数据读写流程
数据读写流程
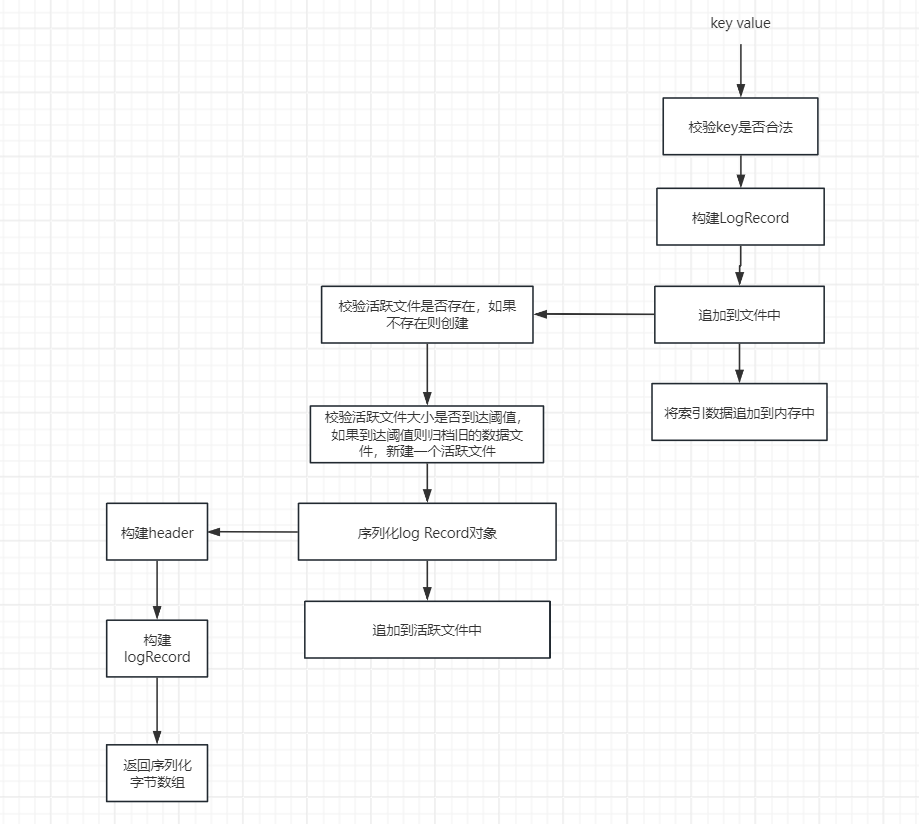
在bitcast论文中,想要获取内存中存储的数据,我们首先得获取索引数据,在索引数据中获取到文件id以及数据存储所在位置,然后根据这些信息去读取文件内容。
所有我们在进行写数据时也得有两步,第一步将key value信息持久化到文件中,第二部是将索引信息保存到内存中。
流程如下图所示
数据结构
根据bitcast论文,我们定义一下所需的数据结构信息,option中写入了一些系统的配置信息,例如数据库文件存储位置以及单文数据库文件存储大小等等。
// Db bitcask实例 面向用户的接口
type Db struct {
// 系统配置
option option
// 锁
lock *sync.RWMutex
// 活动文件
activeFile *data.FileData
// 老文件列表 只允许读 不允许写
oldFile map[uint32]*data.FileData
// 内存中存储的索引信息
index index.Indexer
}
type option struct {
// 文件存储目录
DirPath string
// 单数据文件大小阈值
FileDataSize int64
}
Put
put的业务逻辑和上面的流程图一样先构建logRecord,然后序列化并追加到硬盘中,最后将索引数据
// Put 添加kv
func (db *Db) Put(key []byte, value []byte) error {
// 判断key是否合法
if len(key) == 0 {
return errors.New("key为空")
}
// 构建logRecord
logRecord := &data.LogRecord{
Key: key,
Value: value,
Type: data.Normal,
}
// 向文件追加数据
logRecordPos, err := db.appendLogRecord(logRecord)
if err != nil {
return errors.New("文件追加失败")
}
// 将追加的索引添加内存中
db.index.Put(key, logRecordPos)
return nil
}
在我们的数据文件大小有个阈值,如果阈值超过指定大小阈值则将文件转换成旧的文件并新建一个活动文件进行读写,旧的文件只运行读不允许写。之后将数据序列化并追加到活动文件中,追加完成后将当前数据索引信息进行返回以便于
// 将KV数据追加到文件中
func (db *Db) appendLogRecord(logRecord *data.LogRecord) (*data.LogRecordPos, error) {
db.lock.Lock()
defer db.lock.Unlock()
// 如果当前活跃文件为空 则创建当前活跃文件
if db.activeFile == nil {
if err := db.setActiveFile(); err != nil {
return nil, err
}
}
// 判断文件是否到达阈值 如果到达阈值则将旧的数据文件归档,创建新的数据文件
if db.activeFile.WriteOffset >= db.option.FileDataSize {
db.oldFile[db.activeFile.FileId] = db.activeFile
if err := db.setActiveFile(); err != nil {
return nil, err
}
}
// 将记录对象序列化为二进制字节数组
encodingData, _ := data.EncodingLogRecord(logRecord)
offset := db.activeFile.WriteOffset
// 写入到文件中
err := db.activeFile.Write(encodingData)
if err != nil {
return nil, err
}
return &data.LogRecordPos{
FileId: db.activeFile.FileId,
Pos: offset,
}, nil
}
整个数据分为数据头和数据体,如下图所示:

首先先构建数据头,数据头分为四部分
- crc: 用于校验数据完整性,这个需要将除crc外的数据对象都构建出来才能进行设置。
- type: 表示数据是否被删除,如果是删除状态的话则会在合并流程将该值移除调。
- keySize: key大小
- valueSize: value大小
根据key value构建数据头之后,根据字节数构建数据体,最后计算crc校验和后进行返回。
// EncodingLogRecord 将record对象实例化为字节数组并返回长度以及序列化后的对象结果
func EncodingLogRecord(logRecord *LogRecord) ([]byte, int64) {
header := make([]byte, 15)
// 前3个字节为crc冗余校验位,该位等整个LogRecord读取出来才能进行计算,所以需要先跳过前三个字节,从第四个字节开始设置
var index = 4
header[index] = logRecord.Type
index++
keySize := len(logRecord.Key)
valueSize := len(logRecord.Value)
// 写入字节数值到header中 PutVarint会返回每次写入字节数 因为keySize和valueSize不是定长的,所以需要这样设置一些
index += binary.PutVarint(header[index:], int64(keySize))
index += binary.PutVarint(header[index:], int64(valueSize))
// 计算logRecord长度 header长度 + key长度 + value长度
var size = int64(index + keySize + valueSize)
logRecordByteArray := make([]byte, size)
