分布式id
自增id
b + 树节点是有序的,所以id最好也是有序的,这样存储数据效率高一点,如果不是递增的,那讲数据存储到数据库中效率较低,还得找树的值,递增的话直接按id插入到树中即可,而乱序则还得找相应的位置才能进行插入。
- 趋势递增:总体来看顺序是递增的。
- 单调递增:下一个一定比上一个大。
- 信息安全:如果id是连续的,那么恶意用户可以根据id来判断 出总体数据量大小。
UUID
性能较高,jdk本地类就可以自己生成
缺点:
- 长度太长,在Mysql中存储的长度越短效率越高,存储到MySQL中效率较低
- UUID是无序的。存储到MySQL中还得计算树节点的位置,所以效率较低,不适合互联网。
- 不安全,可以根据UUID获取到MAC地址,最新版好像已经解决了这个问题。
- 无法进行范围查询。
雪花算法
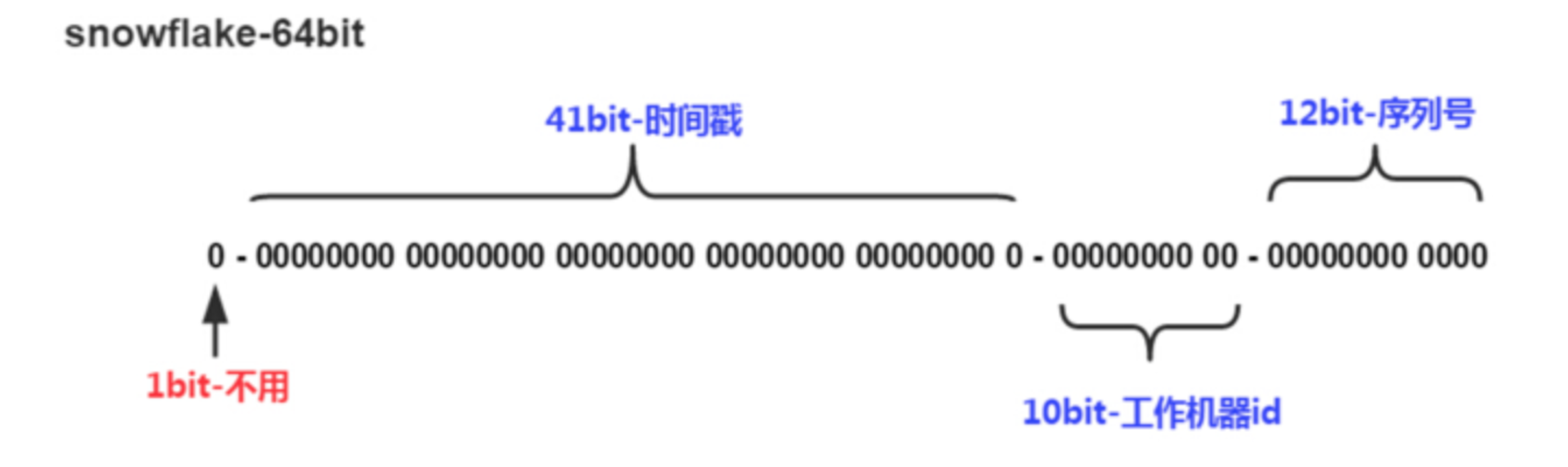
1bit: 符号位,不做处理。
4bit: 时间戳,单位是毫秒。
10bit: 工作机器id,一般是这样用的: 前五位用来表示机房id,后五位来表示每个机房下的每台机子的id,具体问题具体分析,根据项目的不同,自定义的操作也不同。
12bit: 自增id,每毫秒能生成2^12个不同的id。
优点:
- 递增
- 安全 没办法根据时间范围判断出记录条数,每毫秒可以生成2^12个id,但是不是每毫秒都能生成这么多id。
缺点:
- 由于雪花算法是根据时间戳来生成id的,所以如果时间回拨的话,可能会出现重复的问题。在日常使用计算机的过程中,计算机会定时去向服务器去同步时间,如果服务器时间与本地时间不同的话会进行设置,这时候可以出现回拨,因为CPU是通过震荡来计算当前时间的,一旦运行时间过长,那么会有误差,所以需要与服务器同步。
雪花算法变种
百度uid generator
github: https://github.com/baidu/uid-generator
分布式id服务
MySQL
之前所说的MySQL自动生成的id是无法生成全局唯一id的,所以我们可以新建一张表,中的其中一个字段专门生成id,其他表需要使用id的时候直接去这张表中获取,这样就能保证了全局唯一id。
MySQL对数据进行读写时需要对磁盘进行io,磁盘io性能并发较差。每次业务操作都需要读写一次数据库表,数据库压力会很大。
CREATE TABLE `sequence_id` (
`id` bigint NOT NULL AUTO_INCREMENT,
`service_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `stub`(`service_name` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 11 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
在进行插入时,利用REPLACE INTO按业务类型进行插入操作,replace into的作用是当表中有存储有相同的主键索引的值时,会删除旧的记录,然后插入新的记录,主键设置为自增,唯一索引设置成有业务功能,如果是同一个服务获取id时,会将旧的数据删除,生成新的自增id,这样就保证了业务与业务之间全局唯一的id。
