Os的栈管理
一、关于单堆栈模型
RTA-OS使用单栈模型(每个核一个堆栈),即所有的Task、ISRS在同一个堆栈区域上运行。单堆栈模型显著简化了链接时的堆栈空间分配,因为用户只需为整个系统堆栈分配单个内存部分,就像根本不使用操作系统一样。
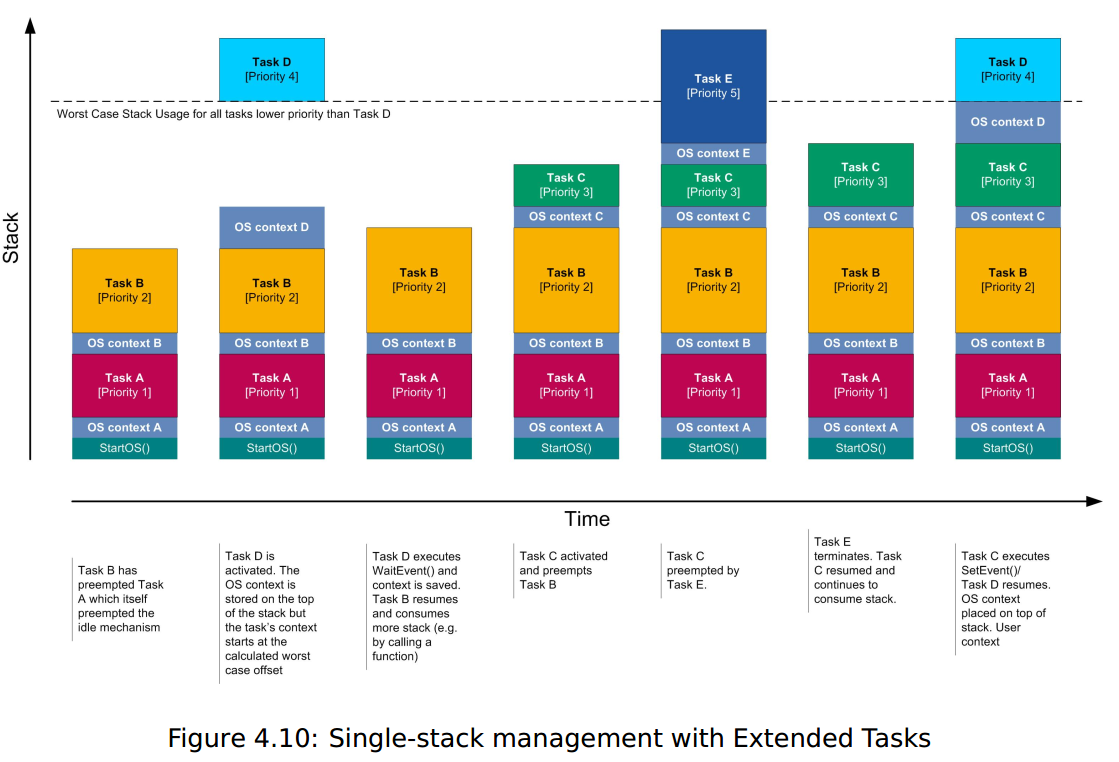
当任务运行时,其堆栈使用量会像正常情况一样增减。当任务被抢占时,高优先级任务的堆栈使用将在同一堆栈上继续(就像标准函数调用一样)。当任务终止时,它使用的堆栈空间将被回收,然后重新用于下一个优先级最高的任务运行(同样,与标准函数调用一样)。下图显示了单堆栈在声明、抢占和终止任务时的行为。
