
典型的网络结构总结
引自:https://blog.csdn.net/chenyuping333/article/details/82526440 https://www.cnblogs.com/zhhfan/p/10187634.html
(1)LeNet:元老级框架,结构简单,却开创了卷积神经网络的新纪元,具有重要的学习价值。
(2) AlexNet:打开了深度学习的大门,深度学习成为学术界的新宠。主要意义在于验证了神经网络的有效性,为后续的发展提供了参考。
(3)ZF-Net:这个在Alex上改进较少,主要贡献是2点:
a)由AlexNet的双GPU改为单GPU上训练;
b)对神经网络的每一层都进行了可视化,这是最主要的贡献。
(4)VGG-Net:在AlexNet的基础上,提出了更深的网络,分别为VGG-16和VGG-19,参数是AlexNet的三倍,为后面的框架提供了方向:加深网络的深度。
(5)GoogLeNet:有四个版本,主要是在网络宽度上进行了改进,不像VGG-Net只是单纯增加深度,在同一层中使用了多个不同尺寸的卷积,以获得不同的视野,最后级联(直接叠 加通道数量),这就是Inception module从v2开始,进一步简化把Inception module中的n×n模块分解为1×n和n×1的组合,减少了参数数量,v3进一步把最开始的7×7卷积和其他非 3×3进行分解,v4引入了ResNet残差的思想。
(6)ResNet:首次提出了残差的思想(跨层连接,即),解决了网络过深而导致的梯度消失的问题,为更深的网络提供了有力的方向。注意:
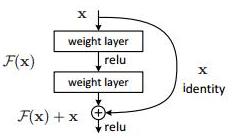
a)此处的跨层连接的计算方式和GoogLeNet中的级联不同,这里是每个通道进行相加操作,如果的通道数和的通道数不同,则对用1×1的卷积操作,使得维度一样;
b)有有两个版本v1和v2,v2只是引入了BN(banch normalization),并讨论的BN放置位置的问题,其他思想一样。
(7)DenseNet:比ResNet来的更加彻底,即当前的每一层都和前面的每一层连接。这里有两点值得注意:

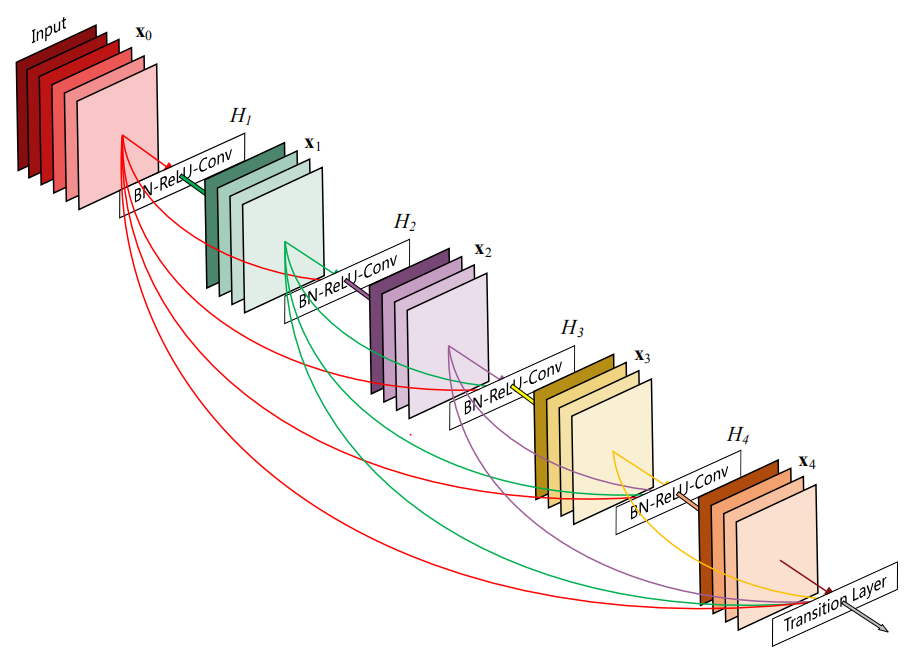
a)为了解决每个输入的尺寸不一样的问题,因此提出了Dense block,即在这个模块中才进行每一层的连接,这样便于控制输入尺寸的大小,Dense block模块之间就可以放心的使 用池化操作了;
b)此处的连接的计算方式为级联(直接叠加通道数量),和GoogLeNet一样,和ResNet不同。
(8)ResNeXt:在ResNet的基础上,借鉴GoogLeNet的思想,增加了网络的宽度,同时,为了简化设计的复杂度,不像Inception module里面采用了不同尺寸的卷积,这里使用相同 的的卷积,并用了32个,最后每个通道相加,和Inception module的级联不同。
(9)DPN:一种双通道网络,结合了ResNet和DenseNet的优点,具有一定的参考价值。

