随笔③ java集合类 --- ArrayList,LinkedList,Vector,Hashtable,HashMap,ConcurrentHashMap
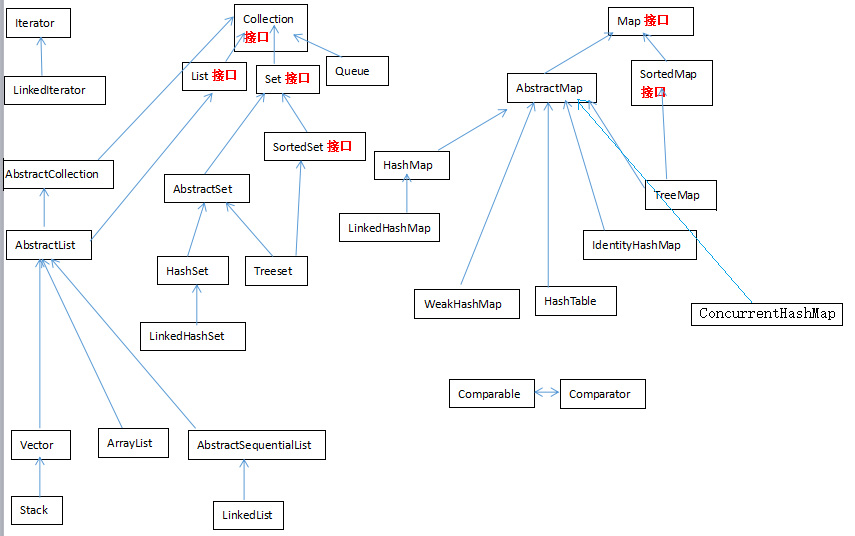
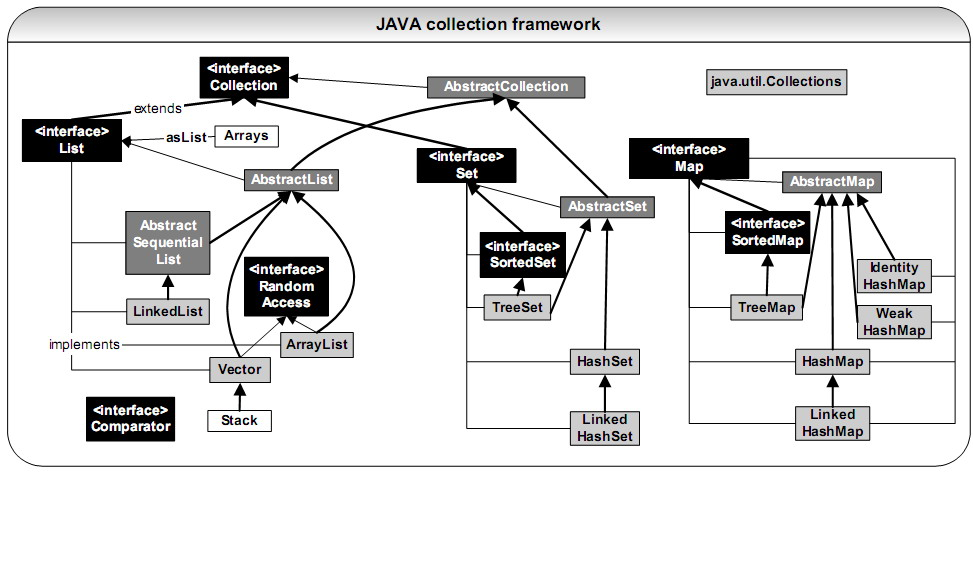
java集合类 --- 继承关系

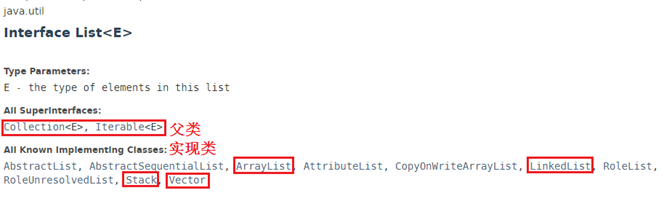
java集合类 --- List接口
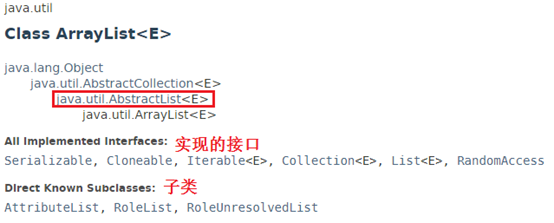
一:ArrayList
① ArrayList有三个构造函数:
(1)ArrayList()构造一个初始容量为 10 的空列表。
(2)ArrayList(Collection<? extends E> c)构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
(3)ArrayList(int initialCapacity)构造一个具有指定初始容量的空列表。
② ArrayList是实现了基于动态数组的数据结构。
这里的所谓动态数组并不是那个“ 有多少元素就申请多少空间 ”的意思,通过查看源码,可以发现,这个动态数组是这样实现的,如果没指定数组大小,则申请默认大小为10的数组,当元素个数增加,数组无法存储时,系统会另个申请一个长度为当前长度1.5倍的数组,然后,把之前的数据拷贝到新建的数组中。
③ ArrayList的Iterator实现
在ArrayList内部首先是定义一个内部类Itr,该内部类实现Iterator接口,如下:
1 private class Itr implements Iterator<E> { 2 //do something 3 }
而ArrayList的iterator()方法实现:
1 public Iterator<E> iterator() { 2 return new Itr(); 3 }
所以通过使用ArrayList.iterator()方法返回的是Itr()内部类,所以现在我们需要关心的就是Itr()内部类的实现:
在Itr内部定义了三个int型的变量:cursor、lastRet、expectedModCount。其中cursor表示下一个元素的索引位置,lastRet表示上一个元素的索引位置。
1 int cursor; 2 int lastRet = - 1 ; 3 int expectedModCount = modCount;
从cursor、lastRet定义可以看出,lastRet一直比cursor少一所以hasNext()实现方法异常简单,只需要判断cursor和lastRet是否相等即可。
1 public boolean hasNext() { 2 return cursor != size; 3 }
对于next()实现其实也是比较简单的,只要返回cursor索引位置处的元素即可,然后修改cursor、lastRet即可,
