RabbitMQ使用中常遇到的问题
如何保证消息不丢失
首先使用的场景与下图相符
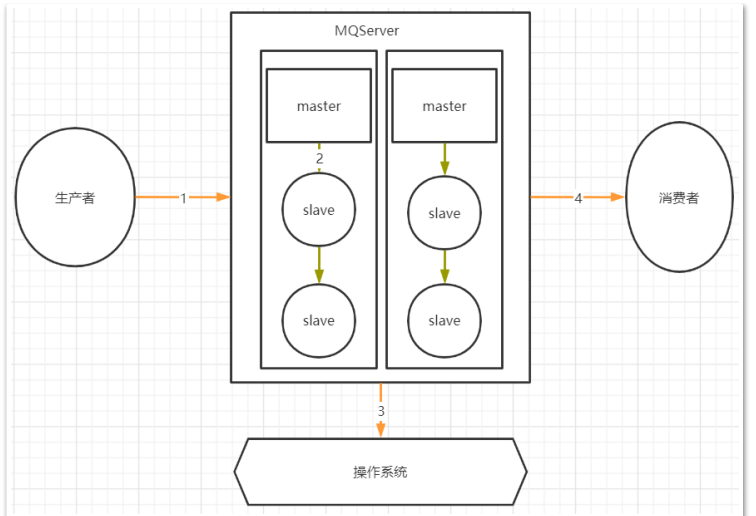
- 生产者将消费放入到消息队列中
- 分布式消息队列服务同步消息以及元数据
- 操作系统将消息持久化到内存中
- 消费者从消息队列拉取消息进行消费
首先是1 可以采用消费者确认的方式进行提交,当消息发送到消息队列中时,如果RabbitMQ接收成功了,可以将接收成功的信息返回给客户端,还有一种方式是以事务提交的方式来提交消息,如果消息保存成功则提交事务,否则回滚,但是这种方式有个阻塞的弊端,会使吞吐量下降。
其次是2 可以采用镜像集群的方式进行部署,如果使用普通集群的方式进行部署的话只会同步元数据,而镜像集群部署则会同步消息。
再然后是3,可以使用懒队列,优先将消息持久化到硬盘中以此来避免消息丢失。
最后是4,可以使用手动提交或自动提交的方式来告诉RabbitMQ自己消费成功了,如果抛出异常的话,则不会响应给服务端消费成功的消息,那么这个消息就是消费失败的消息。
消息的幂等性
因为消费失败抛异常会导致消费者重试,也就是重复消费,所以需要限制重试次数
在Spring boot中配置重试的相关参数 除了关闭还有一些其他参数
spring:
rabbitmq:
addresses: 192.168.71.134
port: 5672
username: lyra
password: lyra
listener:
simple:
prefetch: 1
concurrency: 5
max-concurrency: 10
acknowledge-mode: auto
retry:
enabled: false
当生产者进行提交时会获取一个随机数并设置到header或消息id中,当消息进行消费时会将该值存储到redis中,二次消费时会判断该值是否在redis中存在,如果存在的话表示消息已经有人消息了,如果不存在才可以对消息进行消费。
Spring boot
在生产消息是指定一个唯一id即可
@GetMapping("/sendMessage")
public String sendMessage(String message){
String messageID = UUID.randomUUID().toString();
Message build = MessageBuilder.withBody(message.getBytes(StandardCharsets.UTF_8)).setMessageId(messageID).build();
rabbitTemplate.send("lyra-exchange","", build);
return "Hello world";
}
在消费时只用判断该id是否存储在redis中,如果有则表示已经被消费过了,可以不用消费。
@RabbitListener(queues = {"lyra-queue"})
public void fanoutConsumer(Message message, Channel channel, String messageStr) {
String messageId = message.getMessageProperties().getMessageId();
// 如果redis中没有该messageId表示未被消费,那么执行消费操作
if (redisTemplate.opsForValue().get("messageId:" + messageId) == null) {
redisTemplate.opsForValue().set("messageId:" + messageId, messageId);
log.info("message:{}", messageStr);
}
}
普通API
可以使用BasicProperties来设置messageId,消费时和Spring boot一样,判断redis中是否有消息id。如果没有则进行消费。
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("192.168.71.136");
connectionFactory.setUsername("lyra");
connectionFactory.setPassword("lyra");
Connection connection = connectionFactory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("lyra-exchange", "direct", true, false, null);
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
builder.deliveryMode(MessageProperties.PERSISTENT_TEXT_PLAIN.getDeliveryMode());
// 设置messageId
builder.messageId(UUID.randomUUID().toString());
for (int i = 0; i < 10000; i++) {
channel.basicPublish("lyra-exchange", "", builder.build() , "lyra heartstrings".getBytes(StandardCharsets.UTF_8));
}
保证消息顺序消费
根据队列数据结构的特性,先进先出的特性就可以保证消息的顺序不会乱,需要保证只有一个消费者且每次只拉取一个消息便可以保证消息的顺序消费。但是使用这种方式会使得性能消耗增加,应当尽量避免这种行为。
prefetch可以设置消费者每次拉取消息的个数。
spring:
rabbitmq:
addresses: 192.168.71.136
port: 5672
username: lyra
password: lyra
listener:
simple:
prefetch: 1
消息堆积问题
消息堆积会使得RabbitMQ性能下降。
首先是生产者端,因为业务逻辑的原因,使得堆积问题不太好优化,在生产者端应当少发消息和采用批量确认的方式,降低IO频率。
其次是服务端,服务端可以将队列设置为懒队列或分片存储的方式进行优化,通过这种方式将消息存储到多队列中,以此来优化吞吐量。
最后是消费者端,可以增加消费者来消费队列中的消息,还可以设置消费者的线程数量单次推送消息的数量
spring:
rabbitmq:
addresses: 192.168.71.136
port: 5672
username: lyra
password: lyra
listener:
simple:
# 单次拉取消息数量
prefetch: 1
# 最大消费者线程数
max-concurrency: 10
RabbitMQ备份与恢复
在RabbitMQ管理界面点击Export或Import便可以对配置文件的导入导出