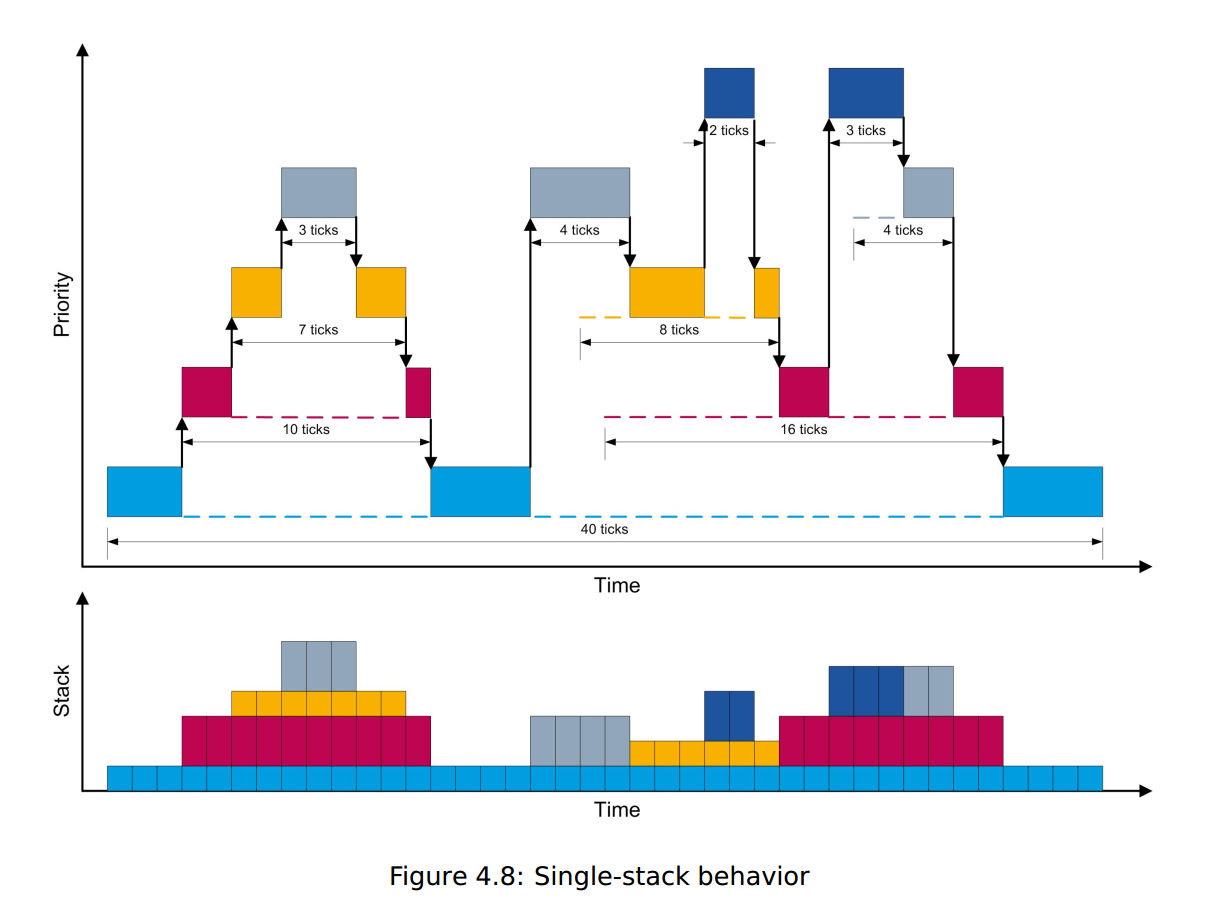
在单堆栈模型中,堆栈大小与系统中优先级的数量成比例,而不是与任务/ISR的数量成比例。这意味着,直接或通过共享内部资源,或通过被配置为非先发制人,共享优先级的任务永远不会同时出现在堆栈上。在硬件上共享优先级的ISR也是如此。这意味着用户可以通过简单的配置更改来交换系统响应性,即任务或ISR完成所需的时间,以换取堆栈空间。
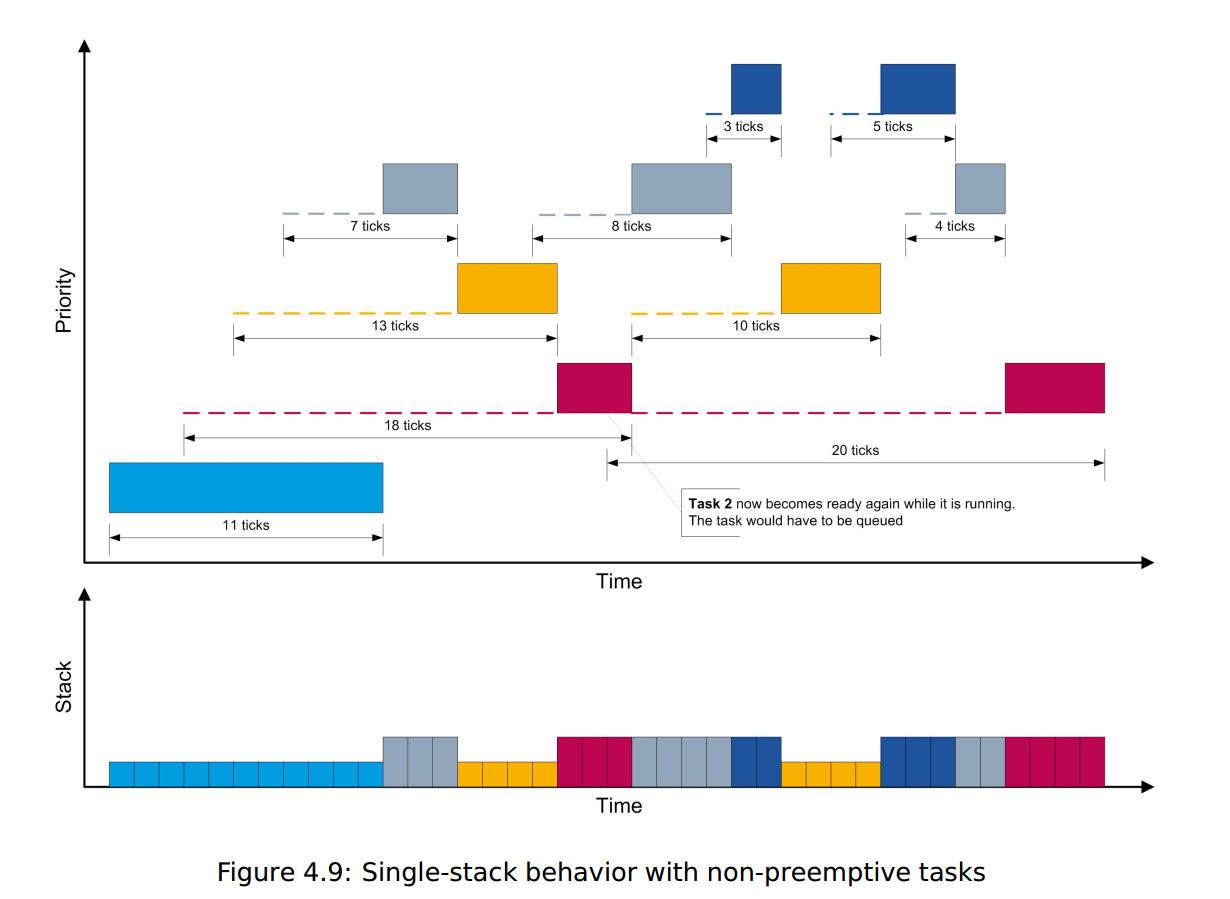
