VGG16学习
引自:https://www.cnblogs.com/lfri/p/10493408.html
摘要
本文对图片分类任务中经典的深度学习模型VGG16进行了简要介绍,分析了其结构,并讨论了其优缺点。调用Keras中已有的VGG16模型测试其分类性能,结果表明VGG16对三幅测试图片均能正确分类。
前言
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
结构
VGG中根据卷积核大小和卷积层数目的不同,可分为A,A-LRN,B,C,D,E共6个配置(ConvNet Configuration),其中以D,E两种配置较为常用,分别称为VGG16和VGG19。
下图给出了VGG的六种结构配置:
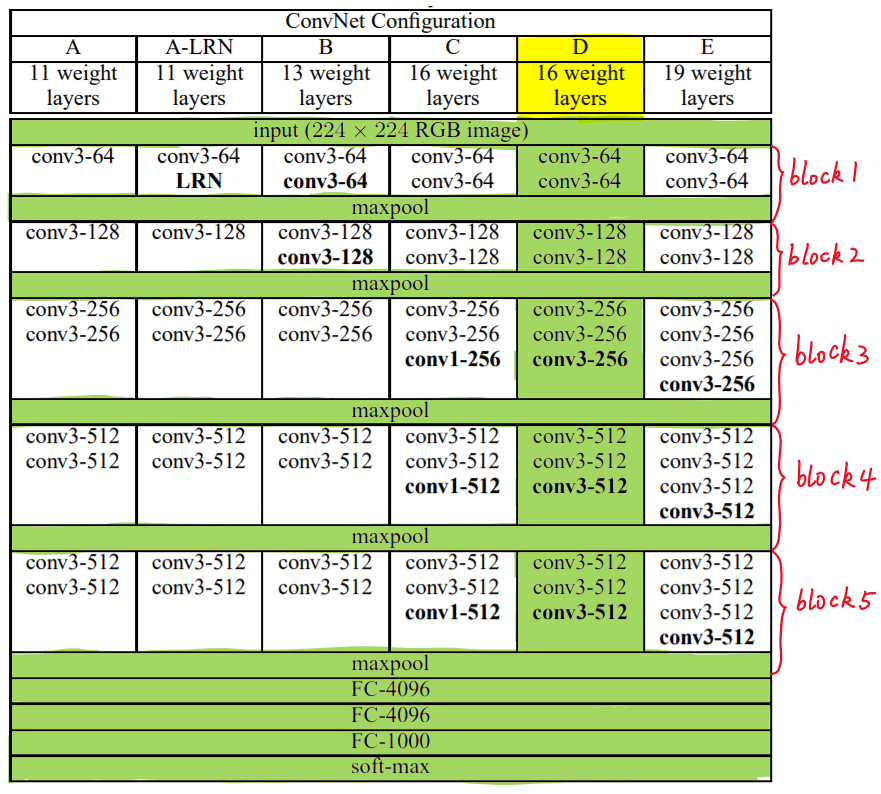
上图中,每一列对应一种结构配置。例如,图中绿色部分即指明了VGG16所采用的结构。
我们针对VGG16进行具体分析发现,VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用conv3-XXX表示
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是
VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
特点
VGG16的突出特点是简单,体现在:
-
卷积层均采用相同的卷积核参数
卷积层均表示为
conv3-XXX,其中conv3说明该卷积层采用的卷积核的尺寸(kernel size)是3,即宽(width)和高(height)均为3,3*3是很小的卷积核尺寸,结合其它参数(步幅stride=1,填充方式padding=same),这样就能够使得每一个卷积层(张量)与前一层(张量)保持相同的宽和高。XXX代表卷积层的通道数。 -
池化层均采用相同的池化核参数
池化层的参数均为2××2,步幅stride=2,max的池化方式,这样就能够使得每一个池化层(张量)的宽和高是前一层(张量)的1212。
-
模型是由若干卷积层和池化层堆叠(stack)的方式构成,比较容易形成较深的网络结构(在2014年,16层已经被认为很深了)。
综合上述分析,可以概括VGG的优点为: Small filters, Deeper networks.