RabbitMQ不推荐对消息进行备份恢复的
首先必须得将元数据恢复之后才能对消息进行恢复
然后将集群服务体重
最后可以将/var/lib/rabbitmq/mnesia/rabbit@fedora02/msg_stores/vhosts目录下的文件进行备份覆盖即可完成恢复。
性能监控
可以在管理界面看到服务器的基本信息
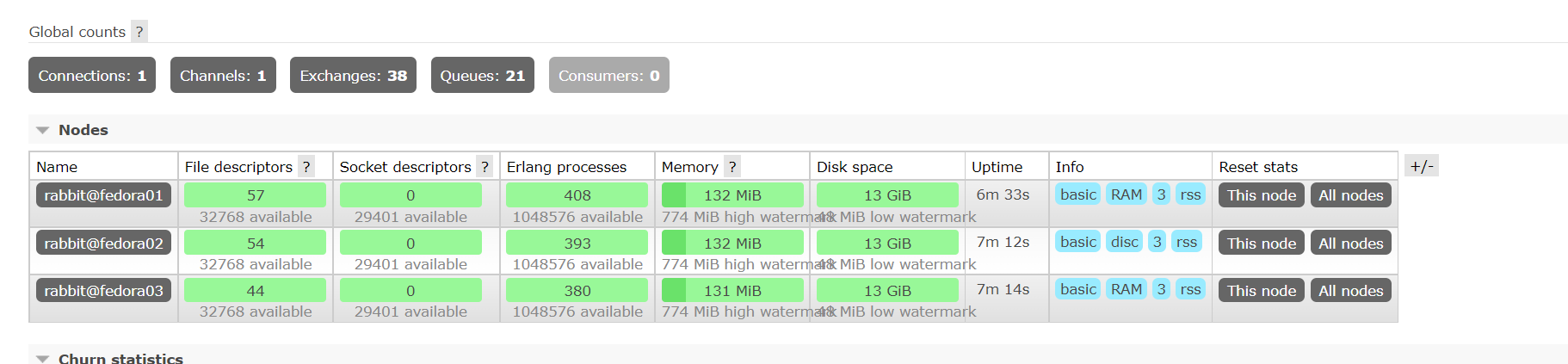
也可以调用HTTP API的方式进行监控
在管理界面最下面有个Http API按钮

在界面中定义了各API的作用。
可以配置普罗米修斯来将数据可视化监控处理。
HAProxy
通过使用HAProxy来将集群服务反向代理到HAProxy中,再由HAProxy将请求转发打集群节点中。
首先安装HAProxy
yum install haproxy
修改/etc/haproxy下的配置文件
在末尾添加以下信息
#对MQ集群进行监听
listen rabbitmq_cluster
bind 0.0.0.0:5672
option tcplog
mode tcp
option clitcpka
timeout connect 1s
timeout client 10s
timeout server 10s
balance roundrobin
server rabbit1 192.168.71.134:5672 check inter 5s rise 2 fall 3
server rabbit2 192.168.71.135:5672 check inter 5s rise 2 fall 3
# 开启监控服务
listen http_front
bind 0.0.0.0:1080
stats refresh 30s
stats uri /haproxy_stats
stats auth admin:admin
注释掉直接把# option forwardfor except 127.0.0.0/8 否则会报错
启动服务
haproxy ‐f /etc/haproxy/haproxy.cfg
打开/haproxy_stats查看后台负载均衡情况
账号密码是之前配置的admin
使用是直接使用本机ip:5672, HAProxy会自动将请求转发到集群节点中
spring:
rabbitmq:
addresses: 192.168.71.133
port: 5672
username: lyra
password: lyra


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律