

asyncio并发编程
一. 事件循环

1.注:
实现搭配:事件循环+回调(驱动生成器【协程】)+epoll(IO多路复用),asyncio是Python用于解决异步编程的一整套解决方案;
基于asynico:tornado,gevent,twisted(Scrapy,django channels),tornado(实现了web服务器,可以直接部署,真正部署还是要加nginx),django,flask(uwsgi,gunicorn+nginx部署)


1 import asyncio 2 import time 3 async def get_html(url): 4 print('start get url') 5 #不能直接使用time.sleep,这是阻塞的函数,如果使用time在并发的情况有多少个就有多少个2秒 6 await asyncio.sleep(2) 7 print('end get url') 8 if __name__=='__main__': 9 start_time=time.time() 10 loop=asyncio.get_event_loop() 11 task=[get_html('www.baidu.com') for i in range(10)] 12 loop.run_until_complete(asyncio.wait(task)) 13 print(time.time()-start_time)
2.如何获取协程的返回值(和线程池类似):
1 import asyncio 2 import time 3 from functools import partial 4 async def get_html(url): 5 print('start get url') 6 await asyncio.sleep(2) 7 print('end get url') 8 return "HAHA" 9 #需要接收task,如果要接收其他的参数就需要用到partial(偏函数),参数需要放到前面 10 def callback(url,future): 11 print(url+' success') 12 print('send email') 13 if __name__=='__main__': 14 loop=asyncio.get_event_loop() 15 task=loop.create_task(get_html('www.baidu.com')) 16 #原理还是获取event_loop,然后调用create_task方法,一个线程只有一个loop 17 # get_future=asyncio.ensure_future(get_html('www.baidu.com'))也可以 18 #loop.run_until_complete(get_future) 19 #run_until_complete可以接收future类型,task类型(是future类型的一个子类),也可以接收可迭代类型 20 task.add_done_callback(partial(callback,'www.baidu.com')) 21 loop.run_until_complete(task) 22 print(task.result())
3.wait和gather的区别:
3.1wait简单使用:
1 import asyncio 2 import time 3 from functools import partial 4 async def get_html(url): 5 print('start get url') 6 await asyncio.sleep(2) 7 print('end get url') 8 9 if __name__=='__main__': 10 loop=asyncio.get_event_loop() 11 tasks=[get_html('www.baidu.com') for i in range(10)] 12 #wait和线程的wait相似 13 loop.run_until_complete(asyncio.wait(tasks))
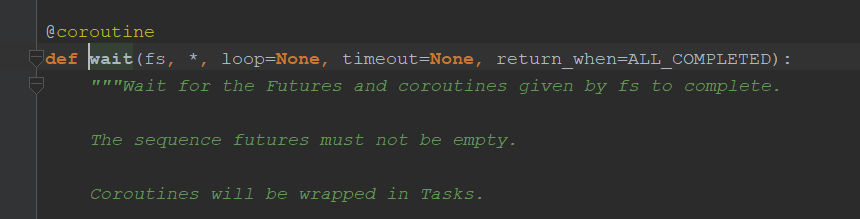
协程的wait和线程的wait相似,也有timeout,return_when(什么时候返回)等参数
3.2gather简单使用:
