词嵌入之GloVe
-
什么是GloVe
GloVe(Global Vectors for Word Representation)是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
-
GloVe实现步骤
-
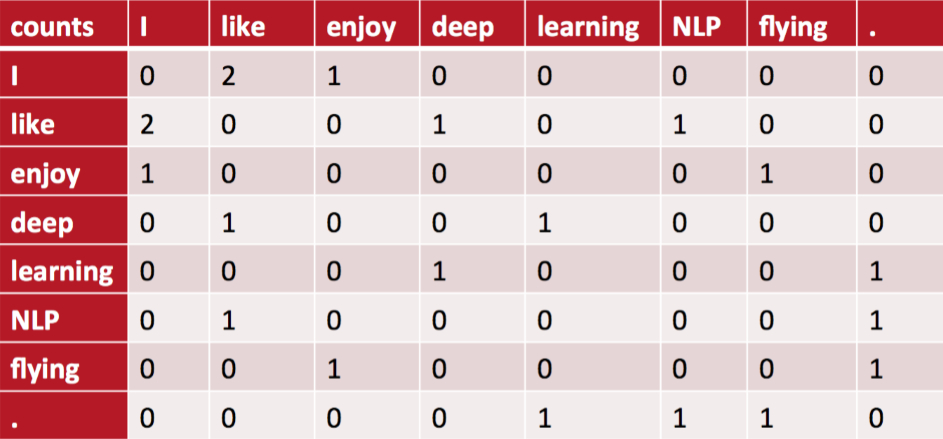
构建共现矩阵
统计词与词在固定窗口大小内共同出现的次数并构建一个共现矩阵。例如有以下三句话:
- I like deep learning.
- I like NLP.
- I enjoy flying
当窗口大小为2时,构造的共现矩阵为:
![s5vRc6.jpg]()
-
词向量与共现矩阵的关系
设共现矩阵为X,其第i行第j个元素为\(X_{ij}\)。与Word2Vec相同,GloVe同样有两个词向量矩阵分别由输入层到隐藏层、隐藏层到输出层。设中心词i在第一个词向量矩阵中所对应的词向量为\(w_i\),上下文词j在第二个词向量矩阵中所对应的词向量为\(\widetilde w_j\),则GloVe所构造的词向量与共现矩阵间的近似关系为:
\[w_i^T\widetilde w_j+b_i+\widetilde b_j=\log X_{ij} \]其中,\(b_i\)和\(\widetilde b_j\)为词i和词j的偏置项。公式的由来见第三节的推导部分。
-
损失函数
基于词向量与共现矩阵间的近似关系,可以构造如下损失函数:
\[J=\sum_{i,j=1}^Vf(X_{ij})(w_i^T\widetilde w_j+b_i+\widetilde b_j-\log X_{ij})^2 \]其中V为词汇表大小。这个损失函数是加了权重项的均方误差,关于权重项\(f(X_{ij})\),我们希望:
- 共现次数多的两个词的权重应当大于共现次数少的两个词的权重,因此\(f(X_{ij})\)应当是非递减的;
- 但\(f(X_{ij})\)也不应当过大,因此\(f(X_{ij})\)应当有上限;
- 共现次数为0的两个词其权重也应当为0。
基于以上三点,GloVe作者构造了以下权重函数:
\[f(X_{ij})=\left\{\begin{aligned} (\frac{X_{ij}}{x_{max}})^\alpha \quad \quad X_{ij}<x_{max} \\ 1 \qquad\quad otherwise \end{aligned}\right. \]其中\(\alpha\)在原论文中被设置为了0.75,它的作用与Word2Vec中负采样处的\(\alpha\)类似,也是为了提高共现次数小的两个词的权重,进而提高低频词的词向量的准确度。\(x_{max}\)是共现次数的上限,在原论文中被设置为了100。
-
其他细节
- 在统计共现矩阵的时候,并不是说只要两个词同时出现在了一个窗口内共现矩阵的对应项就会加1,GloVe根据两个单词在上下文窗口的距离d,提出了一个衰减函数(decreasing weighting):\(decay=\frac{1}{d}\)用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小。
- 与Word2Vec相同,GloVe同样有两个词向量矩阵分别由输入层到隐藏层、隐藏层到输出层,理论上是这两个矩阵式对称的,唯一的区别是初始化的值不一样而导致最终的值不一样。Word2Vec是选择第一个矩阵作为最终的词向量矩阵,但理论上二者都可以当成最终的结果来使用。GloVe的选择是将二者的和作为最终的词向量。由于二者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性。
-
-
GloVe公式推导
记\(X_i=\sum_{k=1}^VX_{ik}\)为词i所有窗口内共现词的数量,\(p_{ik}=\frac{X_{ik}}{X_i}\)为单词k出现在单词i的上下文中的概率,\(p_{ij,k}=\frac{p_{ik}}{p_{jk}}\)为为单词k出现在单词i的上下文中的概率与为单词k出现在单词j的上下文中的概率的比值。当单词i和单词j与单词k均相关或者均不相关时该比值趋近于1;当单词i与单词k相关,单词j与单词k不相关时该比值很大;当单词i与单词k不相关,单词j与单词k相关时该比值很小。
作者通过实验发现通过构建词向量与这个比值的关系比直接构建词向量与条件概率的关系效果更好。
假设词向量与上述比值通过函数F进行对应,即:
\[F(w_i,w_j,w_k)=\frac{p_{ik}}{p_{jk}} \]由于\(\frac{p_{ik}}{p_{jk}}\)最终反应的实际上是单词i和单词j间的关系,因此可以将上式修改为:
\[F(w_i-w_j,w_k)=\frac{p_{ik}}{p_{jk}} \]上式左边是向量,右边是标量,因此可以对左边进行内积:
\[F((w_i-w_j)^Tw_k)=F(w_i^Tw_k-w_j^Tw_k)=\frac{p_{ik}}{p_{jk}} \]上式左边是差,右边是商,当F为指数函数时满足,因此:
\[\frac{e^{w_i^Tw_k}}{e^{w_j^Tw_k}}=\frac{p_{ik}}{p_{jk}} \]分别令分子分母相同,则:
\[e^{w_i^Tw_k}=\frac{X_{ik}}{X_i} \]则:
\[w_i^Tw_k=\log X_{ik}-\log X_i \]将i和k交换后上式左边仍然不变,但右边值变了。为了保持右边的值不变,考虑到对称性,在上式左边加上两个偏置项\(b_i\)和\(b_k\),则:
\[w_i^Tw_k+b_i+b_j=\log X_{ik} \] -
GloVe与Word2Vec的比较
Word2Vec每次都是利用局部窗口内的信息进行更新,而GloVe每次更新都利用到了共现矩阵中所统计的全局共现信息,所以理论上来说GloVe抗噪声能力更强,对语料的利用更加充分,效果也应当更好。从原论文给出的实验结果来看,GloVe的性能是远超Word2Vec的,但网上也有人说GloVe和Word2Vec实际表现其实差不多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号