高并发场景案例分享(一)分库分表
今年在公司重构(写)了一个老项目,踩了无数的坑。
中间好几次遇到问题,甚至感觉项目可能要失败了,好在最后终于成功上线了。
虽然被坑的不要不要的,但也从中领悟到了不少东西,在这里记录一下,顺便分享给大家乐呵乐呵。
先简单介绍下项目,一个面向C端用户的服务,主要提供包括动态、评论、圈子、好友、关注、Feed等常见的社区功能,另外还有其他一些个性化的功能。
日活比较高,整个服务QPS上万。高频业务,单个接口QPS上千。单项业务数据量过亿,比如评论。
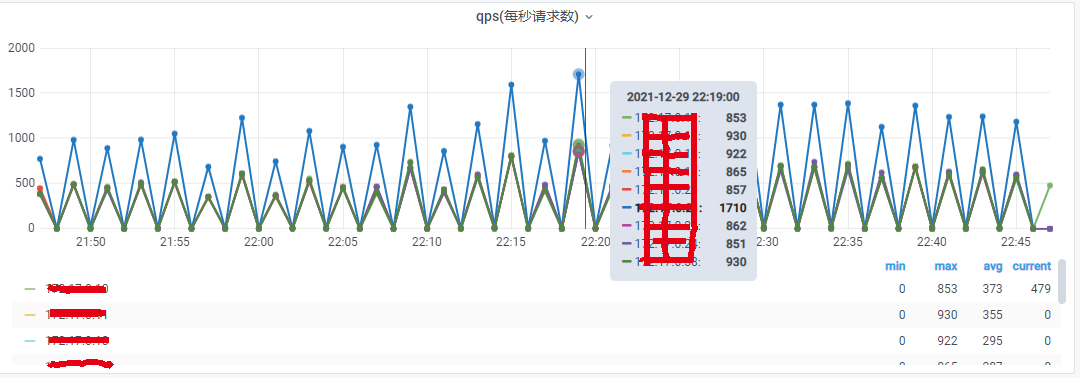 图1.qps监控图
图1.qps监控图
在上述高并发、海量数据的情况下,整个系统设计时需要注意的坑,和我总结的一些经验:
数据库层面
MySQL分库分表
因为是重写整个项目,包括重新设计底层数据库,必然要考虑到分库分表。
最初在网上参考了一些分库分表的原则,实际操作中,发现大部分资料都有些缥缈。
如果是简单的应用怎么分表,甚至不分都可以。所以这些原则你也不能说它是错的,但在你最需要参考的时候,这些原则往往不够深入。
分享下我个人总结的一些经验:
先说分库
分库的主要目标,应该是缓解主库(Master)的压力。
绝大部分服务都是读多写少,在读写分离,1主1备N从的情况下,即便为了保证一致性,部分读请求路由到主库,主库压力依旧很低。
通过监控服务的写请求量和数据库服务器的CPU压力等性能指标,只要主库压力不大,就没必要分库。读库如果压力大,直接加从库实例即可。
一种极端的情况,就是分表数量过多了,一个库里表数量递增,成万上亿了,那还是分库的好。
还有一点,从运维的角度考虑,单库冷备,数据不应该超过500GB。如果单库数据量达到1个TB,运维也不好备份,为了正常备份也要分库。
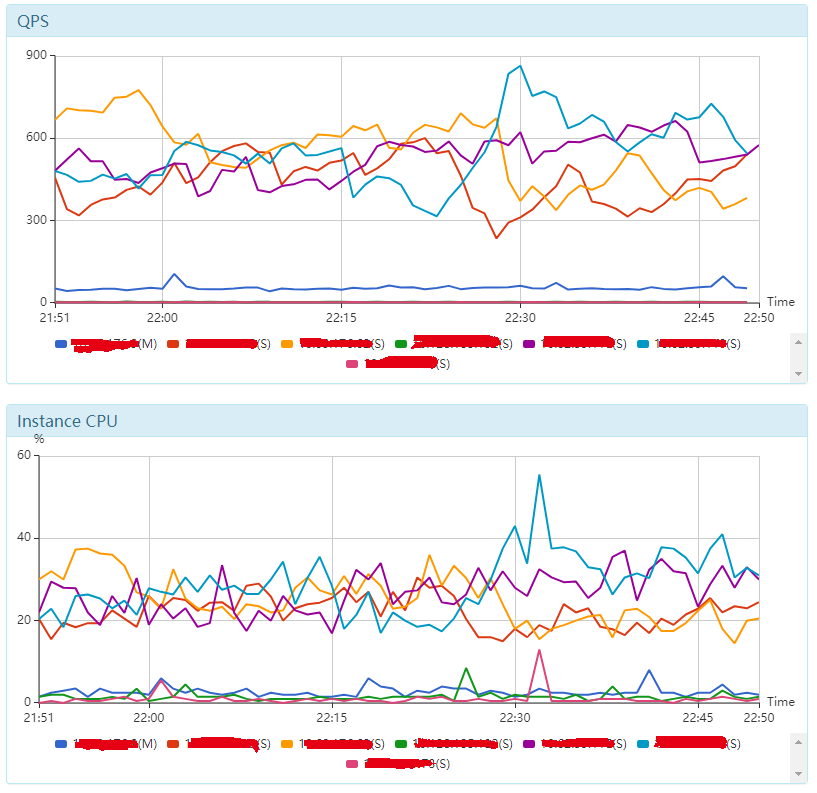
图2.数据库监控图(图中蓝色线条代表主库,基本上是趴着不动躺平的)
再说分表
在请求量不大 或 数据量不大的情况下,分不分表都无所谓。
考虑mysql的性能、树的深度等,可以简单的认为单表500W左右即可。
但实际中往往需要结合具体的业务设计和查询场景。
比如,1张几千万数据量的订单表,如果业务上,只需要根据主键或唯一索引,每次查询一条记录,那么不分表也是完全可行的。
但有时出于运维需要,分表会更方便一些,比如研发人员可能会想手写一些SQL上去进行一些范围查询,为排查问题提供一些方便。(这里说的方便是指相对单表几千万,如果查询字段没有索引,范围查询基本不可用。当然从操作步骤上看,肯定比查1个表繁琐了)
特别需要注意的是,如果一项业务数据需要高频的用到 count语句查询总数 或 order by进行排序,我建议分的表越多越好,管他3721先分1000张表再说。
多分表的好处就是,只要表中的数据量足够少,即便你索引设计的不好,甚至查询完全不走索引,也不容易产生慢查询。哈哈哈!
小结:这次重构就被老系统的1000张表给坑了,因为每张表只有几万条数据,我觉得太浪费了, 想当然的缩到了20张表。
但又没有很好的去分析查询场景,设计索引。导致上线时,只放了1%的量,就崩了,看监控全部都是慢查询。
当然,最终我是通过优化索引来解决慢查询,而不是加分表数量。但在有些情况下,这也是一种思路。