1 import asyncio 2 import time 3 from functools import partial 4 async def get_html(url): 5 print('start get url') 6 await asyncio.sleep(2) 7 print('end get url') 8 9 if __name__=='__main__': 10 loop=asyncio.get_event_loop() 11 tasks=[get_html('www.baidu.com') for i in range(10)] 12 #gather注意加*,这样就会变成参数 13 loop.run_until_complete(asyncio.gather(*tasks))
3.3gather和wait的区别:(定制性不强时可以优先考虑gather)
gather更加高层,可以将tasks分组;还可以成批的取消任务
1 import asyncio 2 import time 3 from functools import partial 4 async def get_html(url): 5 print('start get url') 6 await asyncio.sleep(2) 7 print('end get url') 8 9 if __name__=='__main__': 10 loop=asyncio.get_event_loop() 11 groups1=[get_html('www.baidu.com') for i in range(10)] 12 groups2=[get_html('www.baidu.com') for i in range(10)] 13 #gather注意加*,这样就会变成参数 14 loop.run_until_complete(asyncio.gather(*groups1,*groups2)) 15 #这种方式也可以 16 # groups1 = [get_html('www.baidu.com') for i in range(10)] 17 # groups2 = [get_html('www.baidu.com') for i in range(10)] 18 # groups1=asyncio.gather(*groups1) 19 # groups2=asyncio.gather(*groups2) 20 #取消任务 21 # groups2.cancel() 22 # loop.run_until_complete(asyncio.gather(groups1,groups2))
二. 协程嵌套
1.run_util_complete()源码:和run_forever()区别并不大,只是可以在运行完指定的协程后可以把loop停止掉,而run_forever()不会停止
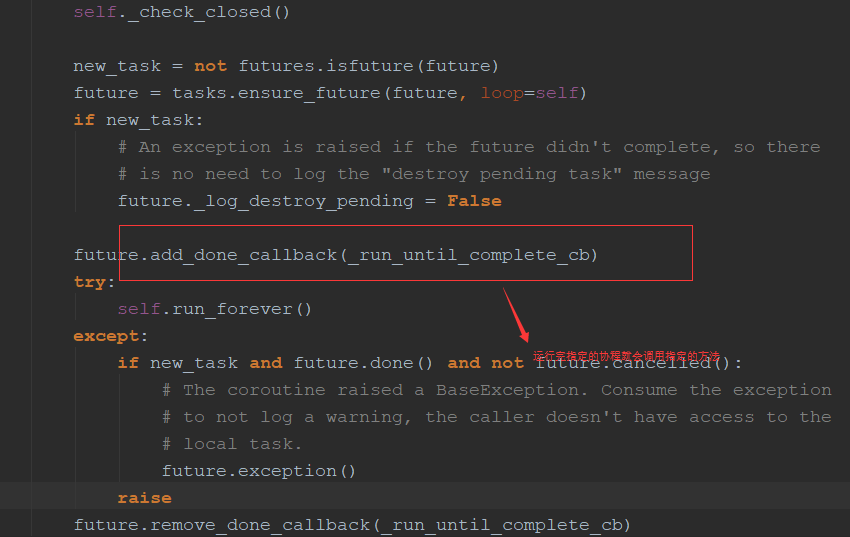

2.loop会被放在future里面,future又会放在loop中
3.取消future(task):
3.1子协程调用原理:
官网例子:

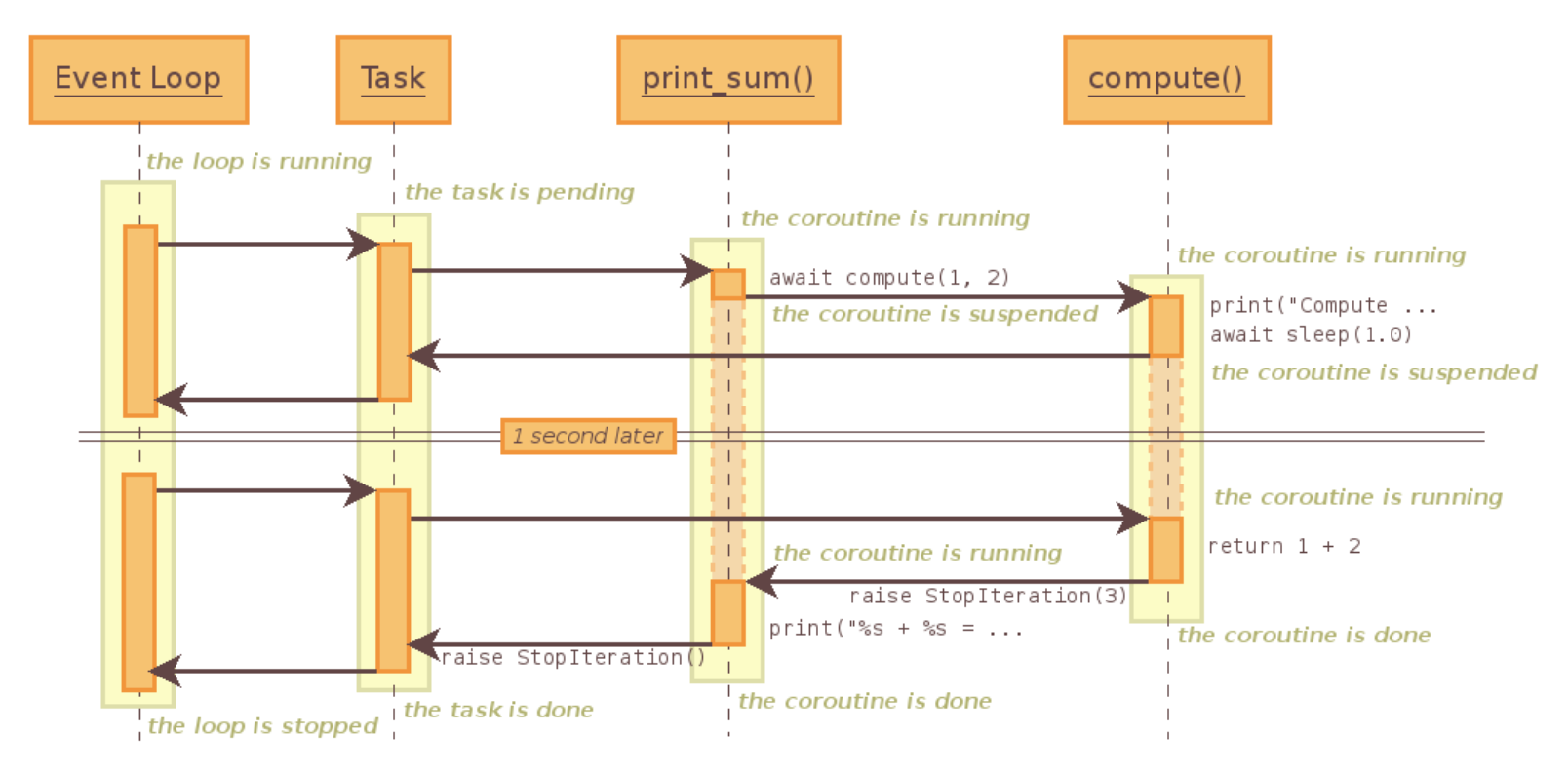
解释: await相当于yield from,loop运行协程print_sum(),print_sum又会去调用另一个协程compute,run_util_complete会把协程print_sum注册到loop中。
1.event_loop会为print_sum创建一个task,通过驱动task执行print_sum(task首先会进入pending【等待】的状态);
2.print_sum直接进入字协程的调度,这个时候转向执行另一个协程(compute,所以print_sum变为suspended【暂停】状态);
3.compute这个协程首先打印,然后去调用asyncio的sleep(此时compute进入suspende的状态【暂停】),直接把返回值返回给Task(没有经过print_sum,相当于yield from,直接在调用方和子生成器通信,是由委托方print_sum建立的通道);
4.Task会告诉Event_loop暂停,Event_loop等待一秒后,通过Task唤醒(越过print_sum和compute建立一个通道);
5.compute继续执行,变为状态done【执行完成】,然后抛一个StopIteration的异常,会被await语句捕捉到,然后提取出1+2=3的值,进入print_sum,print_sum也被激活(因为抛出了StopIteration的异常被print_sum捕捉),print_sum执行完也会被标记为done的状态,同时抛出StopIteration会被Task接收
三. call_soon、call_later、call_at、call_soon_threadsafe
