
MySQL 8.0 索引特性2-索引跳跃扫描
MySQL 8.0 实现了Index skip scan,翻译过来就是索引跳跃扫描。熟悉ORACLE的朋友是不是发现越来越像ORACLE了?再者,熟悉 MySQL 5.7 的朋友是不是觉得这个很类似当时优化器的选项MRR?好了,先具体说下什么 ISS,我后面全部用 ISS 简称。
*考虑以下的场景:
表t1有一个联合索引idx_u1(rank1,rank2), 但是查询的时候却没有rank1这列,只有rank2。
比如,select * from t1 where rank2 = 30.那以前遇到这样的情况,如果没有针对rank2这列单独建立普通索引,这条SQL怎么着都是走的FULL TABLE SCAN。ISS就是在这样的场景下产生的。ISS 可以在查询过滤组合索引不包括最左列的情况下,走索引扫描,而不必要单独建立额外的索引。因为毕竟额外的索引对写开销很大,能省则省。
还是那刚才的例子来讲,假设:
表t1的两个字段rank1,rank2。
有这样的记录,
rank1, rank2 1 100 1 200 1 300 1 400 1 500 1 600 1 700 5 100 5 200 5 300 5 400 5 500
我们给出的SQL是,
select * from t1 where rank2 >400;
那MySQL通过ISS把这条SQL变为,
select * from t1 where rank1=1 and rank2 > 400 union all select * from t1 where rank1 = 5 and rank2 > 400;
可以看出来,MySQL其实内部自己把左边的列做了一次DISTINCT,完了加进去。
我们拿实际的例子来看下,假设:
还是刚才描述那张表,rank1字段值的distinct值比较少,查询计划的对比,
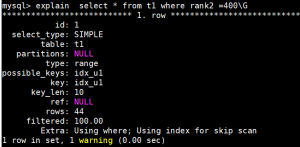
关闭Iss,
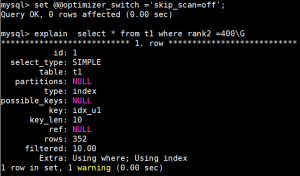
很显然,ISS 扫描的行数要比之前的少很多。
ISS其实恰好适合在这种左边字段的唯一值较少的情况下,效率来的高。比如性别,状态等等。
那假设,rank1字段的distinct值比较多呢?
我们重新造了点数据,这次,rank1的唯一值个数有快上万个

我们来再次看一遍这样SQL的执行计划,
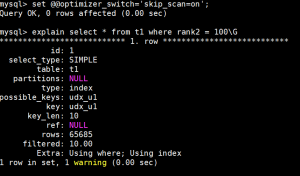
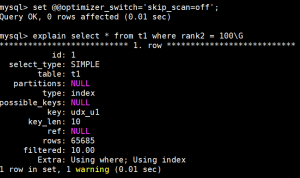
这次我们发现,无论如何MySQL也不会选择ISS,而选了FULL INDEX SCAN。那这样的场景就必须给rank2加一个单独索引了
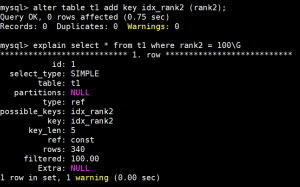
那来总结下ISS就是一句话:ISS 其实就是 MySQL 8.0 推出的适合联合索引左边列唯一值较少的情况的一种优化策略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号