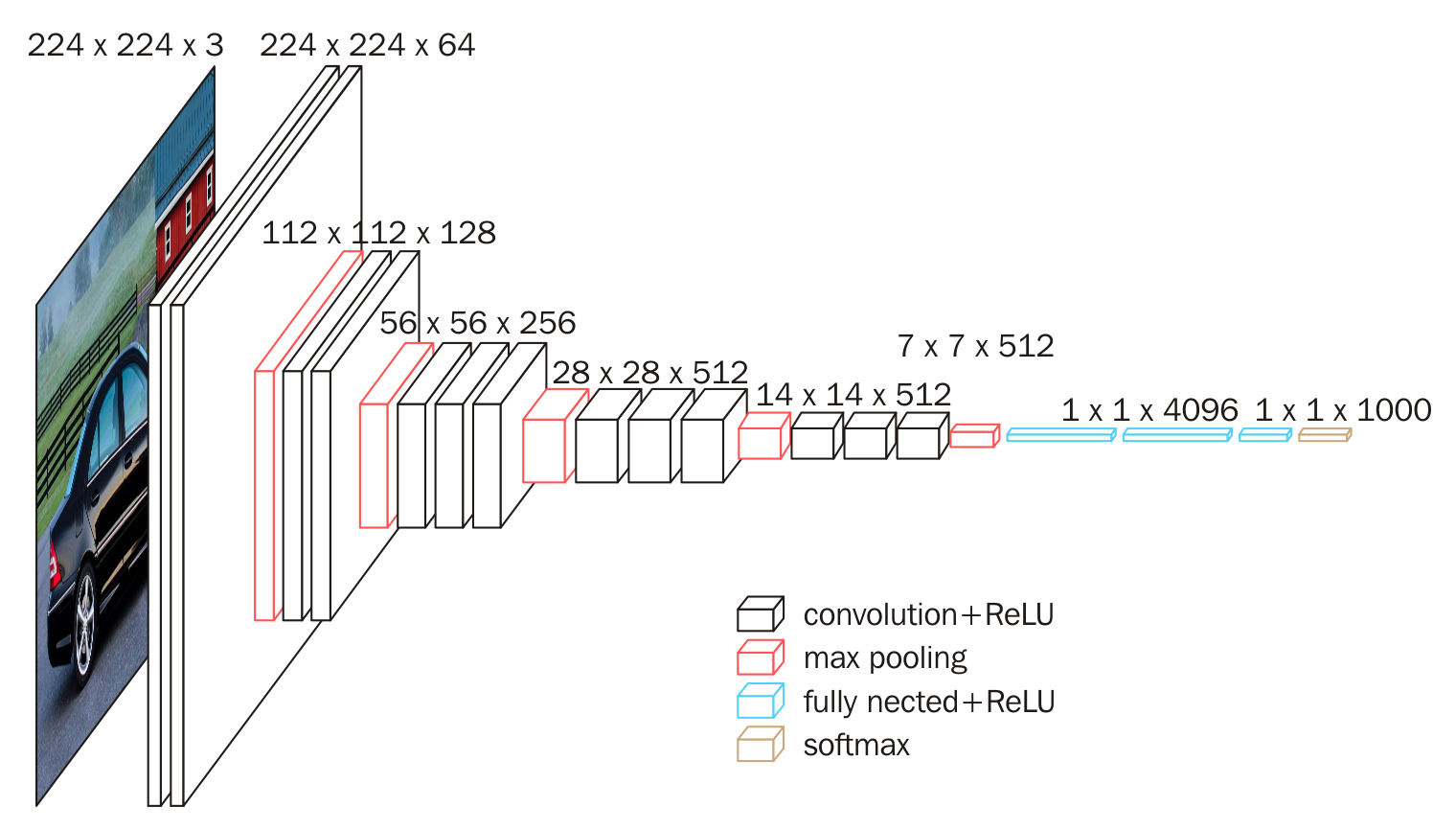
块结构
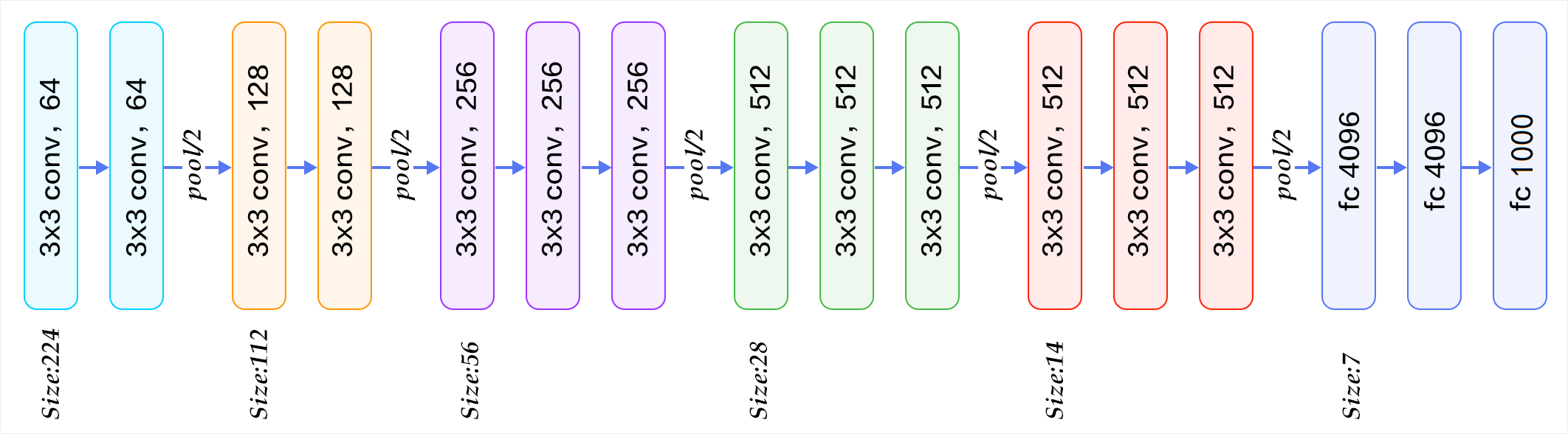
我们注意图1右侧,VGG16的卷积层和池化层可以划分为不同的块(Block),从前到后依次编号为Block1~block5。每一个块内包含若干卷积层和一个池化层。例如:Block4包含:
- 3个卷积层,conv3-512
- 1个池化层,maxpool
并且同一块内,卷积层的通道(channel)数是相同的,例如:
block2中包含2个卷积层,每个卷积层用conv3-128表示,即卷积核为:3x3x3,通道数都是128block3中包含3个卷积层,每个卷积层用conv3-256表示,即卷积核为:3x3x3,通道数都是256
下面给出按照块划分的VGG16的结构图,可以结合图2进行理解:
VGG的输入图像是 224x224x3 的图像张量(tensor),随着层数的增加,后一个块内的张量相比于前一个块内的张量:
- 通道数翻倍,由64依次增加到128,再到256,直至512保持不变,不再翻倍
- 高和宽变减半,由 224→112→56→28→14→7
权重参数
尽管VGG的结构简单,但是所包含的权重数目却很大,达到了惊人的139,357,544个参数。这些参数包括卷积核权重和全连接层权重。
- 例如,对于第一层卷积,由于输入图的通道数是3,网络必须学习大小为3x3,通道数为3的的卷积核,这样的卷积核有64个,因此总共有(3x3x3)x64 = 1728个参数
- 计算全连接层的权重参数数目的方法为:前一层节点数×本层的节点数前一层节点数×本层的节点数。因此,全连接层的参数分别为:
-
- 7x7x512x4096 = 1027,645,444
- 4096x4096 = 16,781,321
- 4096x1000 = 4096000
FeiFei Li在CS231的课件中给出了整个网络的全部参数的计算过程(不考虑偏置),如下图所示:

图中蓝色是计算权重参数数量的部分;红色是计算所需存储容量的部分。
VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力;但同时缺点也很明显:
- 即训练时间过长,调参难度大。
- 需要的存储容量大,不利于部署。例如存储VGG16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
实践
下面,我们应用Keras对VGG16的图像分类能力进行试验。