1.call_soon:可以直接接收函数,而不用协程
1 import asyncio 2 #函数 3 def callback(sleep_time): 4 print('sleep {} success'.format(sleep_time)) 5 #通过该函数暂停 6 def stoploop(loop): 7 loop.stop() 8 if __name__=='__main__': 9 loop=asyncio.get_event_loop() 10 #可以直接传递函数,而不用协程,call_soon其实就是调用的call_later,时间为0秒 11 loop.call_soon(callback,2) 12 loop.call_soon(stoploop,loop) 13 #不能用run_util_complete(因为不是协程),run_forever找到call_soon一直运行 14 loop.run_forever()
2.call_later:可以指定多长时间后启动(实际调用call_at,时间不是传统的时间,而是loop内部的时间)
1 import asyncio 2 #函数 3 def callback(sleep_time): 4 print('sleep {} success'.format(sleep_time)) 5 #通过该函数暂停 6 def stoploop(loop): 7 loop.stop() 8 if __name__=='__main__': 9 loop=asyncio.get_event_loop() 10 loop.call_later(3,callback,1) 11 loop.call_later(1, callback, 2) 12 loop.call_later(1, callback, 2) 13 loop.call_later(1, callback, 2) 14 loop.call_soon(callback,4) 15 # loop.call_soon(stoploop,loop) 16 #不能用run_util_complete(因为不是协程),run_forever找到call_soon一直运行 17 loop.run_forever()
3.call_at:指定某个时间执行
1 import asyncio 2 #函数 3 def callback(sleep_time): 4 print('sleep {} success'.format(sleep_time)) 5 #通过该函数暂停 6 def stoploop(loop): 7 loop.stop() 8 if __name__=='__main__': 9 loop=asyncio.get_event_loop() 10 now=loop.time() 11 print(now) 12 loop.call_at(now+3,callback,1) 13 loop.call_at(now+1, callback, 0.5) 14 loop.call_at(now+1, callback, 2) 15 loop.call_at(now+1, callback, 2) 16 # loop.call_soon(stoploop,loop) 17 #不能用run_util_complete(因为不是协程),run_forever找到call_soon一直运行 18 loop.run_forever()
4.call_soon_threadsafe:
线程安全的方法,不仅能解决协程,也能解决线程,进程,和call_soon几乎一致,多了self._write_to_self(),和call_soon用法一致
四. ThreadPoolExecutor+asyncio(线程池和协程结合)
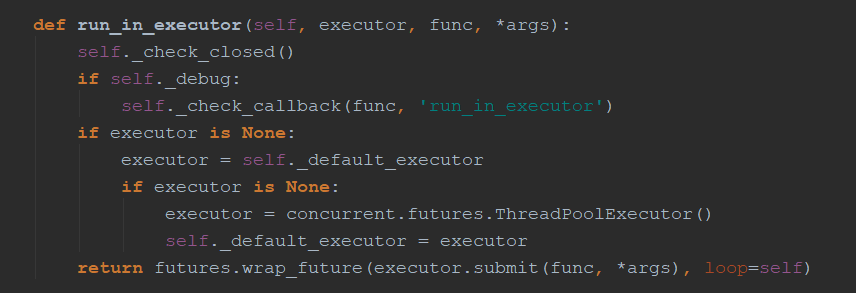
1.使用run_in_executor:就是把阻塞的代码放进线程池运行,性能并不是特别高,和多线程差不多
