JMM与线程三大特性
并发与并行
并发
在早期单核CPU中,没办法同时运行多条指令,只能将多个应用程序分成不同的时间片,由于时间片切换的速度很快,所以看起来就像是多个应用程序同时运行。并发就是一个时间点只有一条指令再执行。
并行
在现代cpu中有了多核多线程的概念,可以在不同的核心中执行不同的指令,不需要切换时间片。并行就是在一个时间点中有多条指令在执行
并发三大特性
可见性问题
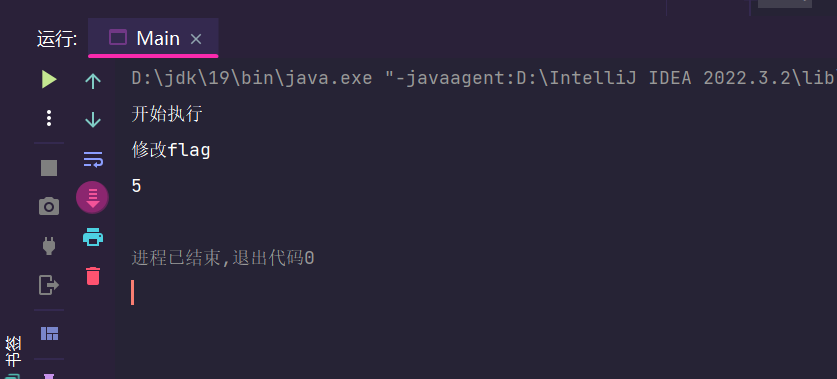
线程修改对象之后没办法想数据共享到其他线程中,如下类,run方法死循环执行,falg变为false
public class Task {
private boolean flag = true;
private int count = 0;
public void refresh() {
System.out.println("修改flag");
flag = false;
}
public void run() {
System.out.println("开始执行");
while (flag) {
count++;
}
System.out.println(count);
}
}
我们使用main方法开线程来分别执行这两个方法
public class Main {
public static void main(String[] args) {
Task task = new Task();
new Thread(() -> {
task.run();
}).start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
task.refresh();
}).start();
}
}
在执行过程中线程b明明修改了falg的值却无法跳出循环,这个就属于可见性问题,多线程修改对象中的值无法进行共享到其他线程中。
线程有6个原子操作,分别是:
- read(读取) 读取主内存的变量并传输到线程的工作内存中。
- load(加载) 将使用read读取到内存变量加载到本地内存中。
- use(使用) 使用本地内存中存储的变量,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值) 命令执行完毕之后需要将值赋值回本地内存中。
- store(存储) 将本地内存中的变量传送到主内存中,便于之后执行write操作
- write(写) 将store加载的值写入到变量中