MySQL索引、字段设计
之前自己设计表,总喜欢加些固定字段,比如create_time, create_user, is_delete等,因为运维方便。
重构了这个系统之后发现,在高并发海量数据的情况下,性能是首要问题,有时候多加这些字段反而成了负担。(当然,大部分情况下,create_time还是必要的)
字段能少则少,名字能短则短,类型能用tinyint就不要用int。

“桌子有多小就要多小,椅子有多挤就要多挤,不要让客人坐得那么舒服,吃完就赶快走。吸管有多粗就要多粗,冰有多大块就放多大块,这样汽水就可以一口喝完再买另一杯了。你是新来的吗,这还要我教,一点变通都不会,笨蛋。”
——周星驰《食神》
索引这块低频小数据量无所谓,高频海量数据务必所有查询走索引。
再看一些实际例子,
1. is_delete 字段(逻辑删除)
假设以评论为例,单表500w,单条动态下平均上万条评论。
业务场景中要查询动态下的所有评论,where 子句要加上条件 is_delete = 0。
如果查询出符合条件的结果集,有几万甚至十几万条,不把 is_delete 字段加到联合索引中,这必将是一条慢查询,再加上高并发,只要几百的qps,很容易把服务打崩。
每个查询加上这么一个条件又有点画蛇添足,除非运维需要,基本上不会有业务要查询 is_delete = 1的情况。索性直接物理删除,再加个归档表,要找回时,去归档表里找。
这样就不用在每个联合索引里多加一个字段了。
2. tinyint 和 int
tinyint 主要用于一些状态标志位,比如 审核状态:0-未审核 1-审核通过 2-审核未通过。
使用tinyint 一是节约空间,二是方便识别,一看就知道是标志位。
另外这种标志位经常出现在查询条件中,但又不会单独作为查询条件,因此建立索引时,必然是在联合索引中出现。而联合索引是有长度限制的,虽然大部分时候都不会遇到,但还是值得注意。
另外有的人标志位喜欢用byte,但在代码里要转型就很蛋疼了。
3.联合索引的设计
就一个原则:查询条件里有的,都加进去。
除了要把 where 子句中的条件字段加进去外,在有order by 的情况下,还要把 order by 的字段加到最后。
比如:查询动态id是123,状态是审核通过且上线的20条评论,按时间倒序排列。
select * from comment where news_id = 123 and audit_status = 1 and online_status = 1 order by ctime desc limit 20
那我们应该建立联合索引 news_id, audit_status, online_status, ctime
注意:在网上参考资料时,很多都说索引的建立原则,字段的区分度要高。
个人感觉这个原则并没什么道理,至少在建立联合索引时不适用。
在建立单一索引时,我也没有想到适用的具体场景。
比如有单表5千万条身份信息,其中20条gender=1,5千万条gender=0。
如果你就是要查询gender=1的列表,如果不在gender列建立索引,即便只有20条数据,也必然是个慢查询。
小结:索引的建立,必须针对具体的查询语句。结合实际查询场景,去考虑如何创建索引。