REPLACE INTO sequence_id(stub) VALUES("user")
REPLACE INTO sequence_id(stub) VALUES("user")
REPLACE INTO sequence_id(stub) VALUES("user")
但是MySQL的数据毕竟是持久化在硬盘中,遇到高并发场景时,很容易把数据库打崩溃,遇到这种情况,可以加MySQL 副本来增加服务器,根据服务器的不同,生成不同的id,例如有两台MySQL服务器,一台服务器生成偶数id,一台服务器生成奇数id。新加机器生成id会麻烦,如果一台MySQL生成奇数id,一台MySQL生成偶数id,如果之后因为用户数量变多了,需要继续添加MySQL时,会很麻烦,需要保证其他两台MySQL生成的id与新加的MySQL id不能重复。
Redis
redis也可以实现这个操作,只要专门设置一个key了存储自增id,每次获取id的时候,直接进行自增即可。redis原子性且性能号。
INCR page_view
由于redis是内存数据库,一旦服务down调,那么服务器中保存的id会消失,而redis的持久化机制是根据规则来进行持久化,在持久化的过程中,每到达规则,这时候挂掉,每持久化数据,那么id就会丢失一部分,id可能会出现重复,所以没办法保证id不能重复。
分布式id微服务
美团leaf
美团在雪花算法中进行了加强,通过定义每次获取id数来减少对数据库的IO,每次获取指定数量的id,然后存储到内存中,id用完之后再向数据库获取id。这样做的好处是可以直接对数据库进行扩容,直接添加数据库,然后添加指定业务功能到表中即可,各表直接互不影响。
双buffer优化
毛刺现象: 一直都是平缓,突然并发变大。
例如我们每次拉取2000个id进行使用,突然并发变大,2000个id瞬间使用完毕了,这时候需要从数据库中再拉取2000个id进行使用,在这拉取的过程中,其他服务会阻塞住,指导id拉取完毕,才能继续进行业务处理。
解决方案:利用双buffer对id进行优化,两个buffer轮流切换,第一个buffer使用完毕后切换到第二个buffer进行使用,同时开一个线程缓存id到第一个buffer中。
所有的id都依赖于MySQL的可用性,当MySQL挂了的话,那么就会阻塞,没办法生成id,为了解决这个问题,可以使用MySQL主从来提升MySQL的可用性,但是这样还是有些略微丢失数据的情况,例如在同步的过程中,从挂了,没同步到数据,最终会导致数据不一致。如果要保证MySQL的强一致,通过搭建MGR集群,使得MySQL各数据库之间数据强一致,但是这样会对性能有略微影响。
雪花算法
由于生成自增id安全性较差,所以可以使用leaf + 雪花算法解决这个问题。
遇到时钟回拨的问题的话,则需要配合zookeeper来进行校验,每个分布式id服务会将时间戳注册到zookeeper中,在生成id的时候判断几个服务之间的时间戳相差数,如果到达1毫秒,那么服务可能遇到了时钟回拨,需要停调服务或sleep一段时间服务。
