Quartz 任务调度框架
tip:常见的例子就是,比如在购物网站买东西,已经提交订单,但是还未付款的时候,我们就能看到该订单的付款倒计时30分钟,如果超过30分钟未付款,此订单就会在动取消。
这个功能的实现方式就是在下单的时候,后台系统会插入一个待支付的task(job),设定30min之后执行这个job,执行的时候会判定该笔订单是否已经支付,如果未支付则取消此订单。
再例如火车票或优惠卷这种有时限的票卷之类的,用户获取票卷的时候后台也会插入一个到期时间执行的task(job), 到了到期时间后,此票卷就会更改为失效状态,无法使用。
学习quartz框架首先要了解java中的Timer定时类,
Java中的Timer
Timer是一种定时器工具或者称为调度器,用来在一个后台线程计划执行指定任务,可以设定执行一次或多次。该类在java.util包下
//1.创建定时任务
TimerTask job = new TimerTask() {
@Override
public void run() {
System.out.println(new Date());//打印当前时间
}
};
//2.创建定时器
Timer timer = new Timer();
//3.执行定时器
timer.schedule(job,1000,1000);//延迟一秒后,每隔一秒执行一次
我们可以看到schedule方法有4个重载:

- 设定time时间点执行任务
- 设定延时delay毫秒后执行任务
- 设定延时delay毫秒后,每隔period毫秒执行一次任务(重复)
- 设定firstTime时间点开始,每隔period毫秒执行一次任务(重复)
首先我们看一下TaskQueue类,根据名字可看出该类使用队列的方式进行操作任务列表
class TaskQueue {
...
//该类中定义了如下数组,用来保存我们要执行的任务,初始容量是128
private TimerTask[] queue = new TimerTask[128];
void add(TimerTask task) {
//加入任务的时候不够会自动两倍扩容
if (size + 1 == queue.length)
queue = Arrays.copyOf(queue, 2*queue.length);
//加入任务到队尾
queue[++size] = task;
//根据执行时间调整队列中的元素,始终保持最先执行的任务在队首
fixUp(size);
}
...
}
接下来我们看一下TimerThread类,该类会新开一条子线程,该类包含了TaskQueue队列
class TimerThread{
private TaskQueue queue;
TimerThread(TaskQueue queue) {
this.queue = queue;
}
......
//主要逻辑如下
private void mainLoop() {
while (true) {
try {
synchronized(queue) {
//1.等待任务入队通知
while (queue.isEmpty() && newTasksMayBeScheduled)
queue.wait();
.......
//2.获取队列中最先要执行的任务
task = queue.getMin();
synchronized(task.lock) {
......
if (taskFired = (executionTime<=currentTime)) {
//如果任务执行时间到了
if (task.period == 0) {
//如果是只执行一次,则从队列中移除任务,并设置任务状态为已执行
queue.removeMin();
task.state = TimerTask.EXECUTED;
} else {
//重复执行的任务则调整任务下次执行时间
//并把该任务调整到队列中的合适位置
queue.rescheduleMin(
task.period<0 ? currentTime - task.period
: executionTime + task.period);
}
}
}
......
}
//执行任务
//重点:注意此时调用的是run方法,而不是线程的start方法,表示任务执行并没有使用多线程方式
if (taskFired)
task.run();
}
......
}
}
}
最后在看一下最主要的 Timer 类
public class Timer {
//任务队列
private final TaskQueue queue = new TaskQueue();
//任务执行线程类
private final TimerThread thread = new TimerThread(queue);
public Timer(String name) {
thread.setName(name);
thread.start();
}
....
//添加任务,我们依此方法举例。四个重载方法调用的均为sched
public void schedule(TimerTask task, Date firstTime, long period) {
if (period <= 0)
throw new IllegalArgumentException("Non-positive period.");
sched(task, firstTime.getTime(), -period);
}
//重要,添加任务到定时器
private void sched(TimerTask task, long time, long period) {
......
if (Math.abs(period) > (Long.MAX_VALUE >> 1))
period >>= 1;//每次执行间隔超出long最大值的一半,period/2 防止溢出
synchronized(queue) {
......