1 #使用多线程,在协程中集成阻塞io 2 import asyncio 3 import socket 4 from urllib.parse import urlparse 5 from concurrent.futures import ThreadPoolExecutor 6 import time 7 def get_url(url): 8 #通过socket请求html 9 url=urlparse(url) 10 host=url.netloc 11 path=url.path 12 if path=="": 13 path="/" 14 #建立socket连接 15 client=socket.socket(socket.AF_INET,socket.SOCK_STREAM) 16 client.connect((host,80)) 17 #向服务器发送数据 18 client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8")) 19 #将数据读取完 20 data=b"" 21 while True: 22 d=client.recv(1024) 23 if d: 24 data+=d 25 else: 26 break 27 #会将header信息作为返回字符串 28 data=data.decode('utf8') 29 print(data.split('\r\n\r\n')[1]) 30 client.close() 31 32 if __name__=='__main__': 33 start_time=time.time() 34 loop=asyncio.get_event_loop() 35 excutor=ThreadPoolExecutor() 36 tasks=[] 37 for i in range(20): 38 task=loop.run_in_executor(excutor,get_url,'http://www.baidu.com') 39 tasks.append(task) 40 loop.run_until_complete(asyncio.wait(tasks)) 41 print(time.time()-start_time)
五. asyncio模拟http请求
注:asyncio目前没有提供http协议的接口
1 # asyncio目前没有提供http协议的接口 2 import asyncio 3 from urllib.parse import urlparse 4 import time 5 6 7 async def get_url(url): 8 # 通过socket请求html 9 url = urlparse(url) 10 host = url.netloc 11 path = url.path 12 if path == "": 13 path = "/" 14 # 建立socket连接(比较耗时),非阻塞需要注册,都在open_connection中实现了 15 reader, writer = await asyncio.open_connection(host, 80) 16 # 向服务器发送数据,unregister和register都实现了 17 writer.write("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8")) 18 # 读取数据 19 all_lines = [] 20 # 源码实现较复杂,有__anext__的魔法函数(协程) 21 async for line in reader: 22 data = line.decode('utf8') 23 all_lines.append(data) 24 html = '\n'.join(all_lines) 25 return html 26 27 28 async def main(): 29 tasks = [] 30 for i in range(20): 31 url = "http://www.baidu.com/" 32 tasks.append(asyncio.ensure_future(get_url(url))) 33 for task in asyncio.as_completed(tasks): 34 result = await task 35 print(result) 36 37 38 if __name__ == '__main__': 39 start_time = time.time() 40 loop = asyncio.get_event_loop() 41 # tasks=[get_url('http://www.baidu.com') for i in range(10)] 42 # 在外部获取结果,保存为future对象 43 # tasks = [asyncio.ensure_future(get_url('http://www.baidu.com')) for i in range(10)] 44 # loop.run_until_complete(asyncio.wait(tasks)) 45 # for task in tasks: 46 # print(task.result()) 47 # 执行完一个打印一个 48 loop.run_until_complete(main()) 49 print(time.time() - start_time)
