线性回归
-
什么是线性回归
不同于分类问题的待预测变量为离散变量,回归问题中待预测变量即因变量为连续变量。人们在测量事物的时候因为客观条件所限,求得的都是测量值,而不是事物真实的值,为了能够得到真实值,无限次的进行测量,最后通过这些测量数据计算回归到真实值,这就是回归的由来。
线性回归假设自变量与因变量之间存在的是一次函数关系,即线性关系。
设所有样本的特征为\(X\in \mathbb{R}^{n*m}\),输出为\(Y\in \mathbb{R}^{n*1}\),其中n为样本数,m为特征数。线性回归假设存在权重项\(W\in \mathbb{R}^{m*1}\)和偏置项\(b\in \mathbb{R}\),使得\(\widehat Y=XW+b\),其中\(\widehat Y\)为对Y的预测值。为了简化表达,给X添加一列1,将偏置项并入权重项,则\(\widehat Y=XW\) ,其中\(X\in \mathbb{R}^{n*(m+1)}\),\(W\in \mathbb{R}^{(m+1)*1}\)。
-
线性回归求解
线性回归以均方误差为损失函数,该方法称为方法称为最小二乘法。
为了方面后面的计算,增加了\(\frac{1}{2n}\)作为因子,即损失函数为:
\[J=\frac{1}{2n}(XW-Y)^T(XW-Y)=\frac{1}{2n}(W^TX^TXW-W^TX^TY-Y^TXW+Y^TY) \]损失函数对权重求导:
\[\frac{\partial J}{\partial W}=\frac{1}{n}X^T(XW-Y) \]令导数等于0,得:
\[W^*=(X^TX)^{-1}X^TY \]当\(X^TX\)满秩或者正定的时候,可以直接由上式求得闭式解。当不满足时,可以使用梯度下降法求解。
-
使用均方误差解释线性回归
对于第i个样本\((x_i,y_i)\),假设\(y_i=W^Tx_i+\epsilon_i\),其中\(\epsilon_i\)为误差项。由于影响误差的因素有很多,而这些因素都是独立且随机分布的,根据中心极限定理——许多独立随机变量的和趋向于正态分布,因此可以假设:
\[\epsilon_i\sim N(0,\sigma^2) \]\(\epsilon_i\)是独立同分布的随机变量。则当给定了参数W和输入\(x_i\)时\(\epsilon_i\)的概率密度为:
\[P(\epsilon_i|x_i;W)=\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{\epsilon_i^2}{2\sigma^2}} \]由于\(\epsilon_i=y_i-W^Tx_i\),有:
\[P(y_i|x_i;W)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i-W^Tx_i)^2}{2\sigma^2}} \]即\(y_i\)也服从正态分布,则似然函数为:
\[l(W)=\prod_{i=1}^n\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i-W^Tx_i)^2}{2\sigma^2}} \]对数似然函数为:
\[L(W)=-n\ln \sqrt{2\pi}\sigma-\sum_{i=1}^n\frac{(y_i-W^Tx_i)^2}{2\sigma^2} \]最大化似然函数:
\[\arg\max_W L(W)=\arg\max_W -n\ln \sqrt{2\pi}\sigma-\sum_{i=1}^n\frac{(y_i-W^Tx_i)^2}{2\sigma^2} \\ =\arg\min_W \sum_{i=1}^n(y_i-W^Tx_i)^2 \\ =\arg\min_W \frac{1}{2n}(XW-Y)^T(XW-Y) \]即最大化似然函数等价于最小化均方误差,即最小二乘法实际上是在假设误差项满足高斯分布且独立同分布情况下,使似然性最大化。
-
正则化方法