synchronized(task.lock) {
//设置任务时间和状态
task.nextExecutionTime = time;
task.period = period;
task.state = TimerTask.SCHEDULED;
}
//任务加入队列
queue.add(task);
if (queue.getMin() == task)//如果此任务是最近需要执行的任务
queue.notify();//通知thread继续执行
}
}
}
可以看到,整个Timer底层是新开了一条子线程进行while(true)循环,循环内部处理queueTask任务队列,但是:取出queueTask中的任务进行执行时并没有开辟线程,还是在此子线程上进行的,这就导致会漏掉任务。
例如:间隔2秒执行一次任务,我们预期2、4、6、8...秒执行任务 ,如果每次执行任务耗时小于2秒,则按照我们预期时间执行,如果耗时3秒的话,则任务执行时间会变成3、6、9、12秒执行,如果任务耗时不固定的话,则我们无法预期任务的每次间隔执行时间。
同一个Timer下添加多个TimerTask,如果其中一个没有捕获抛出的异常,则全部任务都会终止运行。但是多个Timer是互不影响
Timer中还提供了两个重载方法

也会出现相同的问题,这两个方法如果任务执行时间超过了预期时间会立即再次执行任务,导致任务更加紊乱。
schedule()运行时,理论时间间隔总是等于实际时间间隔,此时间间隔为max(任务时间,设定时间间隔)
scheduleAtFixedRate()运行时,理论时间间隔总是等于设定的时间间隔,实际时间间隔总是等于max(任务时间,间隔时间)。
scheduleAtFixedRate会尽量减少漏掉调度的情况,如果前一次执行时间过长,导致一个或几个任务漏掉了,那么会补回来,而schedule过去的不会补,直接加上间隔时间执行下一次任务。
Quartz
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,完全由Java开发,可以用来执行定时任务,类似于java.util.Timer。但是相较于Timer, Quartz增加了很多功能。
Quartz的三个基本组成部分
-
调度器:Scheduler
-
任务:JobDetail(包含Job任务)
-
触发器:Trigger(SimpleTrigger、CronTrigger)
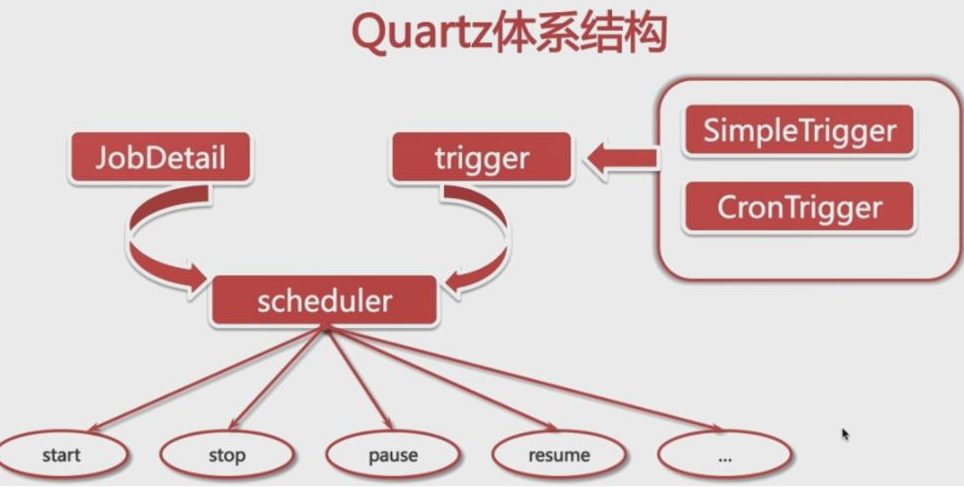
JobDetail和Job
Job
Job是Quartz中的一个接口,接口下只有execute方法,在这个方法中编写业务逻辑。
定义如下:
public interface Job {
void execute(JobExecutionContext var1) throws JobExecutionException;
}
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
//要执行的任务
System.out.println("MyJob 执行" + new Date());
}
}
JobDetail
JobDetail用来绑定Job,它为Job提供了多个属性
- name
- group
- ...
