rotation=settings[i]['rotation']) # 自动旋转日期标记 404 plt.title(u"网易云音乐歌曲《" + song_names_list[i] + u"》" + u"评论数目分布(%s到%s)" %(x[0],x[-1]),fontsize = settings[i]['fontsize']) 405 plt.xlabel(u"日期") 406 plt.ylabel(u"数目") 407 plt.xticks(pd.date_range(x[0],x[-1],freq="%s" % settings[i]['time_distance'])) # 设置日期间隔 408 plt.subplots_adjust(left=0.2, bottom=0.2, right=0.8, top=0.8,hspace=1.2,wspace=0.3) 409 plt.show() 410 # 得到评论列表 411 def get_comments_list(self,filename): 412 with codecs.open(filename,"r",encoding='utf-8') as f: 413 lists = f.readlines() 414 comments_list = [] 415 for comment in lists: 416 if(re.match(r"^\d.*",comment)): 417 try: 418 comments_list.append(comment.split(" ",5)[5].replace("\n","")) 419 except Exception,e: 420 print(e) 421 else: 422 comments_list.append(comment) 423 return comments_list 424 425 # 绘制词云 426 # pic_path 为词云背景图片地址 427 # singer_name 为 False 时,则读取歌曲评论文件,否则读取歌手热评文件 428 # isFullComments = True 时,读取全部评论,否则只读取热评 429 def draw_wordcloud(self,song_name,singer_name,pic_path = "JayChou.jpg",isFullComments = True): 430 if singer_name == False: 431 if isFullComments == True: 432 filename = u"%s/%s.txt" % (song_name,song_name) # 全部评论 433 else: 434 filename = u"%s/hotcomments.txt" % song_name # 一首歌的热评 435 else: 436 filename = u"%s/hotcomments.txt" % singer_name 437 comments_list = self.get_comments_list(filename) 438 comments_text = "".join(comments_list) 439 cut_text = " ".join(jieba.cut(comments_text)) # 将jieba分词得到的关键词用空格连接成为字符串 440 d = path.dirname(__file__) # 当前文件文件夹所在目录 441 color_mask = imread(pic_path) # 读取背景图片 442 cloud = WordCloud(font_path=path.join(d,'simsun.ttc'),background_color='white',mask=color_mask,max_words=2000,max_font_size=40) 443 word_cloud = cloud.generate(cut_text) # 产生词云 444 if singer_name == False: 445 name = song_name 446 else: 447 name = singer_name 448 word_cloud.to_file(u"%s/%s.jpg" % (name,name)) 449 print(u"成功生成%s.jpg" % name) 450 451 # 对一首歌曲绘制其某一年某几个月的评论分布 452 # date_lists 为要绘制的月份 453 def sub_plot_months(self,song_name,DateLists,settings,row,col): 454 n = len(DateLists) 455 row = row # 行 456 col = col # 列 457 filename = u"%s/comments_num_by_Ymd.txt" % song_name 458 date_lists = [] 459 y_count = [] 460 with codecs.open(filename,"r",encoding = 'utf-8') as f: 461 lists = f.readlines() 462 del lists[0] # 删除头部信息 463 for content in lists: 464 date_lists.append(content.split(" ")[0]) # 添加日期信息 465 y_count.append(int(content.split(" ")[1])) # 添加数量信息 466 for i in range(n): 467 plt.subplot(row,col,i+1) 468 x_date = [date for date in date_lists if re.match(r"%s" % DateLists[i],date)] 469 y = [y_count[j] for j in range(len(y_count)) if re.match(r"%s" % DateLists[i],date_lists[j])] 470 x = [datetime.strptime(d, "%Y-%m-%d").date() for d in x_date] 471 plt.gca().xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d")) 472 plot_type = settings[i]['plot_type'] 473 if(plot_type == 'plot'): 474 plt.plot(x,y,color = settings[i]['color']) 475 elif(plot_type == 'bar'): 476 plt.bar(x,y,width=settings[i]['bar_width'],color = settings[i]['color']) 477 else: 478 plt.scatter(x,y,color = settings[i]['color']) 479 plt.gcf().autofmt_xdate(rotation=settings[i]['rotation']) # 自动旋转日期标记 480 plt.title(u"《%s》%s到%s" % (song_name,x[0],x[-1]),fontsize = settings[i]['fontsize']) 481 plt.xlabel(u"日期") 482 plt.ylabel(u"评论数目") 483 plt.xticks(pd.date_range(x[0],x[-1],freq="%s" % settings[i]['time_distance'])) # 设置日期间隔 484 plt.subplots_adjust(left=0.09, bottom=0.27, right=0.89, top=0.83,hspace=0.35,wspace=0.35) 485 plt.show() 486 487 # 绘制一首歌曲评论者相关信息的分布 488 def