我们的程序执行时如下图所示
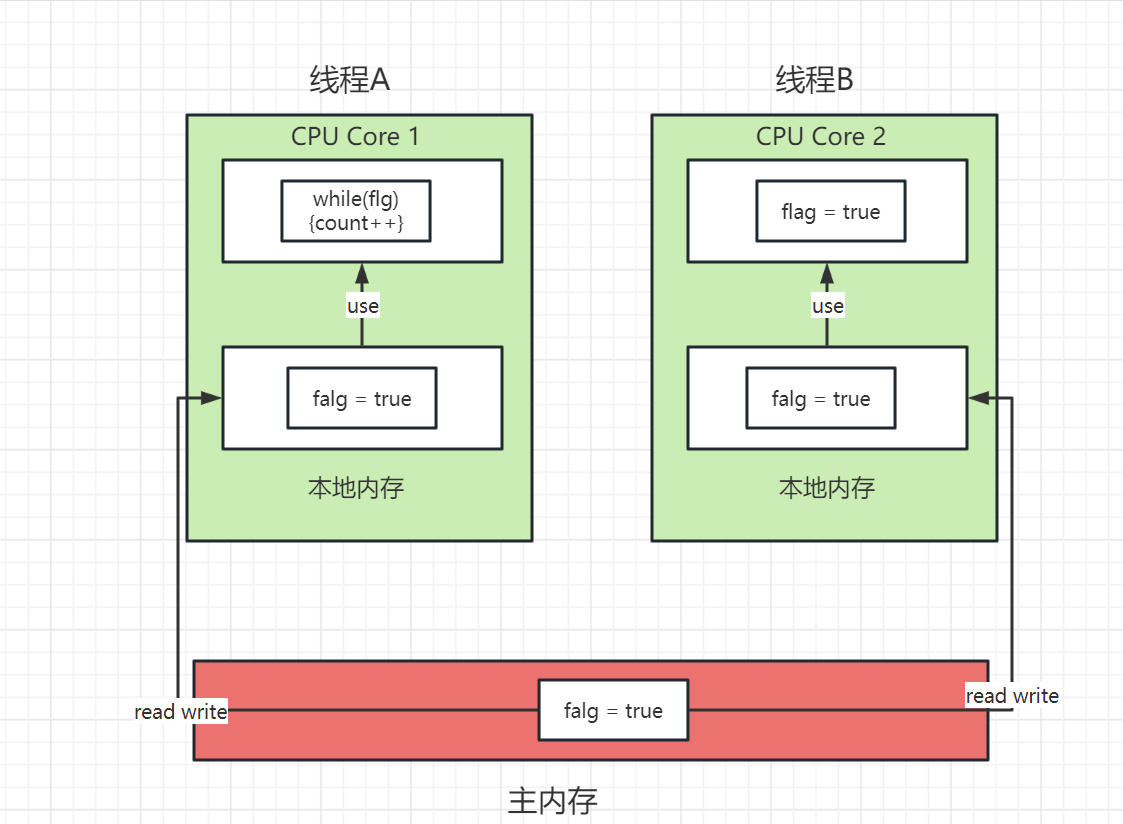
步骤如下:
-
首先将主内存中的变量使用read和write操作将变量加载到主内存中
-
加载完毕后cpu核心使用本地内存中的变量执行业务逻辑。
-
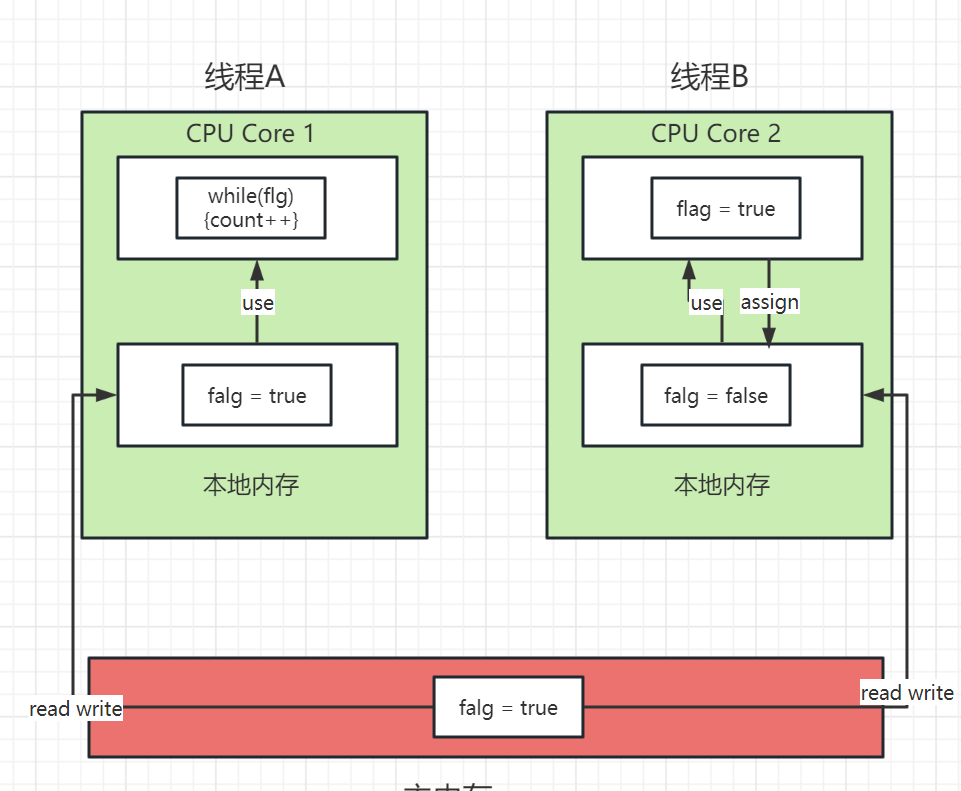
在线程B执行业务罗技之后会使用assign写会到本地内存中,如下图所示
-
之后还得需要使用store write将本地内存中的数据协会到主内存中
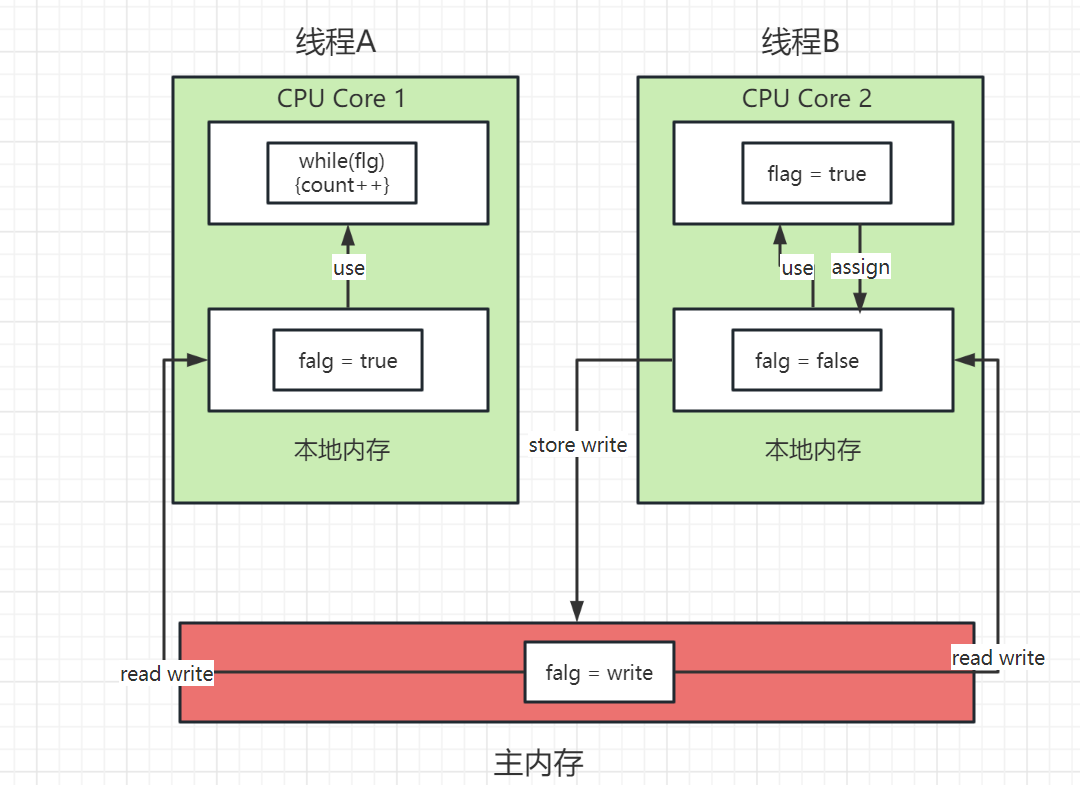
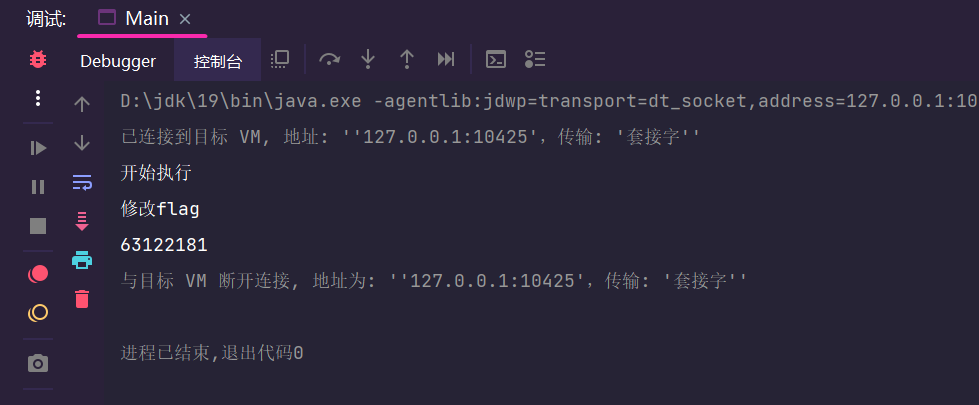
在执行的过程中,线程b修改完变量后刷新到主内存,而前程a还是用的拷贝的旧缓存数据,这就导致了无论线程b怎么修改,线程a一直死循环的问题。
while(true)的优先级比较高,即便时间片释放while(ture)还是会立即抢到时间片,看起来就是一直占有时间片,别的线程则会抢不到资源会一直阻塞,最终导致死锁问题。
如果变量一直被使用则不会立即刷新到主存中,比如while(flag)操作,而长时间不用的则会清除本地内存中的变量,然后拉取新变量,比如在执行run方法时sleep一下,由于变量短时间不会用,清除掉本地内存的flag,在从flag中拉取新的flag,这时候就跳出循环了,如下图所示
public void run() {
System.out.println("开始执行");
while (flag) {
count++;
System.out.println(count);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println(count);
}
由此可知,如果想要保证线程的可见性,那么只要清除本地内存中的数据,然后从主内存中拿到最新的数据即可。
又以下几个方案:
- Thread.yield();清除时间片
在清除时间片的时候会保存现场,就是记录当前寄存器的值和PC的值,如果发生了写操作,还需要写会到主内存中,之后清空本地内存,执行其他线程,其他线程执行完毕后又会切换到本内存,加载上下文,由于本地内存中的数据已经被清除了,还需要从主内存中拉取到最新的数据,这样就保证了线程的可见性。
public void run() {
System.out.println("开始执行");
while (flag) {
