MySQL索引已经数据结构相关
为什么要使用索引
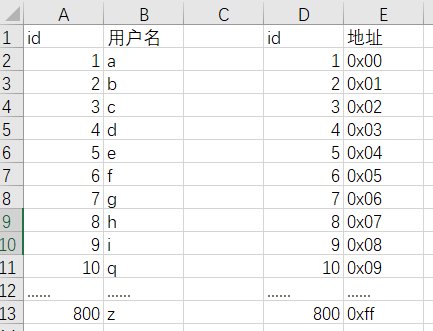
如果不使用索引的话,检索数据得逐行进行匹配,匹配成功才进行返回,而使用索引的话,可以将每行的地址进行保存,并将它们以某种数据结构的方式进行保存,可以极大的优化了检索数据,比如有800条数据,如下表所示。

如果想要对用户名为h的数据进行查询,不使用索引的情况下逐行匹配需要检索8次才能查询到数据。
而使用索引情况下,可以将索引与数据地址进行绑定,并以某种数据结构进行保存,以AVL平衡二分查找树举例。
索引地址对应着右边存储的数据所在的硬盘地址
建立一个AVL
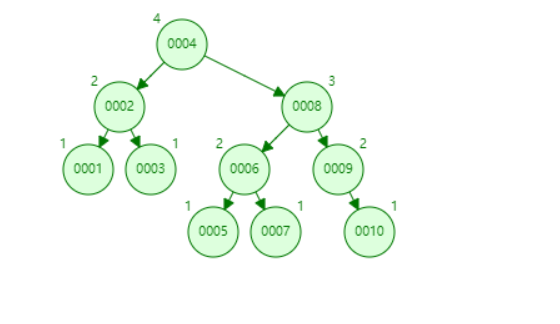
查找索引为8的元素只需要2次就可以查到,但是二叉树有个缺点就是,随着存入的数据越来越多,树的高度则是越来越大,会使得检索效率下降,解决树的高度的问题可以采用B-Tree的方式进行数据保存,一个节点多存储几个数据即可
比如下面这种格式
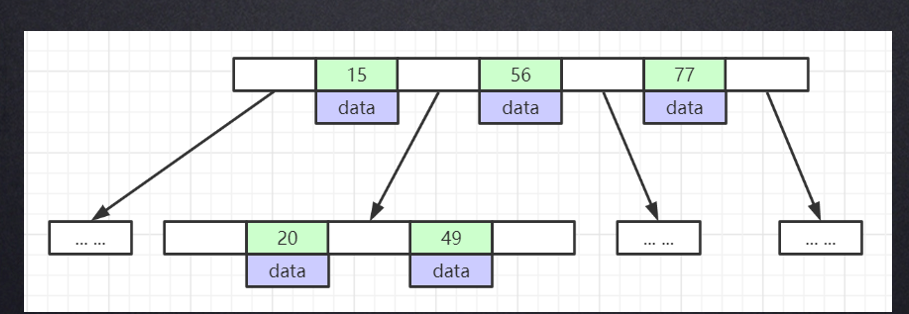
这个关键字为4,表示子树必须为4个
在这条子树中,最左边那条的取值范围为-∞, 15,再后面那条的取值范围为15, 17, 之后那条是17, 最后那条取值范围为19, +∞。
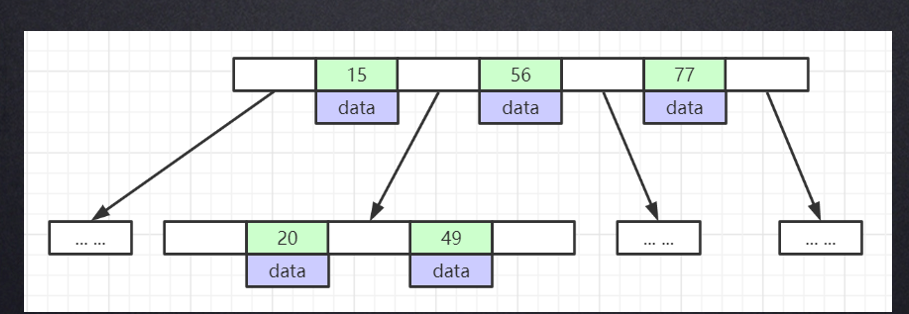
但是B Tree有个缺点就范围查询时会回旋,比如要查大于15的元素时,会找到15然后到16,然后再返回15继续查找,这样会使得吞吐量下降,B+Tree可以解决这个问题。
B+Tree
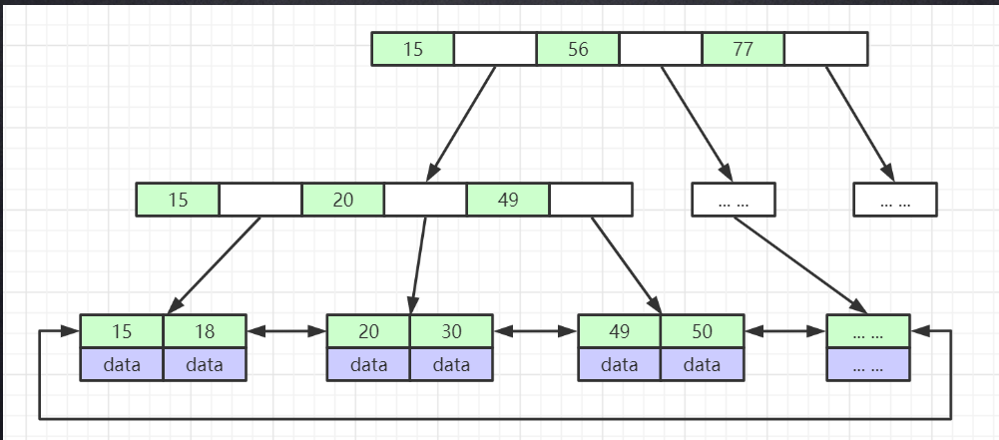
非叶子节点不存储数据,数据全在叶子节点中存储,叶子节点中的数据是有序的,从左到右,依次递增。叶子节点类似链表,通过指针来连接下一个节点,叶子节点中保存所有索引数据。
比如要查找索引为三十的元素,首先会将15 56 77 这三个值装载进内存进行匹配,匹配所得30在15-56直接,走左子树,之后将15 20 49三个元素装载进内存进行匹配,匹配得20 49直接进中间那条,然后在中间那条所指的叶子节点进行加载内存并进行匹配返回。
使用B+Tree的好处
- 减少磁盘的IO
- B 树由于在非叶子节点中存储了数据,使得非叶子节点只能存储及其有限的数据,采用了B+Tree之后因为不用存储数据,存储的节点数变多了。
MyIASM