六. future和task
1.future:协程中的future和线程池中的future相似

future中的方法,都和线程池中的相似
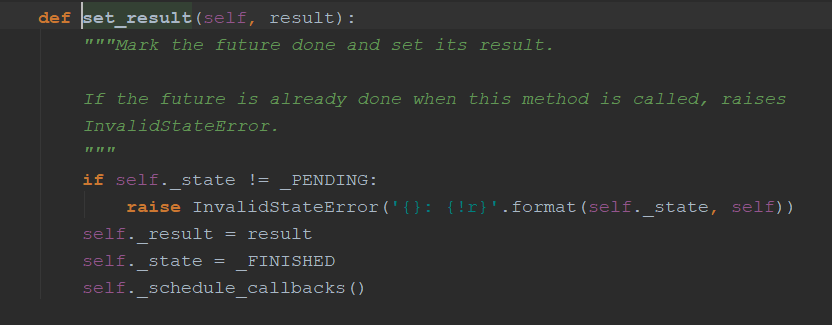
set_result方法
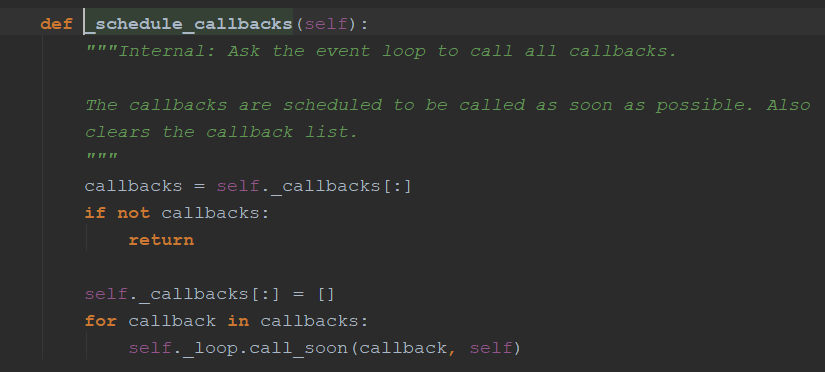
不像线程池中运行完直接运行代码(这是单线程的,会调用call_soon方法)
2.task:是future的子类,是future和协程之间的桥梁
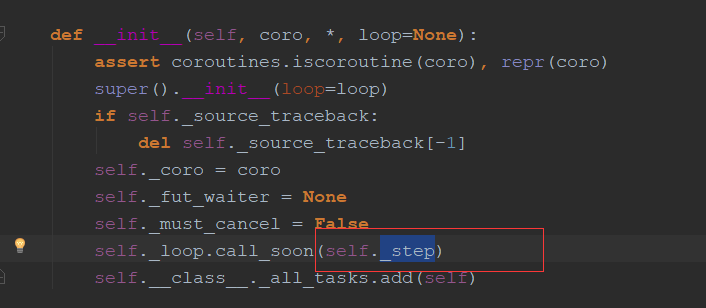
会首先启动_step方法

该方法会首先启动协程,把返回值(StopIteration的值)做处理,用于解决协程和线程不一致的地方
七. asyncio同步和通信
1.单线程协程不需要锁:
1 import asyncio 2 total=0 3 async def add(): 4 global total 5 for i in range(1000000): 6 total+=1 7 8 9 async def decs(): 10 global total 11 for i in range(1000000): 12 total-=1 13 if __name__=='__main__': 14 loop=asyncio.get_event_loop() 15 tasks=[add(),decs()] 16 loop.run_until_complete(asyncio.wait(tasks)) 17 print(total)
2.某种情况需要锁:
asyncio中的锁(同步机制)
1 import asyncio,aiohttp 2 #这是并没有调用系统的锁,只是简单的自己实现(注意是非阻塞的),Queue也是非阻塞的,都用了yield from,不用用到condition【单线程】】 3 #Queue还可以限流,如果只需要通信还可以直接使用全局变量否则可以 4 from asyncio import Lock,Queue 5 catche={} 6 lock=Lock() 7 async def get_stuff(): 8 #实现了__enter__和__exit__两个魔法函数,可以用with 9 # with await lock: 10 #更明确的语法__aenter__和__await__ 11 async with lock: 12 #注意加await,是一个协程 13 #await lock.acquire() 14 for url in catche: 15 return catche[url] 16 #异步的接收 17 stauff=aiohttp.request('Get',url) 18 catche[url]=stauff 19 return stauff 20 #release是一个简单的函数 21 #lock.release() 22 23 async def parse_stuff(): 24 stuff=await get_stuff() 25 26 async def use_stuff(): 27 stuff=await get_stuff() 28 #如果没有同步机制,就会发起两次请求(这里就可以加一个同步机制) 29 tasks=[parse_stuff(),use_stuff()] 30 loop=asyncio.get_event_loop() 31 loop.run_until_complete(asyncio.wait(tasks))
八. aiohttp实现高并发爬虫
1 # asyncio去重url,入库(异步的驱动aiomysql) 2 import aiohttp 3 import asyncio 4 import re 5 import aiomysql 6 from pyquery import pyquery 7 8 start_url = 'http://www.jobbole.com/' 9 waiting_urls = [] 10 seen_urls = [] 11 stopping = False 12 #限制并发数 13 sem=asyncio.Semaphore(3) 14 15 16 async def fetch(url, session): 17 async with