count++;
Thread.yield();
}
System.out.println(count);
}
- 在变量中添加volatile
volatile在JDK的源码中使用了内存屏障,而内存屏障的底层原理是使用了汇编语言的Lock前缀指令,对修饰volatile的变量,如果发生了修改则会强制使所以cpu核心中的和该变量有关的本地内存失效并将数据写入到主内存中以及将cpu cahche中存储的数据写会到内存中,这样一来别的线程就可以从主内存主拿到最新的数据保存到本地内存,就可以保证线程的可见性。 - synchronized和LockSupport.unpark也是使用内存屏障来保证线程可见性。
CPU cache
缓存的速度L1最快,其次是L2、L3
局部性原理
空间局部性:一般处理器都是顺序读取的,指令和地址一般也是顺序存储的,所以一般会将周围的指令都一并读取,所以根据空间局部性原理,顺序读取效率高写。
时间局部性:刚执行过的指令处理器会认为是热点数据,不久后会被再次执行,一般为循环操作会引发时间局部性。
CPU三级缓存如下图所示
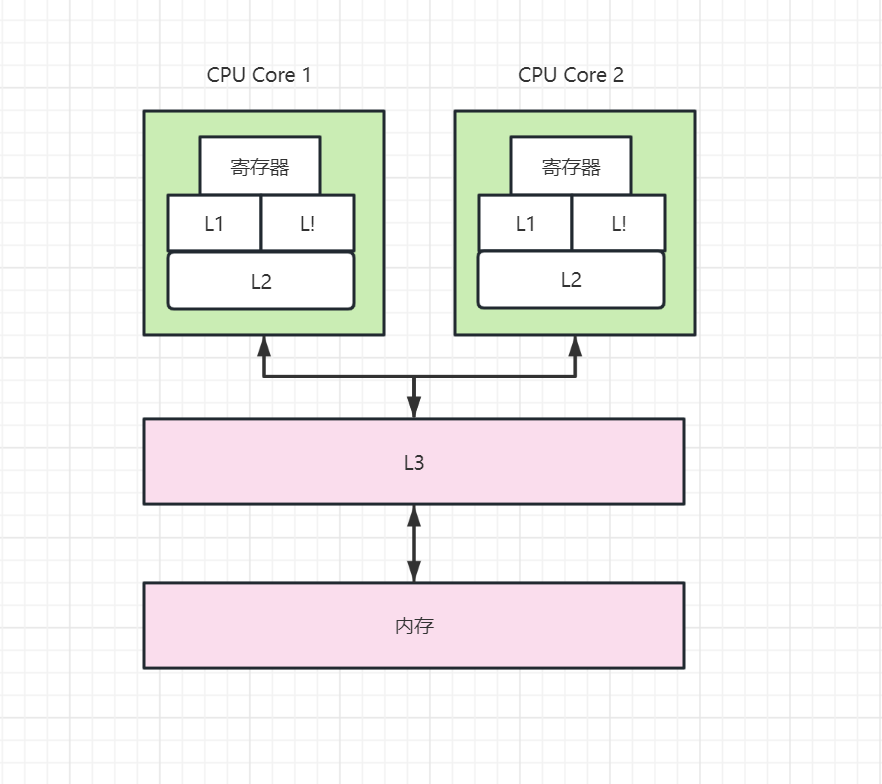
L1被切成了两部分 一部分用于存储指令 一部分用于存储数据
L3在cpu核心外面,而不是cpu外面
L1可以读写L2的缓存 L2也可以读写L1的缓存 L3可以读写L2的缓存 L2也可以读写L3的缓存,L3可以读写内存,内存也可以读写L3缓存
两个线程同时对一个变量执行操作时会引发以下问题
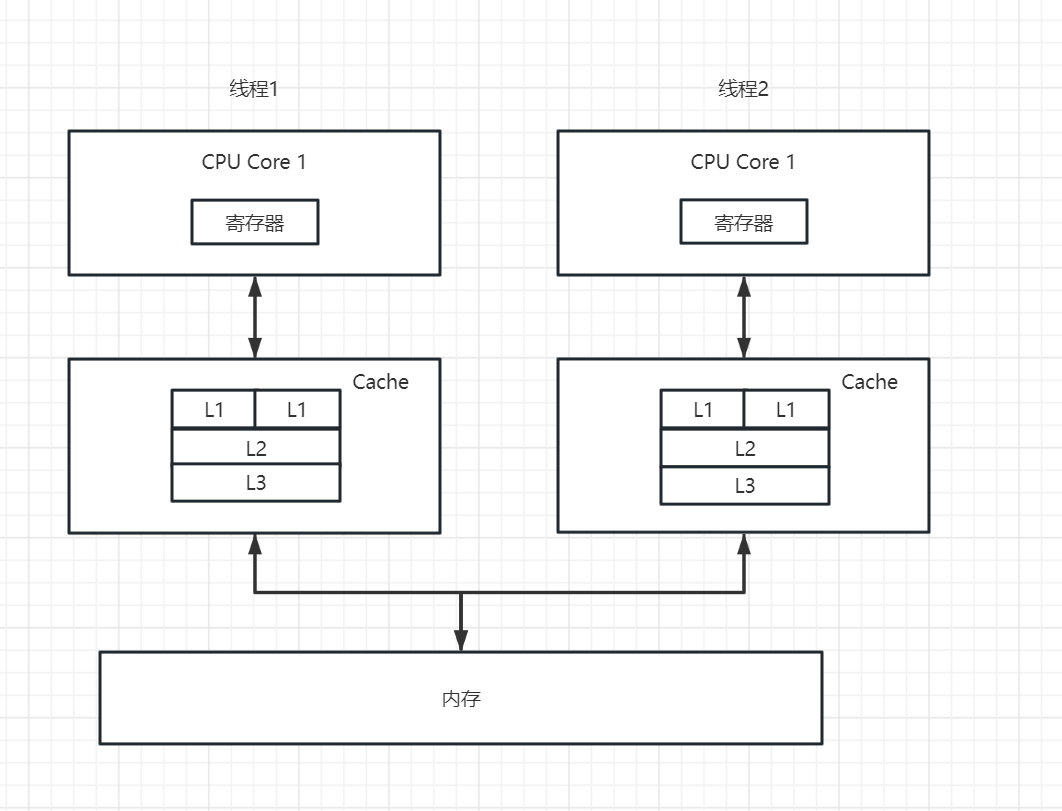
在内存中有保存便x = 5,线程1需要计算x + 3,线程2需要计算 x + 4,因为两个线程的cpu核心执行快慢的程度,会有以下几种可能:
-
- 线程1执行的快,执行完x + 3之后回写回内存中,之后线程2因为执行的比较慢,执行完毕后覆盖了线程1 x + 3的执行结果,这时候x = x + 4 = 9
-
- 一样的线程2执行的快,这时候线程1覆盖了线程1的值,这时候结果 x = x + 3 = 7
但是我们想要的结果是x = x + 3 + 4 = 11,这么一算,不满足我们当前的业务需求,我们需要内存变量修改之后使得其他cpu core的线程也能感知到,这时候就需要缓存一致性协议了。
- 一样的线程2执行的快,这时候线程1覆盖了线程1的值,这时候结果 x = x + 3 = 7
MESI
MESI一致性协议重要是针对缓存行数据的,缓存行是缓存中最小的单位,MESI具体含义如下所示。
- M: 修改
- E: 独占
- S: 共享
- I: 无效
当一个线程加载了内存中的变量时,会先将变量加载到缓存中,并将状态更改为E,当另一个线程也使用到这个变量内存数据时,也会将数据加载到另一个核心的cache中,这时候会将状态修改为S状态,如果变量发生修改时,为了避免cpu核心中的其他变量修改缓存数据,会对缓存数据进行加锁,然后写回到内存中,这时候是M状态,并通过总线窥探机制告诉其他cpu核心使用的该内存的缓存该变量已经发生修改并使之失效,此时改为I状态
由于volatile底层是根据缓存一直性保证线程的可见性的,如果volatitle变量过多时,需要不断的对内存中的数据进行嗅探,容易占用大量的总线带宽,最终会导致总线风暴我问题。
早期CPU没有实现缓存一致性协议则无法使用EMSI
因为MESI是应用于单缓存行的,如果存储的数据太大,跨缓存行,那么也无缓存一致性。
伪共享
有以下代码,Pointer类中有两个变量分别是x和y,它们都是由volilate修饰的
public class Pointer {
public volatile long x = 0L;
public volatile long y = 0L;
}
在main方法中两个线程分别执行以下语句
public static void main(String[] args) throws InterruptedException {
long l = System.currentTimeMillis();
Pointer pointer = new Pointer();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.x++;
}
});
Thread thread = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.y++;
}
});
thread1.start();
thread.start();
thread1.join();
thread.join();
System.out.println(System.currentTimeMillis() - l);
}
Pointer中存储了两个long类型的变量,总计16个字节,而缓存行大小一般为64个字节,在执行main方法时会有以下几个操作:
- 首先两个线程会分配到不同的cpu核心上去,但是由于类对象中的两个long类型的成员变量不到64字节,所以会组成一个缓存行。