上图显示了同一任务集的执行情况,具有与上上图相同的到达模式,但这次任务是非抢占式调度的。可以看到,高优先级任务的响应时间比抢占式调度时长得多,但总体堆栈消耗要低得多。
二、指定Task的堆栈分配
在仅包含基本任务的系统中,除非用户正在进行堆栈监控,否则无需告知RTA-OS任何堆栈分配。只需在链接器/定位器中为应用程序分配足够大的堆栈部分。这是单堆栈体系结构的优点之一。
下图展示了如何指定分配某个task的分配:
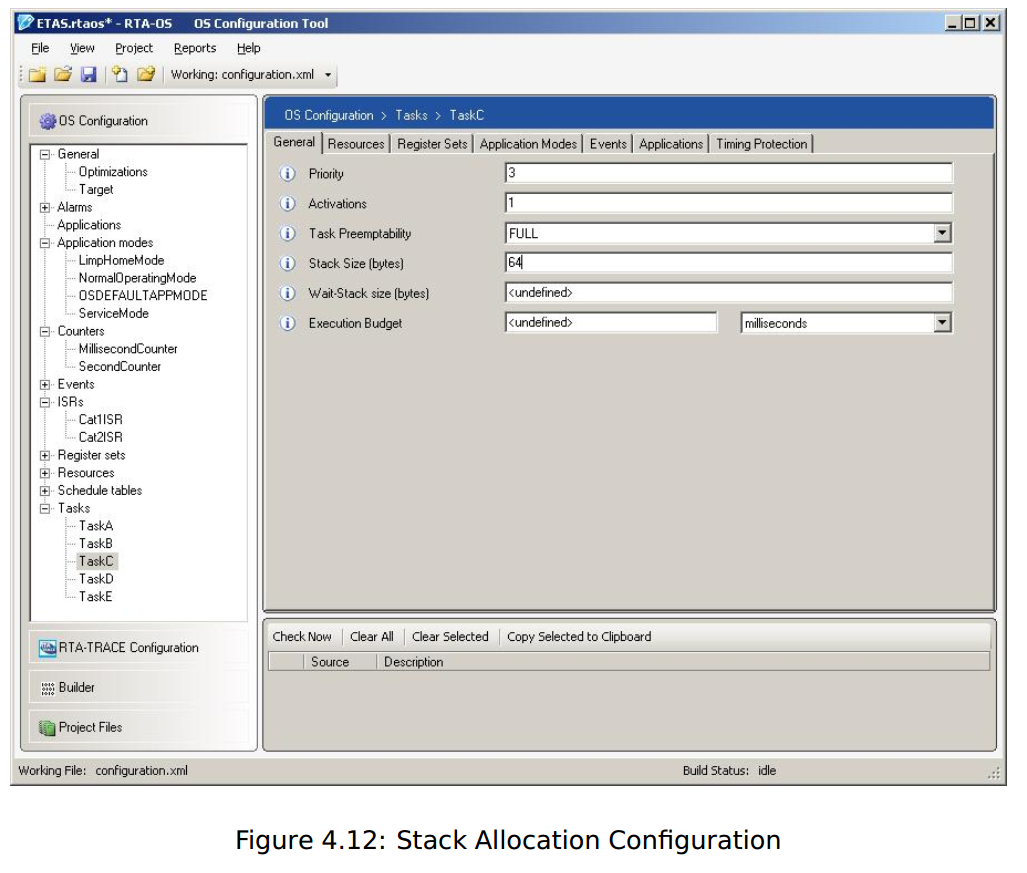
对于使用扩展任务的应用程序,用户可以像以前一样分配Linker部分,但用户还必须为RTA-OS中每个优先级低于最高优先级扩展任务的任务分配堆栈,即使它们是基本任务。