Keras是一个高层神经网络API,Keras由纯Python编写 ,是tensorflow和Theano等底层深度学习库的高级封装 。使用Keras时,我们不需要直接调用底层API构建深度学习网络,仅调用keras已经封装好的函数即可。
本次试验平台:python 3.6 + tensorflow 1.8 + keras 2.2,Google Colab
源代码如下:

1 # -*- coding: utf-8 -*-
2 """
3 Spyder Editor
4
5 This is a temporary script file.
6 """
7 import matplotlib.pyplot as plt
8
9 from keras.applications.vgg16 import VGG16
10 from keras.preprocessing import image
11 from keras.applications.vgg16 import preprocess_input, decode_predictions
12 import numpy as np
13
14 def percent(value):
15 return '%.2f%%' % (value * 100)
16
17 # include_top=True,表示會載入完整的 VGG16 模型,包括加在最後3層的卷積層
18 # include_top=False,表示會載入 VGG16 的模型,不包括加在最後3層的卷積層,通常是取得 Features
19 # 若下載失敗,請先刪除 c:\<使用者>\.keras\models\vgg16_weights_tf_dim_ordering_tf_kernels.h5
20 model = VGG16(weights='imagenet', include_top=True)
21
22
23 # Input:要辨識的影像
24 img_path = 'frog.jpg'
25
26 #img_path = 'tiger.jpg' 并转化为224*224的标准尺寸
27 img = image.load_img(img_path, target_size=(224, 224))
28
29
30 x = image.img_to_array(img) #转化为浮点型
31 x = np.expand_dims(x, axis=0)#转化为张量size为(1, 224, 224, 3)
32 x = preprocess_input(x)
33
34 # 預測,取得features,維度為 (1,1000)
35 features = model.predict(x)