为什么要多定义一个JobDetail,而不是直接使用Job
JobDetail定义的是任务数据,而真正的执行逻辑是在Job中。
这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,Sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
//job1 任务名称 job_group1组名
.withIdentity("job1", "job_group1")
.build();
JobExecutionContext
JobExecutionContext中包含了Quartz运行时的环境和Job本身的详细数据信息。当Schedule调度执行一个Job的时候,就会将JobExecutionContext传递给该Job的execute()中,Job就可以通过JobExecutionContext对象获取信息。
所有的任务运行时信息都可以从JobExecutionContext中获取到:
JobDataMap
JobDataMap实现了JDK的Map接口,可以以Key-Value的形式存储数据。
JobDetail、Trigger都可以使用JobDataMap来设置一些参数或信息,
Job执行execute()方法的时候,JobExecutionContext可以获取到JobDataMap中的信息
//设置JobDataMap数据
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("key","myDataMap");
JobBuilder.newJob(MyJob.class)
//使用usingJobData直接设置数据
.usingJobData("key2","jobDetailValue")
//直接设置JobDataMap对象,不会清空key2-value2,相当于新增
.usingJobData(jobDataMap)
//直接设置JobDataMap对象,会清空key2-value2,相当于重置
.setJobData(jobDataMap)
.build();
//*************************************************************************************
//Trigger中设置JobDataMap数据
TriggerBuilder.newTrigger()
//使用usingJobData直接设置数据
.usingJobData("key3", "triggerValue")
//直接设置JobDataMap对象,不会清空key2-value2,相当于新增
.usingJobData(jobDataMap)
.build();
获取JobDataMap的方式有两种
第一种直接JobExecutionContext上下文分别获取JobDataMap对象或者合并获取。
//获取JobDetail任务中的JobDataMap
JobDataMap jobDataMap = jobExecutionContext.getJobDetail().getJobDataMap();
//获取Trigger触发器中的JobDataMap
JobDataMap triggerDataMap = jobExecutionContext.getTrigger().getJobDataMap();
//合并JobDetail和Trigger中的JobDataMap
//如果有相同的Key,则Trigger中的Value会覆盖JobDetail中的值
JobDataMap mergedJobDataMap = jobExecutionContext.getMergedJobDataMap();
另外一种方式可以获取到JobDataMap中的值,在MyJob中设置属性,属性名和Key相同的话,Quartz框架会自动调用setKey方法填充该属性值,注意这里Trigger中的同名Key同样会覆盖JobDetail中的值。
private String key;
public void setKey(String key) {
this.key = key;
}
Trigger
Trigger是Quartz的触发器,会去通知Scheduler何时去执行对应Job。
SimpleTrigger
SimpleTrigger可以实现在一个指定时间段内执行一次作业任务或一个时间段内多次执行作业任务。
Trigger trigger = TriggerBuilder.newTrigger()
//trigger1 触发器名称 ,trigger_group1触发器组名
.withIdentity("trigger1", "trigger_group1")
.startNow()//立即生效
.startAt(new Date(System.currentTimeMillis() + 1000))//开始时间
.endAt(new Date(System.currentTimeMillis() + 3000))//结束时间
.withSchedule(SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(1)//每一秒执行一次
.repeatForever())//一直重复
.build();
CronTrigger
CronTrigger功能非常强大,是基于日历的作业调度,而SimpleTrigger是精准指定间隔,所以相比SimpleTrigger,CroTrigger更加常用。
cron
CroTrigger是基于Cron表达式的,先了解下Cron表达式:
Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格式:
(1) Seconds Minutes Hours DayofMonth Month DayofWeek Year
(2)Seconds Minutes Hours DayofMonth Month DayofWeek
corn从左到右(用空格隔开):秒 分 小时 月份中的日期 月份 星期中的日期 年份
| 字段 | 允许值 | 允许的特殊字符 |
|---|---|---|
| 秒(Seconds) | 0~59的整数 | , - * / 四个字符 |
| 分(Minutes) | 0~59的整数 | , - * / 四个字符 |
| 小时(Hours) | 0~23的整数 | , - * / 四个字符 |
| 日期(DayofMonth) | 1~31的整数(但是你需要考虑你月的天数) | ,- * ? / L W C 八个字符 |
| 月份(Month) | 1~12的整数或者 JAN-DEC | , - * / 四个字符 |
| 星期(DayofWeek) | 1~7的整数或者 SUN-SAT (1=SUN) | , - * ? / L C # 八个字符 |
| 年(可选,留空)(Year) | 1970~2099 | , - * / 四个字符 |
注意事项:
每一个域都使用数字,但还可以出现如下特殊字符,它们的含义是:
- *****:表示匹配该域的任意值。假如在Minutes域使用*, 即表示每分钟都会触发事件。
- ?:只能用在DayofMonth和DayofWeek两个域。它也匹配域的任意值,但实际不会。因为DayofMonth和DayofWeek会相互影响。例如想在每月的20日触发调度,不管20日到底是星期几,则只能使用如下写法: 13 13 15 20 * ?, 其中最后一位只能用?,而不能使用,如果使用表示不管星期几都会触发,实际上并不是这样。
- -:表示范围。例如在Minutes域使用5-20,表示从5分到20分钟每分钟触发一次
- /:表示起始时间开始触发,然后每隔固定时间触发一次。例如在Minutes域使用5/20,则意味着5分钟触发一次,而25,45等分别触发一次.
- ,:表示列出枚举值。例如:在Minutes域使用5,20,则意味着在5和20分每分钟触发一次。
- L:表示最后,只能出现在DayofWeek和DayofMonth域。如果在DayofWeek域使用5L,意味着在最后的一个星期四触发。
- W:表示有效工作日(周一到周五),只能出现在DayofMonth域,系统将在离指定日期的最近的有效工作日触发事件。例如:在 DayofMonth使用5W,如果5日是星期六,则将在最近的工作日:星期五,即4日触发。如果5日是星期天,则在6日(周一)触发;如果5日在星期一到星期五中的一天,则就在5日触发。另外一点,W的最近寻找不会跨过月份 。
- LW:这两个字符可以连用,表示在某个月最后一个工作日,即最后一个星期五。
(#**:用于确定每个月第几个星期几,只能出现在DayofMonth域。例如在4#2,表示某月的第二个星期三。
常用表达式例子
(1)0 0 2 1 * ? * 表示在每月的1日的凌晨2点调整任务
(2)0 15 10 ? * MON-FRI 表示周一到周五每天上午10:15执行作业
(3)0 15 10 ? 6L 2002-2006 表示2002-2006年的每个月的最后一个星期五上午10:15执行作
(4)0 0 10,14,16 * * ? 每天上午10点,下午2点,4点
(5)0 0/30 9-17 * * ? 朝九晚五工作时间内每半小时
(6)0 0 12 ? * WED 表示每个星期三中午12点
(7)0 0 12 * * ? 每天中午12点触发
(8)0 15 10 ? * * 每天上午10:15触发
(9)0 15 10 * * ? 每天上午10:15触发
(10)0 15 10 * * ? * 每天上午10:15触发
(11)0 15 10 * * ? 2005 2005年的每天上午10:15触发
(12)0 * 14 * * ? 在每天下午2点到下午2:59期间的每1分钟触发
(13)0 0/5 14 * * ? 在每天下午2点到下午2:55期间的每5分钟触发
(14)0 0/5 14,18 * * ? 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
(15)0 0-5 14 * * ? 在每天下午2点到下午2:05期间的每1分钟触发
(16)0 10,44 14 ? 3 WED 每年三月的星期三的下午2:10和2:44触发
(17)0 15 10 ? * MON-FRI 周一至周五的上午10:15触发
(18)0 15 10 15 * ? 每月15日上午10:15触发
(19)0 15 10 L * ? 每月最后一日的上午10:15触发
(20)0 15 10 ? * 6L 每月的最后一个星期五上午10:15触发
(21)0 15 10 ? * 6L 2002-2005 2002年至2005年的每月的最后一个星期五上午10:15触发
(22)0 15 10 ? * 6#3 每月的第三个星期五上午10:15触发
在线Cron表达式生成器 - 码工具 (matools.com)https://www.matools.com/cron
新建一个每周一凌晨1点的触发器
CronTrigger cronTrigger = TriggerBuilder.newTrigger()
//trigger1 触发器名称 ,trigger_group1触发器组名
.withIdentity("trigger1", "trigger_group1")
.startNow()//立即生效
//每周一凌晨1点执行任务
.withSchedule(CronScheduleBuilder.cronSchedule("0 0 1 ? * MON"))
.build();
并发
Quartz默认是并发执行任务的,每次执行任务都会新开一个线程并新建一个JobDetail对象执行任务
@DisallowConcurrentExecution
如果我们不需要并发执行任务则可以使用@DisallowConcurrentExecution注解,关闭并发执行
@PersistJobDataAfterExecution
如果我们不需要新建Job执行任务的话,可以使用@PersistJobDataAfterExecution注解,让我们使用同一个Job对象去执行任务
@DisallowConcurrentExecution
@PersistJobDataAfterExecution
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
//要执行的任务
}
}
持久化
Quartz保存工作数据默认是使用内存的方式,上面的简单例子启动时可以在控制台日志中看到JobStore是RAMJobStore使用内存的模式,然后是not clustered表示不是集群中的节点