sem: 18 await asyncio.sleep(1) 19 try: 20 async with session.get(url) as resp: 21 print('url_status:{}'.format(resp.status)) 22 if resp.status in [200, 201]: 23 data = await resp.text() 24 return data 25 except Exception as e: 26 print(e) 27 28 29 def extract_urls(html): 30 ''' 31 解析无io操作 32 ''' 33 urls = [] 34 pq = pyquery(html) 35 for link in pq.items('a'): 36 url = link.attr('href') 37 if url and url.startwith('http') and url not in urls: 38 urls.append(url) 39 waiting_urls.append(url) 40 return urls 41 42 43 async def init_urls(url, session): 44 html = await fetch(url, session) 45 seen_urls.add(url) 46 extract_urls(html) 47 48 49 async def handle_article(url, session, pool): 50 ''' 51 处理文章 52 ''' 53 html = await fetch(url, session) 54 seen_urls.append(url) 55 extract_urls(html) 56 pq = pyquery(html) 57 title = pq('title').text() 58 async with pool.acquire() as conn: 59 async with conn.cursor() as cur: 60 insert_sql = "insert into Test(title) values('{}')".format(title) 61 await cur.execute(insert_sql) 62 63 64 async def consumer(pool): 65 with aiohttp.CLientSession() as session: 66 while not stopping: 67 if len(waiting_urls) == 0: 68 await asyncio.sleep(0.5) 69 continue 70 url = waiting_urls.pop() 71 print('start url:' + 'url') 72 if re.match('http://.*?jobble.com/\d+/', url): 73 if url not in seen_urls: 74 asyncio.ensure_future(handle_article(url, session, pool)) 75 await asyncio.sleep(30) 76 else: 77 if url not in seen_urls: 78 asyncio.ensure_future(init_urls(url, session)) 79 80 81 async def main(): 82 # 等待mysql连接好 83 pool = aiomysql.connect(host='localhost', port=3306, user='root', 84 password='112358', db='my_aio', loop=loop, charset='utf8', autocommit=True) 85 async with aiohttp.CLientSession() as session: 86 html = await fetch(start_url, session) 87 seen_urls.add(start_url) 88 extract_urls(html) 89 asyncio.ensure_future(consumer(pool)) 90 91 if __name__ == '__main__': 92 loop = asyncio.get_event_loop() 93 asyncio.ensure_future(loop) 94 loop.run_forever(main(loop))