MyIASM存储时采用的B+Tree存储数据时,会在叶子节点中存储一个硬盘地址。检索时会拿到这个硬盘地址然后再去硬盘中查找数据,这种方式被称为非聚集索引,而InnoDB会在叶子节点中将表数据存储到叶子节点中,并不需要在去读取硬盘查询数据,这种方式被称为聚集索引。
为什么使用自增id
使用自增主键可以避免在生成b+tree时索引分裂的问题。
首先有这样一颗b+tree
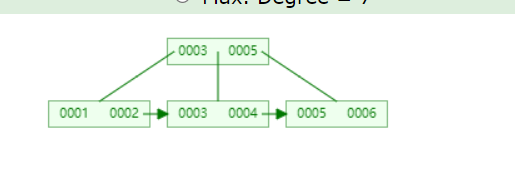
如果不按自增主键插入id时会变成这样
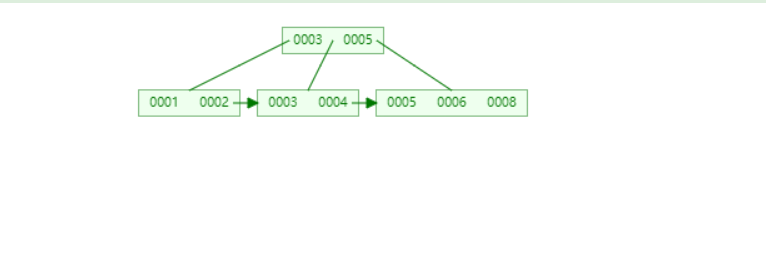
如果再插入7会将树进行平衡并进行分裂出两个7,这样并不利于存储,还会浪费空间。
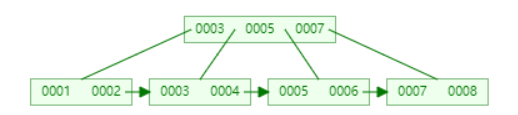
为什么建议主键采用整型数据
MySQL再生成B+tree时肯定会对索引进行比较,采用整型的话利用MySQL进行比较,采用字符串的话还得装成Ascii码,逐个字符进行比较,这样会消耗性能。
Hash索引
Hash索引可以根Hash算法将生成Hash Code并存储到数组中,查找时根据Hash Code直接就可以获取到数据,优点是查找速度快,缺点是没办法进行范围查询,如果要进行范围查询得需要全表扫描。
MySQL 查看B+Tree非叶子节点存储数据大小
这个值不建议修改
也就是 所存储的大小
所存储的大小
show global status like "innodb_page_size"
二级索引
只有主键索引才是一级索引,只有在一级索引且存储引擎为InnoDB的B+Tree树的叶子节点才存储的是整条数据,像普通索引,唯一索引等被称为二级索引或普通索引,普通索引的叶子节点存储的是主键索引的值,并没有存储整条数据,这样做的好处是节省了存储空间且降低了表的复杂度,如果表中没有主键,那么mySQL则会自己创建一列作为主键列。
联合索引
开发中不建议使用单值索引,建议使用联合索引。
联合索引在建立B+Tree时会按顺序根据索引字段进行排序,如果第一个字段能够区分大小则按第一个字段进行排序,如果第一个字段无法区分大小则按下一个字段进行排序,依次类推,如果字段值全相等则会根据联合索引中存储的主键值,那么就将所有的字段排序到一起,最后会根据主键回表查询想要的数据。
如下图首先会根据name进行匹配,如果name相同则会根据age进行匹配,如果age相同则会根据position进行匹配。
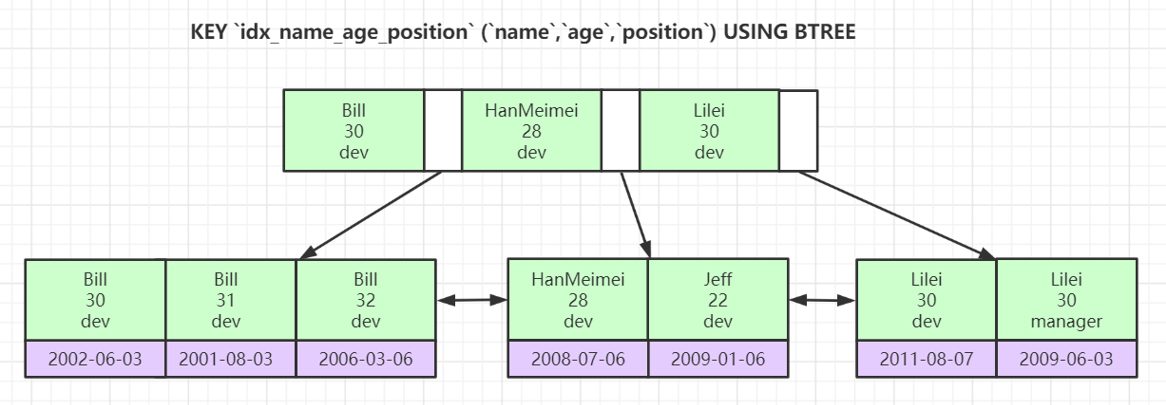
最左前缀原理
当进行联合索引进行匹配时,必须按创建索引的顺序进行匹配,否则无法使用索引

