数据模型与查询语言
在系统的开发过程中,我们需要根据需求对现实系统中的东西进行抽象,根据这些抽象构建系统中对象或是数据结构,对这些对象或是数据结构进行操作,最终完成业务需求。例如一个订单服务,需要涉及商品库存、订单,那么需要对商品的库存情况构建数据模型,例如商品有id、名称、库存、分类、介绍图片等等字段。订单也是一样,根据订单情况构建相应的数据模型,例如订单有id、订单名称、金额等等。对数据模型构建完成后,需要操作数据模型并完成具体的业务功能,订单服务则是购买商品,用户在购买商品时,商品库存 - 1并创建订单信息,这样一来就完成了相应的业务功能了。
复杂的应用可能会在API中调用其他的API来完成业务功能,例如微服务架构,有些服务复杂些,需要调用其他服务才能完成具体的业务功能。
对于应用层开发人员来说,需要观察现实时间,根据现实世界中的对象进行建模,通过操作这些对象来完成具体的业务功能。
当需要存储这些数据时,需要以构建某种格式的数据模型来进行存储,例如JSON、XML等。
多个系统进行交互时已经工程师需要规定上述存储的JSON、XML转换成字节流进行交互。
关系模型与文档模型
科德十二定律
对象关系不匹配
在关系型数据库中,通过业务关系将数据存储在各张表中,应用层在代码中将表组合成一对多、多对多时需要一个转换层,一些ORM框架减少了转换层所需的代码量,例如mybatis根据在
类中映射一对一或是一对多关系,在配合相关的多表查询语法和映射关系,自动会将查询结果映射成指定对象。如下
@Data
@SuppressWarnings("serial")
public class User extends Model<User> {
@ApiModelProperty(value = "主键", position = 1)
private String id;
@ApiModelProperty(value = "用户名", position = 2)
private String userName;
@ApiModelProperty(value = "密码", position = 3)
private String password;
@ApiModelProperty(value = "昵称", position = 4)
private String nickName;
@ApiModelProperty(value = "姓名", position = 5)
private String name;
@ApiModelProperty(value = "身份证号码", position = 6)
private String cardCode;
@ApiModelProperty(value = "头像地址", position = 7)
private String avatar;
@ApiModelProperty(value = "手机号码", position = 8)
private String telephone;
@ApiModelProperty(value = "邮箱", position = 9)
private String email;
@ApiModelProperty(value = "性别", position = 10)
private Integer gender;
@ApiModelProperty(value = "企业id", position = 11)
private String plantId;
@ApiModelProperty(value = "用户来源id", position = 12)
private String sourceId;
@ApiModelProperty(value = "用户来源", position = 13)
private String source;
@ApiModelProperty(value = "是否管理员 0是 1否,默认为1", position = 14)
private Integer admin;
@ApiModelProperty(value = "标志 0代表存在 1代表删除", position = 15)
@TableField(fill = FieldFill.INSERT)
private Integer deleted;
@ApiModelProperty(value = "创建时间", position = 16)
@TableField(fill = FieldFill.INSERT)
private Date createTime;
@ApiModelProperty(value = "更新时间", position = 17)
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
@TableField(exist = false)
@ApiModelProperty(value = "用户角色", position = 18)
private Role userRole;
}
