
Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记
- 自然语言句子的双向、多角度匹配,是来自IBM 2017 年的一篇文章。代码github地址:https://github.com/zhiguowang/BiMPM
- 摘要
这篇论文主要提出了一个双向多角度匹配的模型(BiMPM),给定两个句子P和Q,首先模型分别将二者编码成BiLSTM encoder,然后在P→Q和Q→P两个方向对编码之后的句子进行匹配,在每一个方向的匹配当中,每个句子的每个time step 都从多个不同的角度与另外一个句子的全部time steps进行匹配。然后再使用一个BiLSTM将匹配的结果聚合成一个固定长度的向量。最后基于这个固定长度的向量,再通过一个全连接层(连接sigmoid或者softmax)进行分类以及构造损失函数。文章中对BiMPM在三个任务上进行了评估,并且与其他的模型进行了对比,分别是:paraphrase identification(相似短语识别),natural language inference(自然语言推断) 和 answer sentence selection(回答句子选择)。文章证明了BiMPM 在所有的任务上都取得了state-of-the-art的结果。
- 自然语言句子匹配(Natural language sentence matching ,NLSM)是比较两个句子并且识别它们的关系的任务。
- NLSM 一般有两种架构来解决:
1. “Siamese” architecture(单一架构),其步骤是使用同一个神经网络在相同的embedding space里面将两个句子进行编码,然后仅仅依据这两个编码之后的向量来进行决策。这种方法的优点是模型一般比较简单轻量,得到的向量可以用于可视化或者聚类等任务,其缺点是在编码阶段,两个句子没有显式地交互,这可能会丢失掉一些重要的信息。
2.matching aggregation(匹配聚合),在这种框架下,一些小的单元(words,context vectors)首先被进行匹配,然后匹配的结果通过CNN/LSTM进行聚合成一个单独的向量来进行决策。这种框架可以捕捉两个句子的交互特征,因而效果要比单一架构的模型要好。
- BiMPM 属于 匹配聚合框架。
- 之前的 匹配聚合框架的局限性:
1. 只考虑了word to word 的匹配,没有考虑phrase or sentence 级别的匹配
2. 只考虑了单向的匹配
- BiMPM 对以上的两个局限性进行了改进。
- 任务的定义:
1. 相似短语识别,本质是一个二分类问题,判定两个短语/句子在语义上是否是相似的,1表示相似,0表示不相似
2. 自然语言推断,P是一个条件句,Q是一个假设句,输出有三个不同的结果{entailment, contradiction, neutral},
entailment 表示Q可以从P推断得到
contradiction 表示在P的条件下Q是错误的
neutral 表示P和Q是不相关的
3. 回答句子选择,P是问题,Q表示一个候选答案,1表示Q是P的正确答案,0表示不是正确答案。
- BiMPM 架构图

- word representstion layer(词表达层):
主要分为两个部分,
第一个部分是使用glove/word3vec 进行word embedding,对于OOV word 向量进行随机初始化,dimension=300
第二个部分是character embedding,即基于字符的embedding,具体做法是对于每个word 的character将其输入LSTM进行编码,dimension=20
然后每个sentence 的word都可以得到一个dimension=320的向量表达。
- context representation layer(上下文表达层):
使用一个BiLSTM对P和Q的context embeddings 进行编码,以便充分利用上下文信息。
- matching layer(匹配层)
模型的核心层,该层的目的是对一个句子的每个time step 和另一个句子的全部time steps 的 context embedding 进行match,然后再反过来。这里需要进行一个多角度匹配操作。
- aggregation layer(聚合层):
再使用一个BiLSTM 分别对两个句子使用四种方式进行匹配,得到四个固定长度的向量,然后再拼接这四个向量送入一个全连接层(预测层)
- prediction layer(预测层):
最后的输出层。
- Multi-perspective Matching Operation(多角度匹配操作):
四种不同的匹配操作:
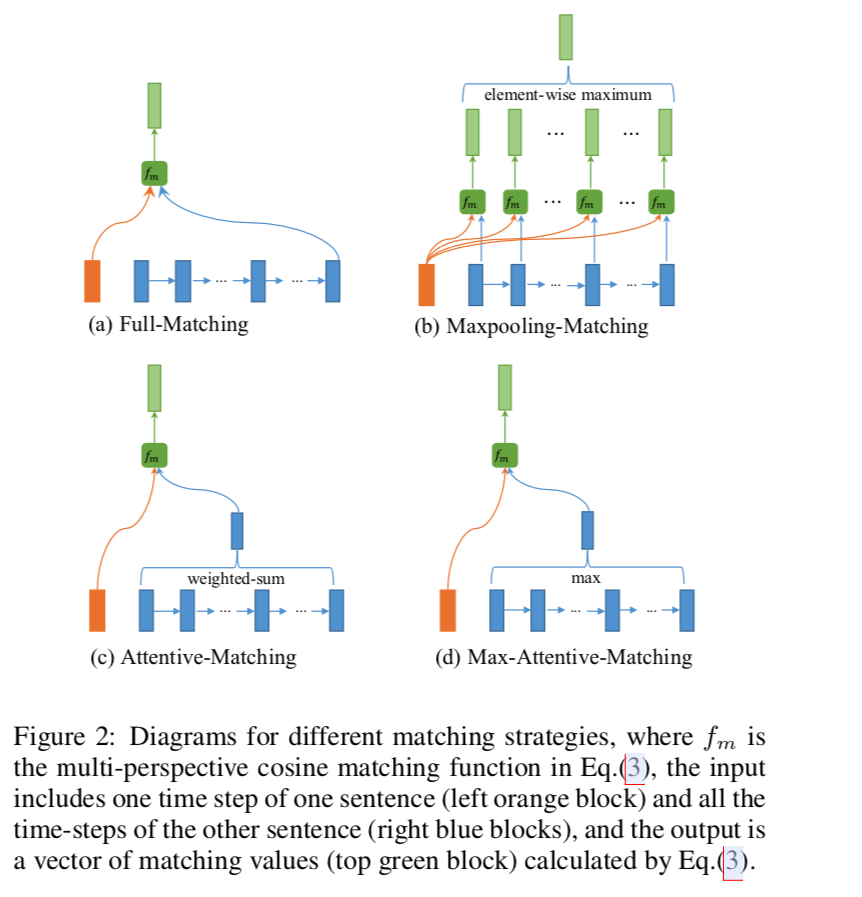
1. full matching(全匹配)
是一个句子中的每个单词,更另外一个句子中最后一个隐藏层的输出作匹配,前向的LSTM是最后一个,后向的LSTM是第一个。
2. maxpooling matching(最大池化匹配)
与另一个句子每一个隐藏层的输出作匹配,取最大值。
3. attentive matching(专心匹配)
利用这个单词的embedding和另一个句子各个单词的embeddings分别计算余弦相似度,然后用softmax归一化做成attention权重,加权求和再进行带参余弦相似度计算。
4. max-attentive-matching(最大专心匹配)
与Attentive相似,先计算出attention的权重,取其中权重最大的,做相似度匹配。
这些操作的具体计算方式参考原论文,这里略去。
- 实验参数设置:
word embedding:glove,size=300
character embedding size = 20
adma optimizer
dropout rate = 0.1
learning rate = 0.001
- Quora Question Pairs(https://www.kaggle.com/quora/question-pairs-dataset)
quroa 在kaggle上举办的一个对句子进行语义重复识别的比赛,共有40w对句子。
- quora dataset 训练/验证/测试集的选取
随机选择5000个语义相似的句子对和5000个语义不相似的句子对作为验证集,
再用同样的方式各选择5000个语义相似以及不相似的句子对作为测试集,
剩下的数据集作为训练集。
热爱编程,热爱机器学习!
github:http://www.github.com/Lyrichu
github blog:http://Lyrichu.github.io
个人博客站点:http://www.movieb2b.com(不再维护)

