

目标检测算法(一):R-CNN详解
参考博文:https://blog.csdn.net/hjimce/article/details/50187029
R-CNN(Regions with CNN features)--2014年提出
算法流程
1.输入一张图片,通过selective search算法找出2000个可能包括检测目标的region proposal(候选框)
2.采用CNN提取候选框中的图片特征(AlexNet输出特征向量维度为4096)
3.使用SVM对特征向量分类
4.bounding-box regression修正候选框位置
(一)候选框搜索
通过selective search算法可以搜索出2000个大小不同的矩形框,得到对应的坐标
遍历候选框:
对候选框进行筛选,去掉重复的、太小的方框等,假设剩余1500个。截取剩余的方框对应的图片,得到了1500张图片
由于CNN对输入图片的大小有要求,需要对以上图片进行缩放处理,方法有:各向异性缩放、各向同性缩放。缩放到CNN要求的大小
根据IOU对每一张图片进行标注,如IOU>0.5标注为目标类别(正样本),否则为背景类别(负样本)
我的理解:每一张原始图片都会生成1500个训练样本
(二)CNN提取特征
可选网络结构:AlexNet,Vgg-16
预训练:有监督预训练
物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。
这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,文献采用的是有监督的预训练。
有监督预训练,我们也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,
用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,
去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,
拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。
图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,
这篇paper采用了迁移学习的思想。文献就先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络的图片分类训练。
这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段cnn模型的输出是1000个神经元,
或者我们也直接可以采用Alexnet训练好的模型参数。
fine-tuning
将最后一层的输出层单元数修改为目标检测的类别数+1,多出的一类为背景。输出层参数采用随机初始化,之前的参数不变。继续对网络进行训练。
(三)训练SVM
CNN最后的softmax层可以做分类,在论文中为什么要把softmax层换成SVM进行分类?
因为SVM和CNN分类时的正负样本定义不同,导致CNN+softmax输出比SVM精度要低。由于CNN容易过拟合,需要大量的训练样本,
所以CNN的样本标注比较宽松,IOU>0.5即标记为正样本。SVM适用于小样本训练,对样本的IOU要求较高,在训练时,IOU>0.7时标记为正样本。
由于SVM是二分类器,因此对每一个类别都需要训练一个SVM
(四)Bounding Box Regression--边框回归
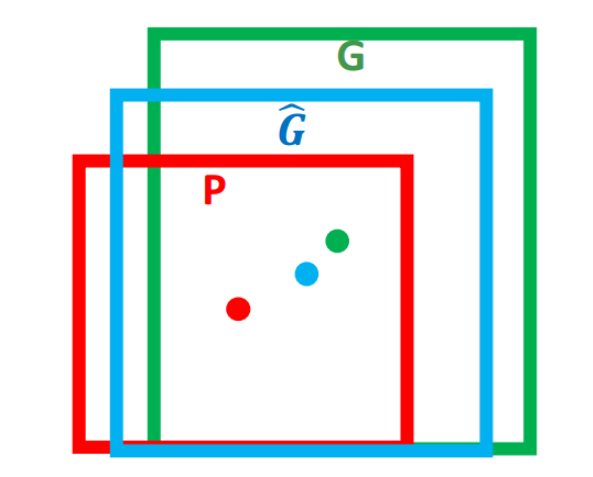
任务描述:G为目标边框(人为标注),P为网络计算得到的边框。边框回归的任务是计算从P到G^的映射f,使P经过映射以后得到与真实窗口G
更接近的G^
思路:平移+尺度缩放
输入:(训练时)CNN提取到的该边框的特征+Ground Truth即G的坐标
(预测时)CNN提取到的该边框的特征
输出:需要进行的平移量和尺度缩放量,即P到G^的映射,包括4个值:Δx,Δy,Sw,Sh
通过计算得到新的回归框