在类中用户与角色的关系是一对一,在user中定义了一个角色的对象,并在xml中定义它们之间的映射关系,在进行查询时会自动进行多表查询并将结果映射到对象中,这样一样来就减少了多表之间转换所需的代码。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.tracetech.envprotection.modules.sys.mapper.UserMapper">
<resultMap type="cn.tracetech.envprotection.modules.sys.domain.entity.User" id="UserMap">
<result property="id" column="id" jdbcType="VARCHAR"/>
<result property="userName" column="user_name" jdbcType="VARCHAR"/>
<result property="nickName" column="nick_name" jdbcType="VARCHAR"/>
<result property="name" column="name" jdbcType="VARCHAR"/>
<result property="cardCode" column="card_code" jdbcType="VARCHAR"/>
<result property="avatar" column="avatar" jdbcType="VARCHAR"/>
<result property="telephone" column="telephone" jdbcType="VARCHAR"/>
<result property="email" column="email" jdbcType="VARCHAR"/>
<result property="gender" column="gender" jdbcType="INTEGER"/>
<result property="plantId" column="plant_id" jdbcType="VARCHAR"/>
<result property="admin" column="admin" jdbcType="INTEGER"/>
<result property="deleted" column="deleted" jdbcType="INTEGER"/>
<result property="createTime" column="create_time" jdbcType="TIMESTAMP"/>
<result property="updateTime" column="update_time" jdbcType="TIMESTAMP"/>
</resultMap>
<resultMap id="userRoleMap" type="cn.tracetech.envprotection.modules.sys.domain.entity.User">
<id column="user_id" property="id" />
<result column="user_name" property="userName" />
<result column="nick_name" property="nickName" />
<result column="name" property="name" />
<result column="card_code" property="cardCode" />
<result column="avatar" property="avatar" />
<result column="telephone" property="telephone" />
<result column="email" property="email" />
<result column="gender" property="gender" />
<result column="plant_id" property="plantId" />
<result column="admin" property="admin" />
<result column="source" property="source" />
<result column="source_Id" property="sourceId" />
<result column="user_deleted" property="deleted" />
<result column="user_create_time" property="createTime" />
<result column="password" property="password" />
<result column="user_update_time" property="updateTime" />
<association property="userRole">
<id column="role_id" property="id" />
<result column="tole_name" property="name" />
<result column="role_deleted" property="deleted" />
<result column="role_create_time" property="createTime" />
