ferrero项目的思考
一、做一个项目的过程当中必然会遇到很多问题
客户变更、自己对需求的理解不到位。代码不够严谨,bug众多
我们应该要养成一个好习惯,开发的过程的当中做好记录,遇到的问题,记录下来。
要做的功能多思考,最大程度上避免测试让你修改bug
## 平时说的一些业务上的需求,我没有很认真的记下来,应该写到txt里,我只是凭记忆,
而记忆不是个很靠谱的东西。
一些问题,难搞的。忙的时候暂时没有解决,也没有记录,暂时没有被发现,我就忽略了。
等到最后这些问题你还是要解决的,我应该记录下来,如果暂时没有空解决,等后面有空了,去解决。
换而言之,我并没有很认真的去对待这些接口,每一个查询,每一个功能,是否做到满足了需要?
满足业务需求,性能也ok
1.1 从第三方拿数据,我一直以为是他们提供SFTP, 我们到时候去拿,就等啊等,最后要联调了我问
他们的sftp呢,说是我们自己的sftp,然后sftp配置在其他人哪里。。
所以这个要早点问,不然自己早就可以调试了。
自己在调试SFTP时也遇到了问题,之前用过好几次sftp 都ok,但是对于这个的理解太浅显。
这次算是认识更深刻了,以后再做sftp应该更加得心应手了
bug1
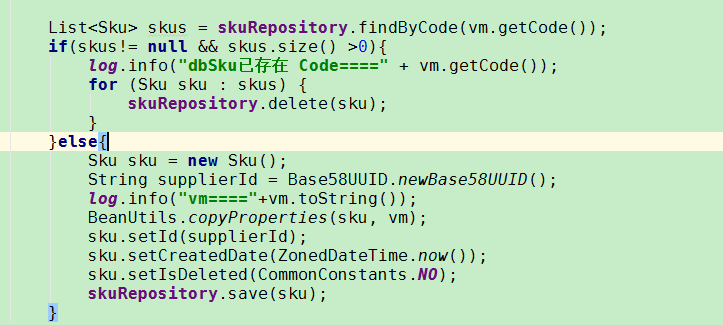
第三方数据入库,根据主键业务编码,查询,返回List 存在直接delete
然后统一入库
感悟
一开始考虑功能,其次要考虑性能。考虑数据量大不大。
如果优化,索引,查询字段等待方式
bug2
申请序列码功能
切面报错

RequestContextHolder.getRequestAttributes() 空指针,其他方法ok
一查发现,我的方法是在@Async注解下,异步无法获取request,解决办法,不让切面切到。
切面切的是service的create、update等方法,修改方法名不匹配即可
BUG 序列码申请功能速度很慢
序列码生成,需要查询最大的流水号,然后生成的数字递增
发现mongodb第一次查询的时候速度非常慢


Query query = new Query(); query.with(new Sort(Sort.Direction.DESC, "snNo")); query.skip(0);// 从那条记录开始 query.limit(1);// 取多少条记录 List<SerialNumber> list = mongoTemplate.find(query, SerialNumber.class); if (ListUtil.isEmpty(list)) { return 0; } return list.get(0).getSnNo();
MongoCursor<Document> cursor = mongoTemplate.getCollection("serialNumber").find().sort(Filters.and(Arrays.asList(
Filters.eq("snNo", -1)))).skip(0).limit(1).iterator();
//List<SerialNumber> list= new ArrayList<>();
while (cursor.hasNext()) {
JSONObject jsonObject = JSONObject.parseObject(cursor.next().toJson().toString());
JSONObject snNoLong = JSONObject.parseObject(jsonObject.getString("snNo"));
Long snNo = snNoLong.getLong("$numberLong");
//String snNo = jsonObject.getString("snNo");
log.info("snNo=" + snNo);
return snNo;
}
return 0;
随着数据里逐渐增大,这个速度变得非常慢需要10秒。
(对于一些功能 一些方法添加时间监控非常的有必要)
后来考虑其实流水号和业务无关,既然sql查询无法优化,考虑加一个表存贮即可
SnMax snMaxEntity = snMaxRepository.findByIdAndIsDeleted(CommonConstants.SnMaxId,0); long maxSn = 0; if(null == snMaxEntity){ maxSn =100888880; }else{ maxSn = snMaxEntity.getSnNo(); } public static long getMaxSn(long maxSnNo, int count){ return maxSnNo+count; } public static List<String> genarateSN(String marketCode,SerialNumberRule rule, String gtin,long maxSnNo, int count) {} if(snMaxEntity != null){ snMaxEntity.setSnNo(SerialNumberBuilder.getMaxSn(maxSn,newGenCount)); snMaxRepository.save(snMaxEntity); }else{ SnMax entity =new SnMax(); entity.setId(CommonConstants.SnMaxId); entity.setSnNo(SerialNumberBuilder.getMaxSn(maxSn,newGenCount)); entity.setIsDeleted(0); snMaxRepository.save(entity); }
BUG 序列码申请100只拿到70
这个问题的发生是由于代码执行顺序,当有多个用户共同操作的时候引发的
有一个码池的概念,码池里存了50码。当用户A申请了100个,发现码池有50个,
然后工具生成50个,从码池拿50,顺序是先自己生成,然后从码池拿,
结果当去码池拿的时候,里面已经没有50个,被其他用户拿走了30,所以最后生成了70
真正的思路应该是:先从码池拿,根据实际拿的数量,然后再生成差的。最后数量就不会错
BUG 字符串转 ZonedDateTime 问题,因为时区的问题
注意从第三方拿到的是字符串"2019/6/29 0:00:00" 存出入库后没有细看存储的Date类型的值
public static ZonedDateTime parse(String strDate, String pattern) { SimpleDateFormat df = new SimpleDateFormat(pattern); try { final ZoneId systemDefault = ZoneId.of("Asia/Shanghai"); return ZonedDateTime.ofInstant(df.parse(strDate).toInstant(), systemDefault); } catch (ParseException e) { e.printStackTrace(); return null; } }
实体带状态的,展示的时候重新设置值,用枚举
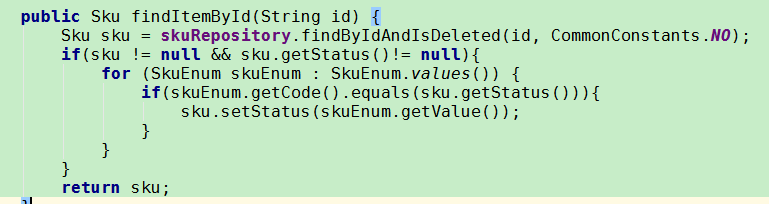
注意:
改完bug一定要本地测试通过,再发到测试环境。而不要凭感觉,觉得这里改一下就Ok l
mongodb 列表查询按照时间倒叙发现很慢,我之前加过索引。
在mongodb数据库里查询,发现也要十几秒,说明代码没有问题,
使用explain 查看执行情况
db.getCollection('serialNumber').find({}).sort({"createdDate":-1}).skip(10).limit(10).explain("executionStats")
发现没有命中索引,命中索引 是

删除之后,重新创建索引为 -1 ok,查询很快了
bug 发现问题 如果没有parentSn 可能会get到空字符串,然后查询出太多的数据,GC了


pallet carton tray 三级,有pasn关系。
传入carton的sn值,根据carton的pasn,
先更新pasn的数据,然后根据pasn,查询出所有的carton
最后更新tary
应该加一个判断,如果carton的pasn是空的,那么就会有问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号