正则化方法是指在原损失函数的基础上加上一个正则化项,用来控制参数幅度或者是限制参数搜索空间,从而降低过拟合。线性回归常用的正则化方法有L1正则化(Lasso回归)、L2正则化(岭回归)、ElasticNet回归。
-
L1正则化(Lasso回归)
L1正则化相当于在原有损失函数的基础上加上加权的参数L1范数作为正则化项,即:
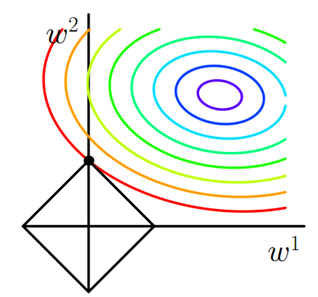
\[J'=J+\lambda\sum|w| \]下图为其在二维时的参数空间:
![yErN5V.png]()
图中彩色部分为原损失函数的等高线,紫色部分为其最小值附近;黑色菱形为L1正则化项等高线,易知最优解必定在两组等高线的切点处,而这个交点很容易出现在坐标轴上,使得部分参数取值为0。这说明L1正则化容易得到稀疏解。
此时由于绝对值函数在w=0处不可导,故不能直接采用梯度下降法,此时可以采用次梯度下降法或者坐标下降法,具体可参考:https://zhuanlan.zhihu.com/p/76055830。
-
L2正则化(岭回归)
L2正则化相当于在原有损失函数的基础上加上加权的参数L2范数作为正则化项,即:
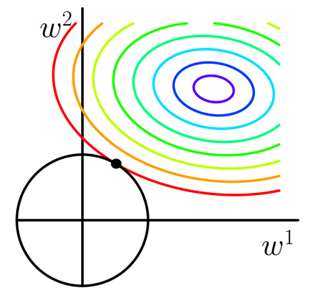
\[J'=J+\lambda\sum|w|^2 \]下图为其在二维时的参数空间:
![yErGbn.png]()
图中彩色部分为原损失函数的等高线,紫色部分为其最小值附近;黑色圆形为L2正则化项等高线,易知最优解必定在两组等高线的切点处,而这个交点很难出现在坐标轴上,这说明L2正则化不容易得到稀疏解。
-
从贝叶斯角度看L1和L2正则化
L1 正则化可以看成是:通过假设权重参数W的先验分布为拉普拉斯分布,由最大后验概率估计导出。
L2 正则化可以看成是:通过假设权重参数W的先验分布为正态分布,由最大后验概率估计导出。
-
ElasticNet回归
ElasticNet综合了L1正则化项和L2正则化项,以下是它的公式:
\[J'=J+\lambda_1\sum|w|+\lambda_2\sum|w|^2 \] -
正则化方法的选择
只要数据线性相关,但用线性回归拟合的不是很好时就可以选择添加正则化项。如果输入特征的维度很高,而且是稀疏线性关系的话可以尝试L1正则化,否则可以尝试使用L2正则化。
在我们发现用L1正则化太过(太多特征被稀疏为0),而L2正则化也正则化的不够(回归系数衰减太慢)的时候,可以考虑使用ElasticNet回归来综合,得到比较好的结果。
-
-
局部加权线性回归
局部加权线性回归是普通线性回归的一个改进,普通的线性回归努力寻找一个使得全局代价函数最小的模型。这个模型对于整体来说是最好的,但对于局部点来说,可能不是最好的。
局部加权线性回归的基本思想:设计代价函数时,待预测点附近的点拥有更高的权重,权重随着距离的增大而缩减——这也就是名字中“局部”和“加权”的由来。
局部加权线性回归的损失函数为:
\[J=\sum_{i=1}^n\theta_i(y_i-W^Tx_i)^2 \\ \theta_i=e^{-\frac{(x-x_i)^2}{2\sigma^2}} \]其中\(\theta_i\)为训练集中第i个样本的权重,其图像类似于正态分布,x为测试样本。\(\sigma\)越小图像越“瘦”,即权重衰减的越快,与x相距越远的样本权重越小。
求导可得局部加权线性回归的闭式解为:
\[W^*=(X^T\theta X)^{-1}X^T\theta Y \]其中\(\theta=diag(\theta_1,\theta_2,...,\theta_n)\)。
局部加权回归的优点:
- 需要预测的数据仅与到训练数据的距离有关,距离越近,关系越大,反之越小;
- 可以有效避免欠拟合,减小了较远数据的干扰,仅与较近的数据有关。
局部加权回归的缺点:
- 需要对每一个测试样本拟合一次参数,计算效率低;
- 容易过拟合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号