// 将header数据拷贝到logRecordByteArray中
copy(logRecordByteArray[:index], header[:index])
// 将key value设置到字节数组中 因为key value存储的就是字节数组所以不需要编解码 直接设置即可
copy(logRecordByteArray[index:], logRecord.Key)
copy(logRecordByteArray[index+keySize:], logRecord.Value)
// crc校验和
crcResult := crc32.ChecksumIEEE(logRecordByteArray[4:])
binary.LittleEndian.PutUint32(logRecordByteArray[:4], crcResult)
return logRecordByteArray, size
}
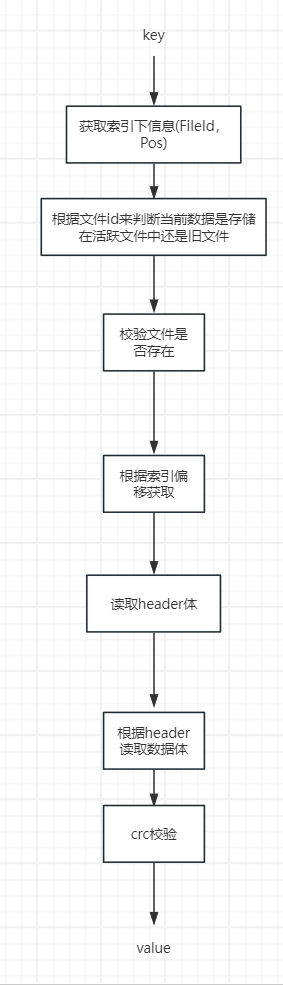
Get
知道了写的实际流程,那么读的话也很简单了,无非就是写的流程反过来,先根据key获取内存索引,根据内存索引中存储的索引信息读取目录文件数据,将二进制字节数组翻序列化为对象即可。具体流程如下图所示:
// Get 根据key获取logRecord
func (db *Db) Get(key []byte) (*data.LogRecord, error) {
db.lock.RLock()
defer db.lock.RUnlock()
// 在内存中查找key是否存在 如果不存在则直接抛出异常
keyIndex := db.index.Get(key)
if keyIndex == nil {
return nil, errors.New("索引不存在")
}
var fileData *data.FileData
// 判断文件是否为活跃文件
if keyIndex.FileId == db.activeFile.FileId {
fileData = db.activeFile
} else {
// 从old file中获取文件数据
fileData = db.oldFile[keyIndex.FileId]
}
// 判断文件是否存在
if fileData == nil {
return nil, errors.New("文件不存在")
}
record, err := fileData.ReadLogRecord(keyIndex.Pos)
if err != nil {
return nil, err
}
if record == nil {
return nil, errors.New("log record不存在")
}
if record.Type == data.Deleted {
return nil, errors.New("key已删除")
}
return record, nil
}
// ReadLogRecord 根据偏移获取logRecord
func (fileData *FileData) ReadLogRecord(pos int64) (logRecord *LogRecord, err error) {
headerDataBuffer, err := fileData.readNByte(pos, 13)
if err != nil {
return nil, err
}
// 根据最长长度解码header
header, size := DecodingLogRecordHeader(headerDataBuffer)
if header == nil {
return nil, errors.New("header为空")
}
// 拿到header之后就可以获取到logRecord的值了
recordByteArray, err := fileData.readNByte(pos+size, int64(header.KeySize+header.ValueSize))
if err != nil {
return nil, err
}
logRecord = &LogRecord{
Key: recordByteArray[:header.KeySize],
Value: recordByteArray[header.KeySize : header.ValueSize+header.KeySize],
Type: header.Type,
}
return logRecord, nil
}
// DecodingLogRecordHeader 反序列化LogRecordHeader
func DecodingLogRecordHeader(buffer []byte) (*LogRecordHeader, int64) {
// 判断字节大小是否大于4,如果不不大于4表示不足CRC冗余校验和,直接抛出异常即可
if len(buffer) < 4 {
return nil, 0
}
// varint编码读取第一个字节
//如果第一个字节为1那么表示还有剩余八个字节可读,
//如果第一个字节为0,那么表示已经是字节序列末尾了
//所以varint可以不知道字节长度就能读取字节数组
var index = 0
keySize, writeSize := binary.Varint(buffer[5:])
index += writeSize
valueSize, writeSize := binary.Varint(buffer[5+index:])
index += writeSize
logRecordHeader := &LogRecordHeader{
Crc: binary.LittleEndian.Uint32(buffer[:4]),
Type: buffer[4],
KeySize: uint32(keySize),
ValueSize: uint32(valueSize),
}
return logRecordHeader, int64(4 + 1 + index)
}
虽然道路是曲折的,但前途是光明的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律