<result column="remark" property="remark" />
<result column="update_time" property="updateTime" />
<result column="role_name" property="name" />
</association>
</resultMap>
<select id="selectUserRoleByUseId" resultMap="userRoleMap">
SELECT
t1.id AS user_id,
t1.user_name,
t1.`password`,
t1.nick_name,
t1.`name`,
t1.card_code,
t1.avatar,
t1.telephone,
t1.email,
t1.gender,
t1.plant_id,
t1.admin,
t1.source,
t1.source_id,
t1.deleted AS user_deleted,
t1.create_time AS user_create_time,
t1.update_time AS user_update_time,
t3.id AS role_id,
t3.deleted AS role_deleted,
t3.create_time AS role_create_time,
t3.remark,
t3.update_time AS role_update_time,
t3.`name` AS role_name
FROM
t_user t1,
t_user_role t2,
t_role t3
WHERE
t1.id = t2.user_id
AND t2.role_id = t3.id
AND t1.deleted = 0
AND t3.deleted = 0
AND t1.id = #{id}
</select>
</mapper>
如下图所示,多张表依靠user_id组成一个完整简历信息,每张表之间有着对应关系,例如一对一、一对多关系,例如简历中的教育有多个教育经历,这个就属于一对多,如下图所示
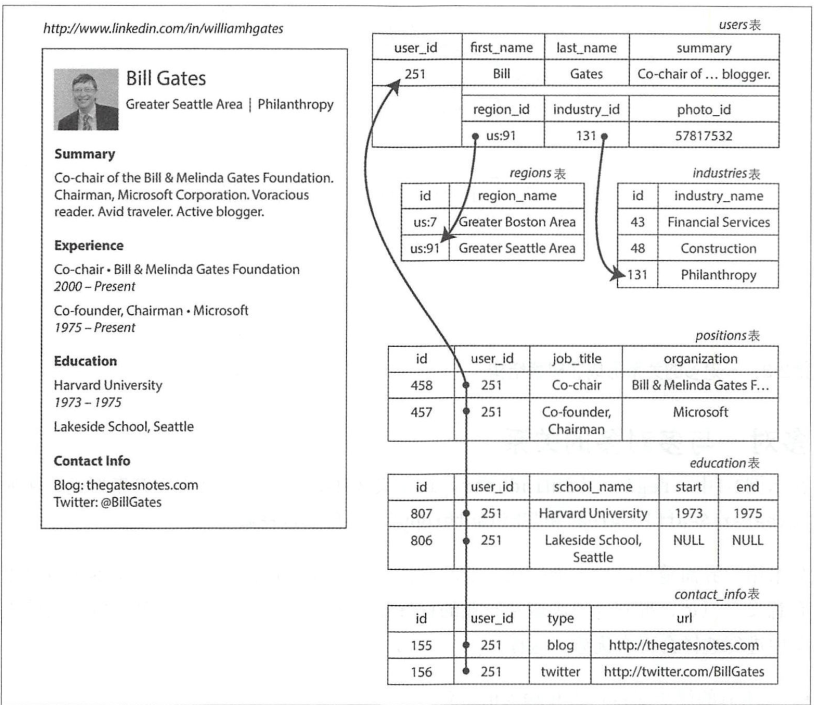
在存储数据的时候有以下几种解决方案:
- 将多张表拆开,以外键的方式进行引用,如上图的
user_id就作为外键来将表之间关联起来。 - 之后的SQL标准对结构化数据类型有了支持,例如MySQL最新的8.0就允许字段的数据类型为
JSON,可以根据MySQL的语法来对JSON进行查询。 - 最后一种方法我觉得用的也比较少,直接将
JSON以文本的方式直接存储到数据库中,之后使用的时候再由应用层代码层解析,对于该方法,并不能使用SQL条件查询语句对结果进行过滤。
以上是以关系型数据库的方式存储多表信息,我们还可以使用文档的方式进行存储,数据结构为JSON,以JSON的方式存储多表数据,每个字段都可以嵌套数组、对象,如果简历文档格式的话,如下实例所示:

以JSON的方式存储数据有一个好处就是减少了代码与存储层之间的阻抗失配,应用层读取的时候之直接将JSON转换为对象即可。
JSON存储将所有的数据都保存到一个地方中,比关系型数据库存储局部性更好,如果想要查询一个简历文档数据,直接根据id就可以查询到所有数据,而关系型数据库如果有多张表直接进行关联,查询起来会有些混乱。
多对一以及一对多关系
在以上实例中的region和industry都是以ID的方式存储数据而不是直接以文本的方式存储数据,这样做的好处是
- 所有简历中存储的数据都是一致的,由于数据是由ID进行关联,所以可以根据相同的ID获取相同的数据。
- 避免歧义,如果不同的ID关联的数据相同,那么它们也不是一个东西,避免了起义,世界上有两个相同名字的地方,根据ID的不同可以分别关联不同的地方。
- 易于更新:只有将ID的关联的数据进行更新之后,其他的地方也就发生改变了。
- 本地化支持:可以根据规范的ID方便翻译成本国家所通用的数据。
- 检索支持:由于ID是以规范的方式进行存储,搜索引擎在搜索数据时可以根据规范检索出指定数据。
在应用开发时,如果数据库不支持连接,需要手动多次查询才能查询出联结信息,这样做无非就是将数据库完成的操作转移到应用层代码而已,对于一个多对多操作,需要先将用户id查询出,在根据用户id查询中间表,在根据中间表信息查询出另一张表的信息,这样做的话会使得应用层对数据库交互变多,应用性能会变差,如果查单个id还好,如果是多条记录联表查询的话性能可想而知,指数级的下降。
即便项目在刚开始时的数据模型很适合文档模型,但是随着需求与项目的不断变化,在未来可能会有联合查询的需求,这样改起来可能会很困难。
层次模型
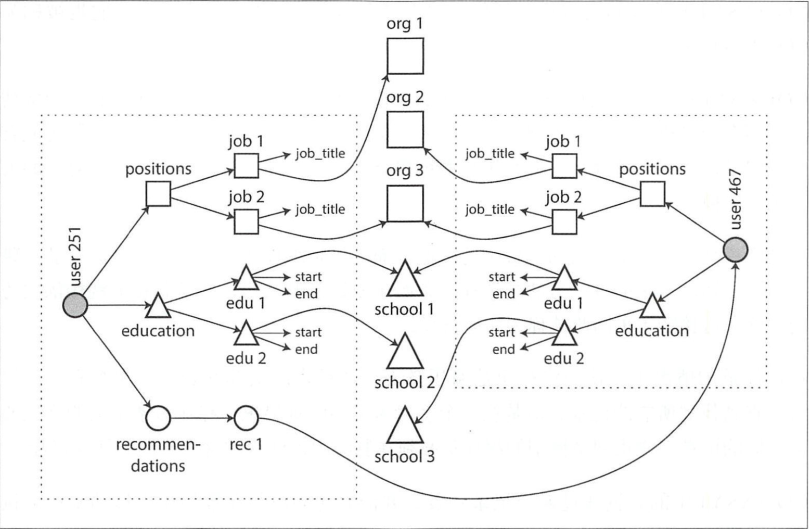
层次模型类似文档模型,都是利用子节点对父节点进行扩展的,如上图所示,org下有多个子节点,org下的job1又有多个子节点,这种模型已经将一对多的数据都设置好了,所以它可以很好的支持一对多查询。它没办法很好的支持多对多查询,因为每个节点都有单独的父节点,而每个父节点又有多个子节点,这种数据库限制了层次模型无法进行多对多连接查询。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!