- 线程1对变量进行修改时,根据MESI缓存一致性协议,在线程1修改完毕后,会将线程2的变量置为无效状态,然后再去主内存中拉取最新的数据。
这样做会使明明另一个变量没有做出修改,还需要从主内存中拉取新数据,浪费系统资源。
解决方案:
将变量中间填充一些变量,使之变成两个缓存行即可。
public class Pointer {
public volatile long x = 0L;
public long a, b, c, d, e, f, g, h;
public volatile long y = 0L;
}
如果是JDK8版本下,可以使用Contended注解,在JDK9以及9之后sun.misc.Contended没有了,所以JDK官方都不建议使用了,那最好不要使用。
优化前执行时间

优化后执行时间

由此可见,执行速度还是蛮快的。
有序性
as-if-serial
为了优化系统的执行效果,会对指令进行重排序,但执行指令重排序的前提是执行结果不能被改变,比如以下代码
x = 12;
y = 14;
z = x + y;
在进行指令重排序时可能将 x = 12 和 y = 14进行互换顺序,但不能将 y = 14 移动到 z = x + y后,这样做会改变运行结果。
happen-before
根据happen-before规则可以判断数据是否存在竞争、线程是否安全。
volatile:修改操作在读操作之前。
锁:unlock在lock之前
传递规则:如果a在b之前,b在c之前,那么a一定在c之前执行。
线程启动规则:如果线程a在执行过程中启动了线程b,那么线程a修改共享变量对线程b也是可见的。
线程终结规则:假定线程A在执行的过程中,通过制定ThreadB.join()等待线程B终止,那么线程B在终止之前对共享变量的修改在线程A等待返回后可见。
禁止指令重排序
volatile可以禁止指令重排序的功能。
双重检查锁
public class Singleton {
private static Singleton uniqueSingleton;
private Singleton() {
}
public Singleton getInstance() {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton();
}
return uniqueSingleton;
}
}