1)持久化需要配置JDBCJobStore方式,首先去下载Sql脚本,新建QuartzDb数据库,执行脚本,2.1.7以上版本的脚本没找到,这里直接用的2.1.7的脚本。如使用版本在2.2.0之上,需要在qrtz_fired_triggers表中新增SCHED_TIME字段。
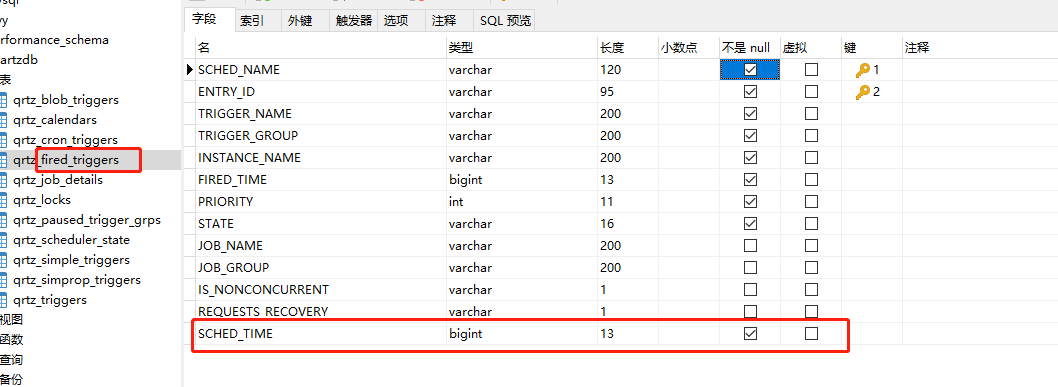
2)配置Quartz数据源和持久化方式,新增quartz.properties配置文件
org.quartz.scheduler.instanceName = MyScheduler
#开启集群,多个Quartz实例使用同一组数据库表
org.quartz.jobStore.isClustered = true
#分布式节点ID自动生成
org.quartz.scheduler.instanceId = AUTO
#分布式节点有效性检查时间间隔,单位:毫秒
org.quartz.jobStore.clusterCheckinInterval = 10000
#配置线程池线程数量,默认10个
org.quartz.threadPool.threadCount = 10
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#使用QRTZ_前缀
org.quartz.jobStore.tablePrefix = qrtz_
#dataSource名称
org.quartz.jobStore.dataSource = myDS
#dataSource具体参数配置
org.quartz.dataSource.myDS.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL = jdbc:mysql://localhost:3306/quartzdb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
org.quartz.dataSource.myDS.user = root
org.quartz.dataSource.myDS.password = 12345678
org.quartz.dataSource.myDS.maxConnections = 5
3)默认使用C3P0连接池,添加依赖 Quartz 2.0 以后 都更新为C3P0(包含2.0),Quartz 2.0 以前使用DBCP
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>
修改自定义连接池则需要实现org.quartz.utils.ConnectionProvider接口quartz.properties添加配置
org.quartz.dataSource.myDS(数据源名).connectionProvider.class=XXX(自定义ConnectionProvider全限定名)
启动以后就可以看到,使用了JobStoreTX来持久化定时任务到数据库中,每次运行程序时会自动去数据库中取任务,新增任务也会自动持久化到数据库。

Spring中集成Quartz
SpringBoot中内置的定时任务
要使用Springboot中内置的定时任务,需要在启动方法时使用@EnableScheduling注解
@SpringBootApplication
@EnableScheduling //开启定时任务
public class MyApplicationBoot {
public static void main(String[] args) {
SpringApplication.run(MyApplicationBoot.class, args);
}
}
@Component
class SchedulingTask {
private static final SimpleDateFormat dateFormat = new SimpleDateFormat("HH:mm:ss");
private int count = 0;
/**
* 定时任务:延迟5秒后启动,每隔2秒执行一次
*/
@Scheduled(initialDelay = 5000, fixedRate = 2000)
private void process() {
System.out.println(Thread.currentThread().getName() + "普通定时任务" + (count++) + " => " + dateFormat.format(new Date()));
}
/**
* 定时任务Cron:每隔2秒执行一次
*/
@Scheduled(cron = "*/2 * * * * ?")
