bitcask论文详解
论文地址: https://riak.com/assets/bitcask-intro.pdf
bitcask实例
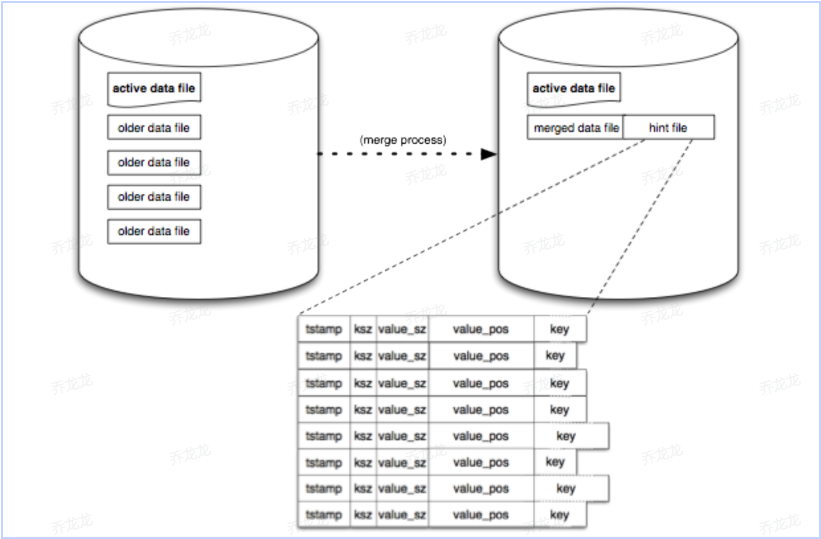
按目录来划分实例,保证只有一个实例能对该目录进行读写操作,实例下有多个文件,有一个活跃数据文件,多个旧的数据文件,当活跃文件写入到达阈值时会变为旧的数据文件并创建一个活跃数据文件,活跃数据文件允许读写操作而旧的数据文件只允许读不允许写,如下图所示,一个bitcask实例下有一个活跃文件和多个旧的数据文件。
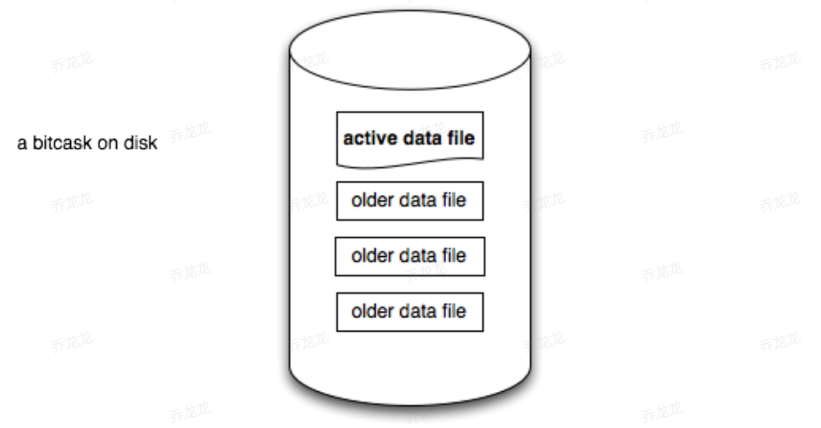
文件写入是顺序io读写的,这样做避免了多余的磁盘寻址操作,直接将数据以顺序方式追加即可。
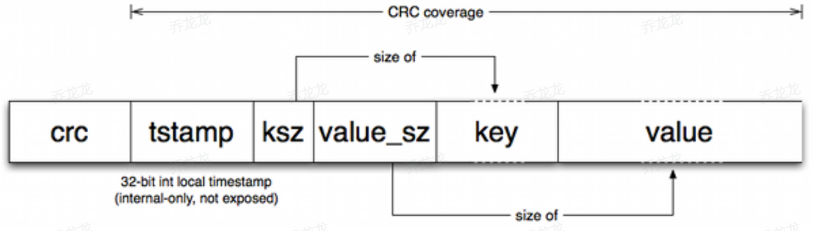
写入数据格式
- crc: 冗余校验,用于校验数据的完整性
- tstamp: 写入数据时间戳
- ksz: key size, key大小
- value_sz: value size value大小
- key: key值
- value: value值
读写都会追加到活跃文件中,即便是删除也会追加,只有再进行合并操作时才会将数据真正的删除。
所以在文件中会以一下方式进行保存数据,因为每个key value大小不同,所以存储到文件中大小也不相同。

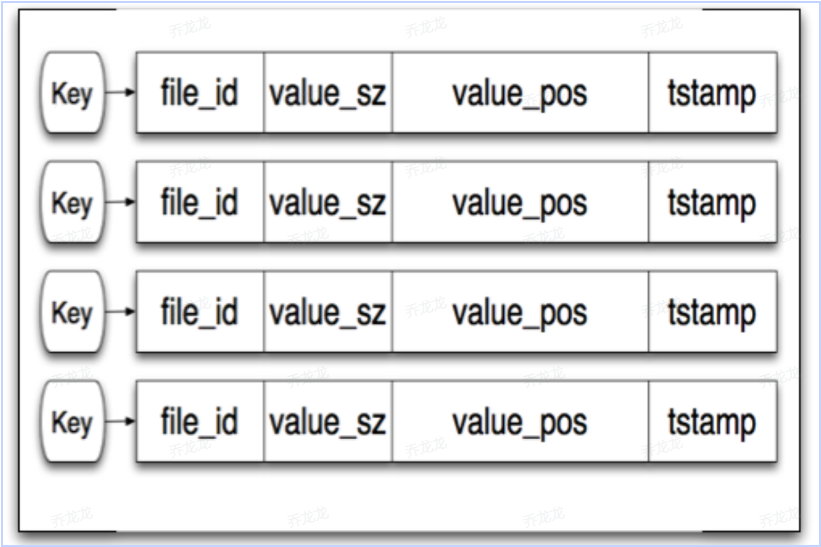
