LSTM和GRU
-
LSTM简介
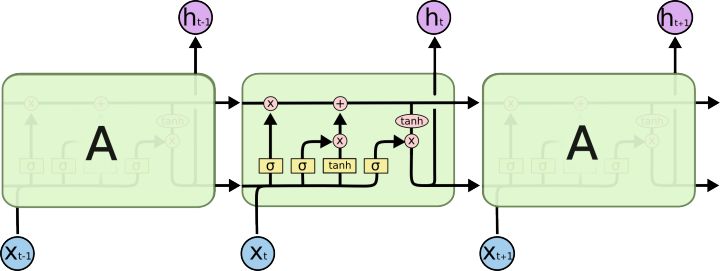
LSTM是RNN的一种变体,引入了门控单元,旨在减缓RNN中的梯度消失现象,使得模型能够建模长距离的依赖关系。LSTM的结构图如下:
![sRhVxK.jpg]()
对比原始的RNN,LSTM中存在两种在不同时刻间传递的状态,分别为单元状态\(c_t\)以及隐藏状态\(h_t\),其中\(c_t\)被用于保存长期记忆。
LSTM中存在三个门控结构,分别为遗忘门、输入门和输出门,遗忘门决定丢弃哪些信息,输入门表示要保存的信息或者待更新的信息,输出门决定当前神经原细胞的输出隐藏状态\(h_t\)。用公式可以表示为:
\[f_t=\sigma(W_f[h_{t-1},x_t]+b_f) \\ i_t=\sigma(W_i[h_{t-1},x_t]+b_i) \\ f_o=\sigma(W_o[h_{t-1},x_t]+b_o) \\ \widetilde C_t=tanh(W_c[h_{t-1},x_t]+b_c) \\ C_t=f_tC_{t-1}+i_t\widetilde C_t \\ h_t=o_ttanh(C_t) \]上面的式子分别对应遗忘门、输入门、输出门、当前时刻的候选状态、当前时刻的单元状态、当前时刻的隐状态。可以看出LSTM主要存在三个阶段:
- 忘记阶段,通过遗忘门来决定对上一个时刻的单元状态进行选择性的遗忘;
- 记忆阶段,通过输入门来决定对当前时刻的输入进行选择性的记忆;
- 输出阶段,通过输出门来决定哪些状态在当前时刻被输出。
-
LSTM为什么能够缓解梯度消失问题
LSTM之所以能够缓解梯度消失问题,可以从正向与反向两个角度来描述:
-
正向角度,LSTM引入了单元状态\(c_t\)来对长期记忆进行保存,每个时刻通过门控结构来对\(c_t\)进行选择性的更新,而不是像原始RNN那样需要将当前时刻的状态完全叠加到隐藏状态上。这样可以使得\(c_t\)的改变变得缓慢,更有利于建模长期的记忆。
-
反向角度,原始RNN之所以很难建模长期记忆,是因为时刻t的损失对隐藏层和输入层的参数矩阵进行求导的结果中存在有连乘项,时刻i的梯度要传递到时刻t,需要经历t-i个连乘,并且每个因子包含一个参数矩阵以及一个sigmoid函数的导数,这样当i和t相隔很远的时候,连乘结果就会趋近于0,使得长期的依赖难以建立。
对LSTM的反向求导过程进行简单的考察:
- \(\frac {\partial h_t}{\partial W}\)不论是对哪一个参数矩阵,其结果都会包含很多项的加和,这是保证梯度不为0的第一点;
- 与原始RNN类似,\(\frac {\partial h_t}{\partial W}\)中也会存在连乘项,其中就包括\(\frac {\partial c_t}{\partial c_{t-1}}\),而\(\frac {\partial c_t}{\partial c_{t-1}}=f_t=\sigma(W_f[h_{t-1},x_t]+b_f)\),与原始RNN每个子项包含一个参数矩阵以及一个sigmoid函数的导数不同,这里仅包含一个sigmoid函数,显然原始RNN的连乘结果更容易趋近于0。
综上所述,LSTM会更有利于建模长期依赖。
-
-
GRU简介
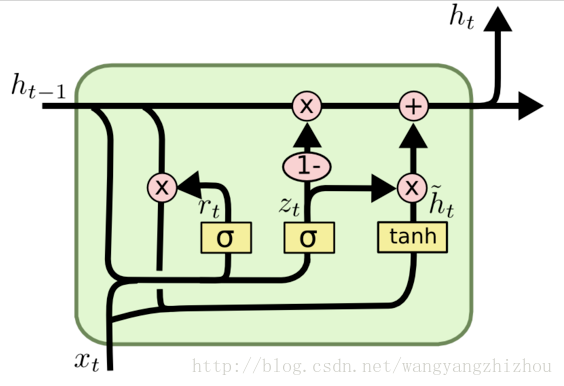
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU的结构图如下:
![sRqLex.png]()
GRU中同样存在门控结构,分别为重置门和更新门,重置门控制前一状态有多少信息被写入到当前的候选集 \(\widetilde h_t\)上,更新门用于控制前一时刻的状态信息被带入到当前状态中的程度。用公式可以表示为:
\[r_t=\sigma(W_r[h_{t-1},x_t]+b_r) \\ z_t=\sigma(W_z[h_{t-1},x_t]+b_z) \\ \widetilde h_t=tanh(W_{\widetilde h}[r_t*h_{t-1},x_t]+b_{\widetilde h}) \\ h_t=(1-z_t)h_{t-1}+z_t\widetilde h_t \]上面的式子分别对应重置门、更新门、当前时刻的候选状态、当前时刻的隐状态。
-
GRU为什么能够缓解梯度消失问题
GRU之所以能够缓解梯度消失问题,同样可以从正向与反向两个角度来描述:
- 正向角度,GRU每个时刻通过门控结构来对\(h_t\)进行选择性的更新,而不是像原始RNN那样需要将当前时刻的状态完全叠加到隐藏状态上。这样可以使得\(h_t\)的改变变得缓慢,更有利于建模长期的记忆。
- 反向角度,对GRU的反向求导过程进行简单的考察:
- \(\frac {\partial h_t}{\partial W}\)不论是对哪一个参数矩阵,其结果都会包含很多项的加和,这是保证梯度不为0的第一点;
- 与原始RNN类似,\(\frac {\partial h_t}{\partial W}\)中也会存在连乘项,其中就包括\(\frac {\partial h_t}{\partial h_{t-1}}\),而\(\frac {\partial c_t}{\partial c_{t-1}}=1-z_t=1-\sigma(W_z[h_{t-1},x_t]+b_z)\),与原始RNN每个子项包含一个参数矩阵以及一个sigmoid函数的导数不同,这里仅包含一个sigmoid函数,显然原始RNN的连乘结果更容易趋近于0。
-
LSTM与GRU
- GRU是LSTM的变体,由LSTM的更新公式之一\(h_t=o_ttanh(C_t)\)可知LSTM中的隐藏状态实际上是依赖于单元状态的,因此在GRU中省略了单元状态,GRU中的隐藏状态就类似于LSTM中的单元状态,也是用来存储长期记忆的。
- GRU中的重置门类似于LSTM中的输出门,将长期记忆转化为短期记忆;GRU中的更新门类似于LSTM中的输入门与遗忘门,因为默认二者之和为1,因此省略掉了一个门(遗忘门)。
- 在大多数场景下,GRU的表现与LSTM都是类似的,但GRU参数量更少,因此此时应当优先选择GRU。但这不是绝对的,LSTM可能也有某些表现更好的场景,因此具体选取策略得视情况而定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号