private void cronProcess() {
System.out.println(Thread.currentThread().getName() + "Cron定时任务" + (count++) + " => " + dateFormat.format(new Date()));
}
}
Spring中内置的定时任务的底层也是基于Timer类实现的,所以特征和java.util.Timer基本一致。
单独的TimerThread线程,每个对象在整个生命周期中只会实例化一个。
SrpingBoot整合Quartz
1)引入依赖
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.3</version>
</dependency>
2)添加配置类 application.yml和spring-quartz.properties
spring-quartz.properties文件
#JobDataMaps是否都是String类型,默认false
org.quartz.jobStore.useProperties=false
#线程池==========================================
#配置线程池线程数量,默认10个 1-100
org.quartz.threadPool.threadCount = 10
#线程池实现类
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
#优先级 1-10
org.quartz.threadPool.threadPriority = 5
#持久化==========================================
#数据库中各表的前缀
org.quartz.jobStore.tablePrefix = qrtz_
#jdbc托管事务
org.quartz.jobStore.txIsolationLevelReadCommitted = true
#持久化方式使用jdbc
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
#数据库代理
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#集群配置=========================================
#开启集群,多个Quartz实例使用同一组数据库表
org.quartz.jobStore.isClustered = true
#集群的实力名字,同一个集群名字必须相同
org.quartz.scheduler.instanceName = MyScheduler
#分布式节点ID自动生成
org.quartz.scheduler.instanceId = AUTO
#分布式节点有效性检查时间间隔,单位:毫秒
org.quartz.jobStore.clusterCheckinInterval = 10000
application.yml文件
server:
port: 9096
spring:
#配置数据源
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/quartzdb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: 12345678
3)构建Job,继承QuartzJobBean并重写executeInternal,与之前实现Job接口类似。
public class MyJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
try {
Thread.sleep(2000);
System.out.printf("调试器:【%s】任务名称:【%s】 执行时间:【%s】\n",
context.getScheduler().getSchedulerName(),
context.getJobDetail().getKey().getName(),
sdf.format(new Date()));
} catch (Exception e) {
e.printStackTrace();
}
}
}
4) 配置QuartzConfig
@Configuration
public class QuartzConfig {
/**
* 获取容器中的数据源
*/
@Autowired
private DataSource dataSource;
/**
* 调度器
*/
@Bean
public Scheduler scheduler() throws IOException {
return schedulerFactoryBean().getScheduler();
}
/**
* 调度器生成工厂
*/
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setSchedulerName("cluster_scheduler");
factory.setApplicationContextSchedulerContextKey("application_key");
factory.setDataSource(dataSource);//设置数据源
factory.setQuartzProperties(quartzProperties());//获取quartz配置
factory.setTaskExecutor(schedulerThreadPool());//设置线程池
factory.setStartupDelay(5);//5s延迟执行
return factory;
}
/**
* 获取线程池
*/
@Bean
public ThreadPoolTaskExecutor schedulerThreadPool(){
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(Runtime.getRuntime().availableProcessors());
threadPoolTaskExecutor.setMaxPoolSize(Runtime.getRuntime().availableProcessors());
threadPoolTaskExecutor.setQueueCapacity(Runtime.getRuntime().availableProcessors());
return threadPoolTaskExecutor;
}
/**
* 获取quartz的配置文件
*/
@Bean
public Properties quartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/spring-quartz.properties"));
propertiesFactoryBean.afterPropertiesSet();
return propertiesFactoryBean.getObject();
}
}
5)启动应用时启用quartz
@Component
public class StartApplicationListenter implements ApplicationListener<ContextRefreshedEvent> {
@Autowired
private Scheduler scheduler;
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
try {
TriggerKey triggerKey = TriggerKey.triggerKey("trigger1", "triggerGroup1");
Trigger trigger = scheduler.getTrigger(triggerKey);
if (trigger == null) {
trigger = TriggerBuilder.newTrigger()
.withIdentity(triggerKey)
.withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?"))
.build();
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job1", "jobGroup1")
.build();
scheduler.scheduleJob(jobDetail, trigger);
}
TriggerKey triggerKey1 = TriggerKey.triggerKey("trigger2", "triggerGroup1");
Trigger trigger1 = scheduler.getTrigger(triggerKey1);
if (trigger1 == null) {
trigger1 = TriggerBuilder.newTrigger()
.withIdentity(triggerKey1)
.withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?"))
.startNow()
.build();
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job2", "jobGroup1")
.build();
scheduler.scheduleJob(jobDetail, trigger1);
}
scheduler.start();
} catch (Exception e) {
e.printStackTrace();
}
}
}
因为之前我们开启了Quartz中的集群管理,在我们启动多个SpringBoot后,多个Trigger触发器会分散在每个SpringBoot应用中启用。这样就能防止我们在多个应用中重复执行同一个任务。
应用停止后,各个任务状态会保存到数据库中,以便下次应用启动后继续执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号