在写入数据完成后会在内存中保存一条数据便于在进行读操作时可以更快的找到指定数据,在内存中保存时可以任意选择数据库,例如hash表,b tree,跳表等,用hash表的好处是读写快,缺点是没办法进行遍历操作,所以我们选择b tree做内存数据结构来进行存储,与文件读写操作一致,只有在合并时才会将无效的key从内存中移除,数据字段如下所示 - file_id: 文件id
- value_size: 值大小
- value_pos: 值偏移
- tstamp: 写入数据时间戳
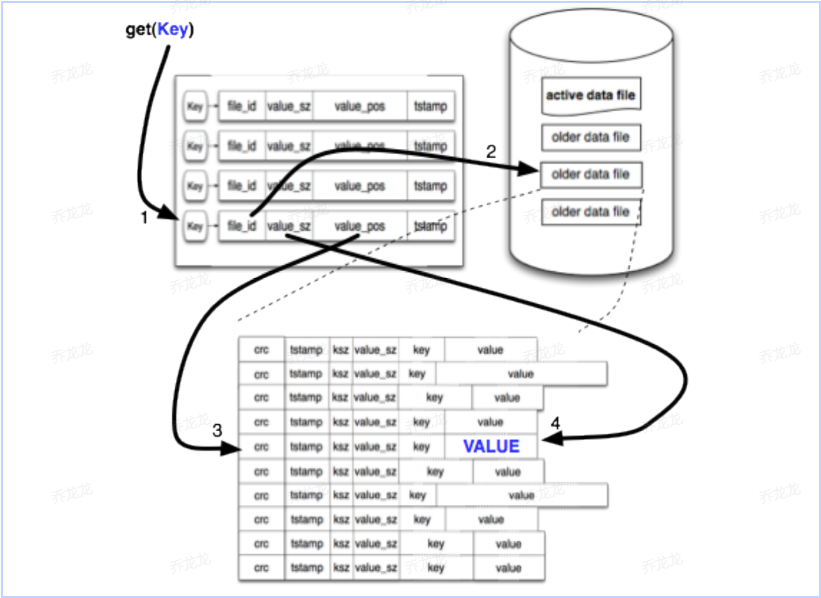
有了以上数据结构我们在读取数据的时候就会变得很高效,想要获取指定key的指定值时,首先从内存中获取到指定的文件,获取到文件之后根据内存中的偏移获取到指定值然后再进行返回。
合并
实例允许过程中会出现一系列无效的数据,例如已删除的脏数据存储在文件中,这时候就需要合并操作来将这些无效数据进行移除操作,在进行合并操作后会为每个数据文件生成一个hint文件,这个hint文件中存储的数据格式与内存中存储的索引文件格式相同,hint文件的作用是在启动时会读取hint文件的索引到内存中,这样做避免了还要读取所有的数据文件才能进行内存数据构建,加快了系统的吞吐量。
虽然道路是曲折的,但前途是光明的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2023-06-06 文件导出相关资源