XGBoost
-
什么是XGBoost
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted。
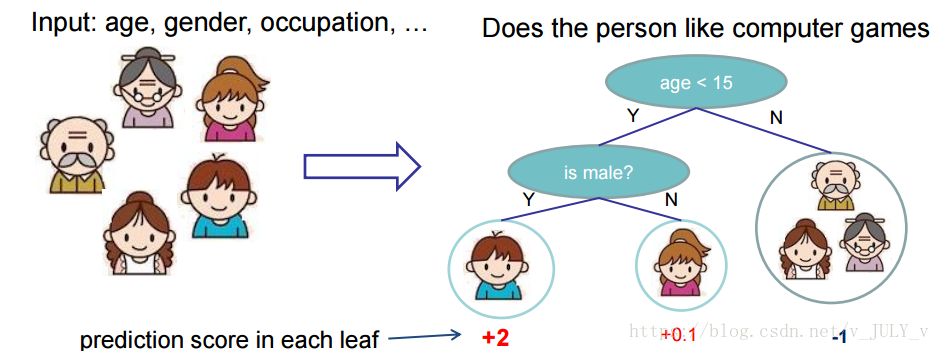
先来举个例子,我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,如下图所示。
![sKHegA.png]()
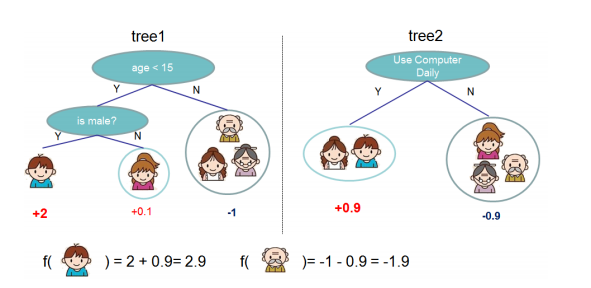
就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以小孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。爷爷的预测分数同理:-1 + (-0.9)= -1.9。具体如下图所示:
![sKHmjI.png]()
-
XGBoost目标函数
![sKHMHf.png]()
其中:
- 红色箭头所指向的L 即为损失函数(比如平方损失函数)
- 红色方框所框起来的是正则项(包括L1正则、L2正则)
- 红色圆圈所圈起来的为常数项
- 对于f(x),XGBoost利用泰勒展开三项,做一个近似。f(x)表示的是其中一颗回归树。
由于\(\sum_{i=1}^{n}l(y_i,\hat{y_i}^{(t-1)})\)是由前面的t-1棵子树得到的,相当于已知的,对当前目标函数的优化不带来影响,因此可以忽略掉。常数项也可以忽略掉,故:
\[Obj^{(t)}\approx\sum_{i=1}^n[g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)] + \Omega(f_t) \]前后分别对应训练误差以及正则化项,训练误差容易理解,接下来讨论正则化项:
\[\Omega(f_t)=\gamma{T}+\frac{1}{2}\lambda{\sum_{j=1}^{T}\omega{_j^2}} \]其中T为叶子节点个数,\(\omega{_j^2}\)为第j个叶子节点的得分,\(\gamma\)和\(\lambda\)分别对应二者所占比重,为超参数。
关于为什么可以使用叶子节点的得分来衡量模型复杂度的一点个人理解:叶子节点权重的L2范数越大,表示模型对数据拟合得越紧,模型复杂度越高。
将正则化项带入目标函数并进行如下变形:
\[Obj^{(t)}\approx\sum[_{i=1}^ng_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+(\gamma{T}+\frac{1}{2}\lambda{\sum_{j=1}^{T}\omega{_j^2}}) \\=\sum_{j=1}^{T}((\sum_{i\in{I_j}}g_i)w_j+\frac{1}{2}((\sum_{i\in{I_j}}h_i)+\lambda)\omega{_j^2})+\gamma{T} \]其中,\(I_j\)表示叶节点 j 上面样本下标的集合 ,设\(q(x_i)\)表示样本\(x_i\)被分到的叶节点下标,则\(I_j=\{i|q(x_i)=j\}\)。
定义\(G_j=\sum_{i\in{I_j}}g_i\),\(H_j=\sum_{i\in{I_j}}h_i\),则:
\[Obj^{(t)}\approx\sum_{j=1}^{T}(G_jw_j+\frac{1}{2}(H_j+\lambda)\omega{_j^2})+\gamma{T} \]上式对\(w_j\)求导得:
\[\frac{\partial{Obj^{(t)}}}{\partial{w_j}}=G_j+(H_j+\lambda)w_j \]令导数等于0得:
\[w_j^*=-\frac{G_j}{H_j+\lambda} \]然后将\(w_j^*\)回代到目标函数中得到:
\[Obj^{(t)}=-\frac{1}{2}\frac{G_j^2}{H_j+\lambda}+\gamma{T} \]目标函数中的G/(H+λ)部分,表示着每一个叶子节点对当前模型损失的贡献程度。
-
XGBoost如何分裂
对于一个叶子节点如何进行分裂,原作者在其原始论文中给出了两种分裂节点的方法:
-
枚举所有不同树结构的贪心法
对某个叶子节点进行分类所获得的增益为:
\[Gain=(-\frac{1}{2}\frac{G^2}{H+\lambda}+\gamma)-[(-\frac{1}{2}\frac{G_L^2}{H_L+\lambda}+\gamma)+(-\frac{1}{2}\frac{G_R^2}{H_R+\lambda}+\gamma)] \\=\frac{1}{2}(\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{G^2}{H+\lambda})-\gamma \]其中,L和R分别表示左右子树。寻找使得增益最大的划分点。
贪心算法获得一个叶节点分割特征的流程:
![sKHlE8.png]()
上图中m为特征维度。
-
近似算法
对于连续型特征,使用分位点代替连续步长查找以节省时间。
![sKH34g.png]()
-
XGBoost如何处理缺失值
XGBoost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。
![ybD69x.png]()
-
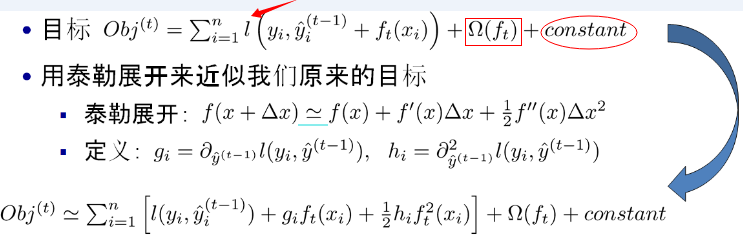




 浙公网安备 33010602011771号
浙公网安备 33010602011771号