以上是一个单例模式的创建类,如果在多线程中这样写并不能保证只有一个对象能被创建,多个线程进入uniqueSingleton = new Singleton();也是有可能的。所以需要加锁
public class Singleton {
private static Singleton uniqueSingleton;
private Singleton() {
}
public Singleton getInstance() {
if (null == uniqueSingleton) {
synchronized (Singleton.class) {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton(); // error
}
}
}
return uniqueSingleton;
}
}
但是这样做还是有问题,虽然线程不会多次进入if判断条件了,但是还有一个问题,就是JVM会对指令进行重排序,创建对象有以下几个步骤
- 分配内存空间
- 初始化对象
- 将对象指向刚分配的内存空间
经过指令重排序2和3可能进行颠倒,这时候分配完内存空间表示uniqueSingleton不为空了,另一个线程获取的uniqueSingleton对象还为初始化对象完成,会获取一个错误的对象,所以要加volatile来禁止指令重排序
public class Singleton {
private volatile static Singleton uniqueSingleton;
private Singleton() {
}
public Singleton getInstance() {
if (null == uniqueSingleton) {
synchronized (Singleton.class) {
if (null == uniqueSingleton) {
uniqueSingleton = new Singleton();
}
}
}
return uniqueSingleton;
}
}
内存屏障
使用内存品质可以禁止指令重排序
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
原子性
由于volatile底层采用MESI缓存一致性协议锁缓存行,而缓存行大小一般为64字节,大于64字节那么就无法保证原子性了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律