比如上图查询时必须是以bane age position的顺序进行匹配,否则无法使用索引,如下面这条SQL语句
select * from user where name = 'test' and age = 16;
下面这两条不是按键索引顺序进行检索,所有没办法进行索引匹配
select * from user where age = 16 and position = "山西"
select * from user where position = "山西"
最左前缀匹配的原理是,在构建B+Tree是按顺序进行排序,如果跳过name直接访问age那么就是age就不是排好序的,这样直接访问会导致不知道其他节点是否还有需要的数据,所有得进行全表扫描。
不要在索引中进行聚合操作
如果对索引进行运算、函数、类型转换操作则不会走索引,如果使用聚合操作的话,因为聚合函数是聚合完毕后根据值去数据库中查找,MySQL中存在索引树中存储的数据是聚合之前的数据,所以就没办法根据索引树来对索引进行查询操作,例如MySQL中的聚合函数,取一个字符串的中间三位进行查询,MySQL中存储的肯定不是字符串的中间三位,它不知道索引中的哪些符合中间三位的条件,所以必须进行全表扫描。
如下所示,直接根据name查询就能查到值,因为数据库的索引是有序的,直接根据有序树进行查询就行了。
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei';

如果取前三位的话就没办法取了,取前三位肯定没办法去索引树中找数据了,所以没办法走索引
EXPLAIN SELECT * FROM employees WHERE left(name,3) = 'LiLei';

热点字段使用索引
只访问索引字段,尽量少的进行select * 操作
like
百分号在前可以根据索引树排序直接对值进行过滤,所以可以使用索引
EXPLAIN SELECT * FROM employees WHERE name like 'Lei%';

而百分号没办法进行排序,所以没办法根据有序节点进行过滤
EXPLAIN SELECT * FROM employees WHERE name like '%Lei';


 浙公网安备 33010602011771号
浙公网安备 33010602011771号