1 public E next() { 2 checkForComodification(); 3 int i = cursor; //记录索引位置 4 if (i >= size) //如果获取元素大于集合元素个数,则抛出异常 5 throw new NoSuchElementException(); 6 Object[] elementData = ArrayList.this .elementData; 7 if (i >= elementData.length) 8 throw new ConcurrentModificationException(); 9 cursor = i + 1 ; //cursor + 1 10 return (E) elementData[lastRet = i]; //减少数据依赖cursor,有利于指令重排序lastRet + 1 且返回cursor处元素 11 }
二:LinkedList
LinkedList是基于链表的数据结构。ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间。
三:ConcurrentHashMap

jdk1.7中的ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
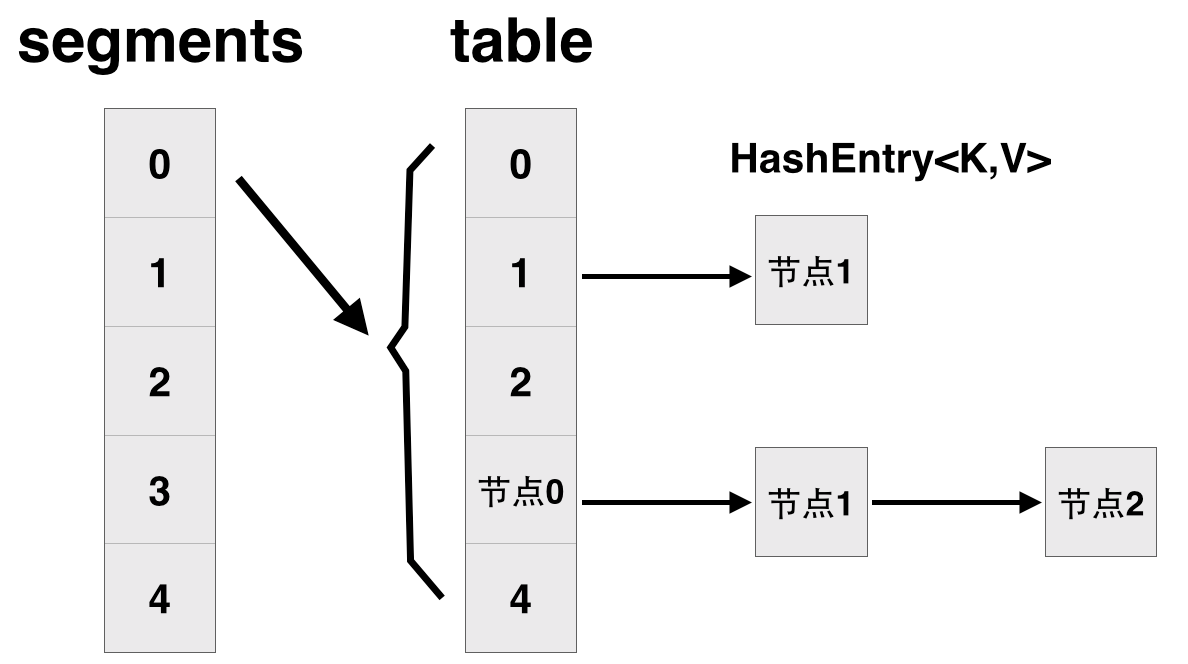
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
jdk7中ConcurrentHashmap中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能,所以jdk8 中完全重写了concurrentHashmap,代码量从原来的1000多行变成了 6000多 行,实现上也和原来的分段式存储有很大的区别。
主要设计上的变化有以下几点:
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V> table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
四:Vector & ArrayList 的主要区别
2)数据增长:当需要增长时,Vector默认增长为原来一倍 ,而ArrayList却是原来的50% ,这样,ArrayList就有利于节约内存空间。
如果涉及到堆栈,队列等操作,应该考虑用Vector,如果需要快速随机访问元素,应该使用ArrayList 。
1. Hashtable & HashMap
Hashtable和HashMap在它们的性能方面的比较类似Vector和ArrayList,比如Hashtable的方法是同步的,而HashMap的不是。
2. ArrayList & LinkedList
ArrayList的内部实现是基于内部数组Object[],所以从概念上讲,它更象数组,但LinkedList的内部实现是基于一组连接的记录,所以,它更象一个链表结构,所以,它们在性能上有很大的差别:
从上面的分析可知,在ArrayList的前面或中间插入数据时,你必须将其后的所有数据相应的后移,这样必然要花费较多时间,所以,当你的操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能; 而访问链表中的某个元素时,就必须从链表的一端开始沿着连接方向一个一个元素地去查找,直到找到所需的元素为止,所以,当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
五:HashMap与Hashtable
2. Hashtable和HashMap的区别:
