
分布式爬虫
一.分布式爬虫简介
1.介绍:
分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集。比如爬虫A,B,C分别在三台服务器上,需要一个状态管理器集中分配,去重这三个爬虫的url,状态管理器也是一个服务,需要部署在某一个服务器上。
2.优点:
(1)充分利用多机器的带宽加速爬取;
(2)充分利用多机器的ip加速爬取速度
3.分布式需要解决的问题:
(1)request队列集中处理
(2)去重集中处理
二.Redis的简单使用
1.Redis的数据类型:
1.1(String)字符串:

键值对应
1.2(Hash)哈希:
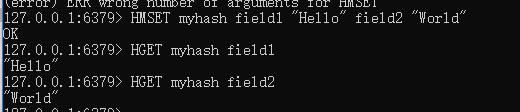
设置多个键值对每个 hash 可以存储 232 -1 键值对(40多亿)
1.3(List)列表:
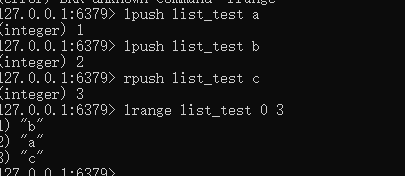
左边添加,右边添加,左边取前四个数据
1.4(Set)集合:

添加一个字符串到set()集合,成功返回1,如果已经存在则返回0,最大的成员数为 232 - 1
1.5(zset)有序集合:
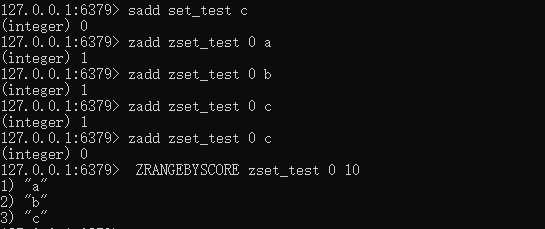
添加元素到集合,不同的是每个元素都会关联一个double类型的分数,通过分数排序。
2.常用命令:
可参考:http://www.runoob.com/redis/redis-sets.html
三.scrapy-redis搭建分布式爬虫
1.github源码地址:
https://github.com/rmax/scrapy-redis
2.将scrapy-redis项目clone下到本地,需要src下的scrapy-redis文件:
导入scrapy-redis并安装redis(pip install redis)设置:


1 #在redis中启用调度存储请求队列。 2 SCHEDULER = “ scrapy_redis.scheduler.Scheduler ” 3 4 #确保所有蜘蛛通过redis共享相同的重复过滤器。 5 DUPEFILTER_CLASS = “ scrapy_redis.dupefilter.RFPDupeFilter ” 6 7 #默认请求序列化程序是pickle,但它可以更改为 8 具有加载和转储功能的任何模块#。请注意, 9 # python版本 10 之间的pickle不兼容。#警告:在蟒蛇3.x中,串行器必须返回字符串键和支持 11 #字节的值。由于这个原因,json或msgpack模块 12 默认不会#工作。在python 2.x中没有这样的问题,您可以使用 13 # 'json'或'msgpack'作为序列化程序。 14 # SCHEDULER_SERIALIZER = “scrapy_redis.picklecompat” 15 16 #不要清理redis队列,允许暂停/恢复抓取。 17 # SCHEDULER_PERSIST =真 18 19 #使用优先级队列安排请求。(默认) 20 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' 21 22 #替代队列。 23 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' 24 # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' 25 26 #最大空闲时间,防止蜘蛛在分布式爬网时被关闭。 27 #这仅在队列类为SpiderQueue或SpiderStack时才有效, 28 #也可能在您的蜘蛛第一次启动时阻塞同一时间(因为队列为空)。 29 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 30 31 #将已删除的项目存储在redis中进行后期处理。 32 ITEM_PIPELINES = { 33 ' scrapy_redis.pipelines.RedisPipeline ': 300 34 } 35 36 #项目管道序列化并存储此redis密钥中的项目。 37 # REDIS_ITEMS_KEY ='%(蜘蛛)S:项的 38 39 #项目序列化程序默认为ScrapyJSONEncoder。你可以使用任何 40 #导入的路径,一个可调用对象。 41 # REDIS_ITEMS_SERIALIZER = 'json.dumps' 42 43 #指定连接到Redis时使用的主机和端口(可选)。 44 # REDIS_HOST = '本地主机' 45 # REDIS_PORT = 6379 46 47 #指定用于连接的完整Redis URL(可选)。 48 #如果设置,则优先于REDIS_HOST和REDIS_PORT设置。 49 # REDIS_URL = 'redis的://用户:通过@主机名:9001' 50 51 #定制redis的客户参数(即:套接字超时等) 52 # REDIS_PARAMS = {} 53 #使用自定义redis的客户端类。 54 # REDIS_PARAMS [ 'redis_cls'] = 'myproject.RedisClient' 55 56 #如果为True,则使用redis'``SPOP``操作。您必须使用``SADD`` 57 #命令将URL添加到redis队列。如果你这可能是有用的 58 #要避免在开始的URL列表和重复的顺序 59 #处理无关紧要。 60 # REDIS_START_URLS_AS_SET =假 61 62 #默认启动网址RedisSpider和RedisCrawlSpider关键。 63 # REDIS_START_URLS_KEY = '%(名)S:start_urls' 64 65 #使用除utf-8之外的其他编码进行redis。 66 # REDIS_ENCODING = 'latin1的'
3.配置setting:
# SCHEDULER覆盖原有的,在redis中启用调度存储请求队列 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 确保所有spider通过redis共享相同的重复过滤器 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 配置以便后期插入数据库等操作 ITEM_PIPELINES = { "scrapy_redis.pipelines.RedisPipeline": 300, }

监听,取不到url不会退出,telnet一直监听
4.将网址推送到redis,运行lpush myspider:start_urls 起始url:
不设定redis_key,默认为spider:start_urls:
如:lpush jobbole:start_urls http://blog.jobbole.com/all-posts

5.scrapy-redis源码介绍:
5.1collection.py:
get_redis_from_settings():将所有配置放到dict:params中,用于实例化redis对象。
get_redis():实例化redis对象,from_url方法优先。
5.2defaults.py:
设定默认连接参数。
5.3dupefilter.py(去重类,和scrapy的dupefilter.py几乎一模一样):
clear(self):清除request_fingerprint记录
close(self,reason):结束爬虫爬取时,调用
from_crawler(cls,crawler):类方法,调用from_settings方法初始化
from_settings(cls,settings):类方法初始化,预留钩子
log(self,request,spider):根据传入的debug或者默认显示log
request_fingerprint(self,request):根据请求信息返回经过sha1计算后的值
request_seen(self,request)调用request_fingerprint,判断是否访问过
5.4picklecompat.py:
process_item():调用_process_item。
_process_item():通过rpush方法放到redis的列表里。
5.6queue.py:使用redis制作的队列,有Fifo(先进先出)、Lifo(后进先出)、PriorityQueue(有序集合取第一个)三种
5.7scheduler.py(调度器类):
enqueue_request():不是白名单且访问过的,往队列里放Request对象
next_request():从队列里取值
5.8spiders.py:爬虫类
5.9utils.py:
bytes_to_str():字节转成字符串,默认utf-8

