高并发场景案例分享(二)count实时查询之坑
上一篇主要从设计层面,分享了一些小经验。
因软件系统有其复杂性和多样性,不同的场景、架构下,系统的瓶颈各不相同。
文章里的一些想法和设计并不通用,主要针对的是高并发场景下海量数据的实时查询。
这次再分享一个更贴近生活的案例。
有时看似简单的逻辑,往往隐藏了最深的坑,甚至成为系统的性能瓶颈。
举个栗子
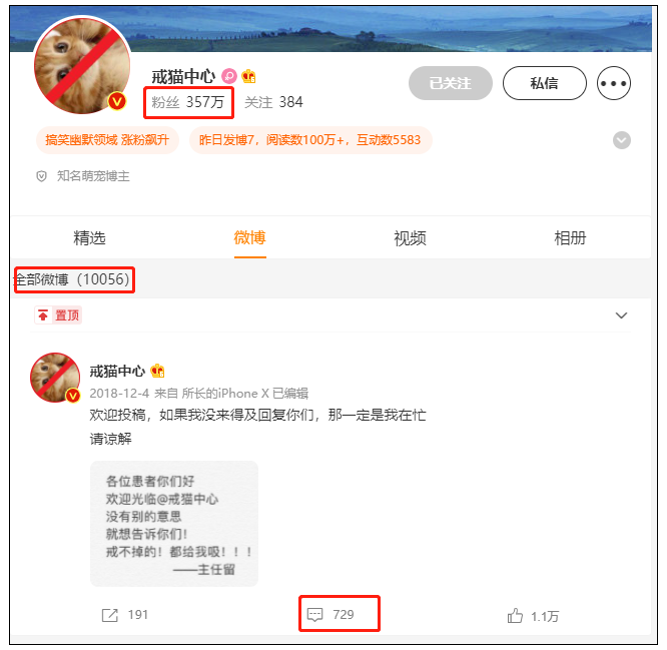
微博用户主页
这个页面应该都不陌生,业务也并不复杂。
值得注意的是红线圈出的功能:粉丝数量,微博总数,评论、转发、点赞数量。
乍一看很简单,再一看还是很简单。
根据条件,从相关的业务表统计数量就好了呀。
比如, 从好友关系表count所有关注作者的人( type = 2 代表被关注)。
select count(1) from user_relation where uid = 'xxx' and type = 2
没毛病啊,十分合理。这么简单的东西难道还能玩出花来?

第一版上线时
我就是这么做的,结果整个服务直接挂掉了。
看了下监控,发现量变竟然引发了质变。
在系统数据量不大或流量不高时,使用count查询来处理此业务没有任何问题。
当数据达到一定量级时,比如图中的粉丝量300W+,如果查询的结果集数量过大,即便根据索引查询,正常耗时也会达到几秒、十几秒,更别说在高并发下频繁查询。
用户主页,一页查询15条动态,每条动态都要显示转发、评论、点赞数,总共需要count45次。
再加上微博上亿的用户量,超高的并发,此处若实时地使用count查询,将轻松GET以下异常:
The last packet sent successfully to the server was 5,652 milliseconds ago
因为MySQL服务器所有的线程都用来执行这些count慢查询了,导致后面的请求全部阻塞。
此时,数据库性能监控面板会有一些显著的指标特征:CPU负载达到100%,运行线程数异常高。
第二版上线时
我专门加了一张表用来计数, 类似 (动态id, 点赞数, 评论数, 转发数 )这样的结构。
每次用户点赞、评论、转发时,直接在表上写入数量+1。
查询时直接从此表读取数量,避免count查询。
解决方法虽简单了些,能搞定性能上的瓶颈即可。
此前,也参考过一些关于微博架构的资料,里面有提到计数器服务。(如:https://www.cnblogs.com/kenshinobiy/p/4316217.html。)
但当时并没理解为什么要做计数器?什么数这么吊还要专门做个服务来计算?
微信朋友圈
微信朋友圈
朋友圈的设计,就完全不用展示数量。
直接避开了很多可能给系统带来性能瓶颈的坑。
相比之下,微信的工程师一定能少掉不少头发。
当然,二者社交场景不同,介质也不同(WEB | APP),有些产品上的设计是不可避免的。

综上
在MySQL进行实时查询时,应该避免查询出的结果集数量过大。
否则,即使像count这样最简单的查询语句,也可能带来性能问题。
当然,最终还是要看具体的使用场景。
比如,一个用来汇总每日报表的查询语句,使用了 union,group by 等性能不佳的子句,整个查询耗时5秒。
但它每天只执行一次,且查询的数据表并不频繁使用。即便这是一条慢查询,对性能的影响也是微乎其微。
而像案例中的count语句,即便耗时只有1秒,如果每秒请求1000次,那它对数据库CPU的消耗就是前者的200倍。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!