sub_plot_commenters_info(self,song_or_singer_name): 489 file_name = u"%s/commenters_info.txt" % song_or_singer_name 490 with codecs.open(file_name,'r',encoding='utf-8') as f: 491 info_lists = f.readlines() 492 del info_lists[0] # 删除头部信息 493 event_count_list = [] # 动态总数 494 follow_count_list = [] # 关注总数 495 fan_count_list = [] # 粉丝总数 496 area_list = [] # 所在地区 497 age_list = [] # 年龄 498 listen_songs_num_list = [] # 累计听歌数目 499 for info in info_lists: 500 info.replace("\n","") 501 event_count_list.append(int(info.split(" ")[1])) 502 follow_count_list.append(int(info.split(" ")[2])) 503 fan_count_list.append(int(info.split(" ")[3])) 504 area_res= re.search(re.compile(u'.*\d (.+?-.+?) .*?|.*(未知地区).*'),info) 505 if(area_res): 506 if(area_res.group(1)): 507 area_list.append(area_res.group(1)) 508 age_list.append(info.split(" ")[-2]) 509 listen_songs_num_list.append(int(info.split(" ")[-1])) 510 event_count = [0,0,0,0] 511 follow_count = [0,0,0,0,0] 512 fan_count = [0,0,0,0,0] 513 listen_songs_num = [0,0,0,0] 514 area_count = [0,0,0,0,0,0] 515 age_count = [0,0,0,0,0] 516 for content in event_count_list: 517 if(content <= 10): 518 event_count[0] += 1 519 elif(content <= 50): 520 event_count[1] += 1 521 elif(content <= 100): 522 event_count[2] += 1 523 else: 524 event_count[3] += 1 525 for content in follow_count_list: 526 if(content < 10): 527 follow_count[0] += 1 528 elif(content < 30): 529 follow_count[1] += 1 530 elif(content < 50): 531 follow_count[2] += 1 532 elif(content < 100): 533 follow_count[3] += 1 534 else: 535 follow_count[4] += 1 536 for content in fan_count_list: 537 if(content < 10): 538 fan_count[0] += 1 539 elif(content < 100): 540 fan_count[1] += 1 541 elif(content < 1000): 542 fan_count[2] += 1 543 elif(content < 10000): 544 fan_count[3] += 1 545 else: 546 follow_count[4] += 1 547 area_no_repeat_list = list(set(area_list)) # 去除重复 548 area_tuple = [(area,area_list.count(area)) for area in area_no_repeat_list] 549 area_tuple.sort(key= lambda x:x[1],reverse=True) # 从高到低排列 550 for i in range(5): # 取出排名前4的地区 551 area_count[i] = area_tuple[i][1] 552 area_count[5] = sum([x[1] for x in area_tuple[5:]]) # 前5名之外的全部地区数量 553 area_labels = [x[0] for x in area_tuple[0:5]] # 前5个地区的名字 554 area_labels.append(u"其他地区") 555 age_no_repeat_list = list(set(age_list)) # 去除重复 556 age_info = [age_list.count(age) for age in age_no_repeat_list] 557 for index,age_ in enumerate(age_no_repeat_list): 558 if(age_ != u"未知年龄"): # 排除未知年龄 559 if(int(age_) <= 17): 560 age_count[0] += age_info[index] # 00后 561 elif(int(age_)<=22): # 95后 562 age_count[1] += age_info[index] 563 elif(int(age_)<=27): # 90后 564 age_count[2] += age_info[index] 565 elif(int(age_)<=37): # 80后 566 age_count[3] += age_info[index] 567 else: 568 age_count[4] += age_info[index] # 80前 569 age_labels = [u"00后",u"95后",u"90后",u"80后",u"80前"] 570 571 for content in listen_songs_num_list: 572 if(content < 100): 573 listen_songs_num[0] += 1 574 elif(content < 1000): 575 listen_songs_num[1] += 1 576 elif(content < 10000): 577 listen_songs_num[2] += 1 578 else: 579 listen_songs_num[3] += 1 580 for i in range(6): 581 if(i == 0): 582 title = u"%s:评论者<动态数目>分布" % song_or_singer_name 583 labels = [u"0-10",u"10-50",u"50-100",u"100以上"] 584 colors = ["red","blue","yellow","green"] 585 x = event_count 586 plt.subplot(2,3,i+1) 587 plt.pie(x,colors=colors,labels=labels,autopct="%1.1f%%") 588 plt.title(title) 589 # plt.legend(labels) 590 elif(i == 1): 591 title = u"%s:评论者<关注人数>分布" % song_or_singer_name 592 labels = [u"0-10",u"10-30",u"30-50",u"50-100",u"100以上"] 593 colors = ["red","blue","yellow","green","white"] 594 x = follow_count 595 plt.subplot(2,3,i+1) 596 plt.pie(x,colors=colors,labels=labels,autopct="%1.1f%%") 597 plt.title(title) 598 # plt.legend(labels) 599 elif(i == 2): 600 title = u"%s:评论者<粉丝人数>分布" % song_or_singer_name 601 labels = [u"0-10",u"10-100",u"100-1000",u"1000-10000",u"10000以上"] 602 colors = ["red","blue","yellow","green","white"] 603 x = fan_count 604 plt.subplot(2,3,i+1) 605 plt.pie(x,colors=colors,labels=labels,autopct="%1.1f%%") 606 plt.title(title) 607 # plt.legend(labels) 608 elif(i == 3): 609 title = u"%s:评论者<地区>分布" % song_or_singer_name 610 colors = ["red","blue","yellow","green","white","purple"] 611 x = area_count 612 plt.subplot(2,3,i+1) 613 plt.pie(x,colors=colors,labels=area_labels,autopct="%1.1f%%") 614 plt.title(title) 615 # plt.legend(area_labels,loc='upper center', bbox_to_anchor=(0.1,0.9),ncol=1,fancybox=True,shadow=True) 616 elif(i == 4): 617 title = u"%s:评论者<年龄>分布" % song_or_singer_name 618 colors = ["red","blue","yellow","green","white"] 619 x = age_count 620 plt.subplot(2,3,i+1) 621 plt.pie(x,colors=colors,labels=age_labels,autopct="%1.1f%%") 622 plt.title(title) 623 # plt.legend(age_labels) 624 else: 625 title = u"%s:评论者<累计听歌>分布" % song_or_singer_name 626 labels = [u"0-100",u"100-1000",u"1000-10000",u"10000以上"] 627 colors = ["red","blue","yellow","green"] 628 x = listen_songs_num 629 plt.subplot(2,3,i+1) 630 plt.pie(x,colors=colors,labels=labels,autopct="%1.1f%%") 631 plt.title(title) 632 # plt.legend(labels) 633 plt.tight_layout() 634 plt.show() 635 636 # sub_plot_months 测试 637 def sub_plot_months_test(self): 638 song_name = u"越长大越孤单" 639 row = 3 640 col = 4 641 settings_dict = { 642 "plot_type":"plot", 643 "color":"g", 644 "bar_width":0.8, 645 "fontsize":10, 646 "rotation":50, 647 "time_distance":"5D" 648 } 649 settings = [] 650 DateLists = ['2016-04','2016-05','2016-06','2016-07','2016-08','2016-09','2016-10','2016-11','2016-12','2017-01','2017-02','2017-03'] 651 for i in range(len(DateLists)): 652 settings.append(settings_dict) 653 self.sub_plot_months(song_name,DateLists,settings,row=row,col=col) 654 655 # 绘制subplot 测试 656 def subplot_test(self): 657 song_names_list = [u"七里香",u"不要再孤单",u"All Too Well",u"刚好遇见你"] 658 settings_dict = {"date_type":"%Y-%m-%d", 659 "plot_type":"bar", 660 "fontsize":12, 661 "color":"r", 662 "bar_width":0.4, 663 "rotation":50, 664 "time_distance":"3D", 665 "min_date_Ymd":"2017-03-01", 666 "max_date_Ymd":"2017-12-31", 667 "min_date_Ym":"2013-01", 668 "max_date_Ym":"2017-12" 669 } 670 settings = [] 671 for i in range(len(song_names_list)): 672 settings.append(settings_dict) 673 row = 2 674 col = 2 675 self.sub_plot_comments(song_names_list,settings,row=row,col = col) 676 677 # plot_comments 函数测试 678 def plot_comments_test(self): 679 song_name = u"我从崖边跌落" 680 settings = { 681 "comment_type":False, 682 "date_type":"%Y-%m-%d", 683 "plot_type":"plot", 684 "bar_width":0.8, 685 "rotation":20, 686 "color":"purple", 687 "pie_colors":["blue","red","coral","green","yellow"], 688 "auto_pct":'%1.1f%%', 689 "expl" :[0,0,0.1,0.3], # 离开圆心的距离 690 "time_distance":"3D", 691 "min_date_Ymd":"2013-12-01", 692 "max_date_Ymd":"2017-12-31", 693 "min_date_Ym":"2013-01", 694 "max_date_Ym":"2017-12" 695 } 696 self.plot_comments(song_name,settings) 697 698 699 if __name__ == '__main__': 700 Processor = NetCloudProcessor() 701 Processor.plot_comments_test()
注:上面的代码无法直接运行,因为绘图时缺少必要的文件(即函数create_all_necessary_files产生的与歌曲名字或者歌手同名的文件夹),大家可以去百度云下载我已经抓取过的数据(地址:http://pan.baidu.com/s/1slS55gx)或者自行抓取。有任何问题,欢迎大家的指教。