RTA-OS使用堆栈分配信息为每个离线扩展任务计算最坏情况下的抢占点。
虽然RTA-OS使用单堆栈模型,但在某些端口上,这并不一定意味着只使用一个物理堆栈。可能是编译器或硬件自动将数据强制到不同的堆栈上。例如,TriCore设备使用CSA内存快速保存调用context。
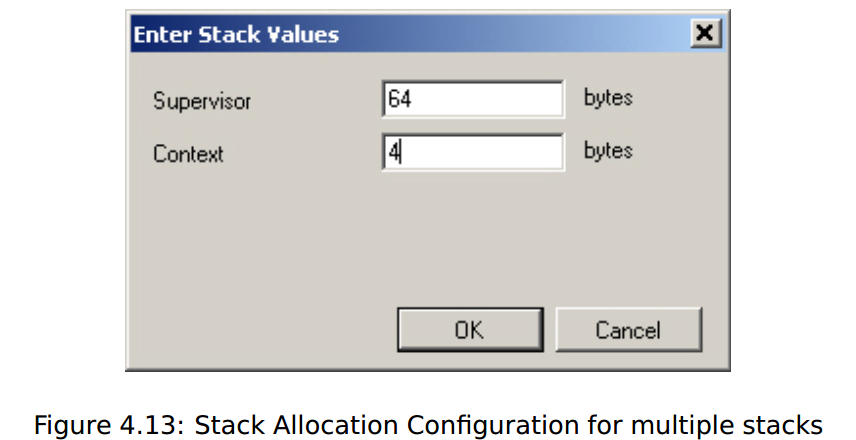
即使有多个物理堆栈,RTA-OS仍然提供了单堆栈体系结构的好处——当任务和/或ISR共享优先级时,每个物理堆栈上所需的堆栈空间可以重叠。但是,要使堆栈分配正常工作,需要指定每个堆栈上所需的空间。如果用户配置,RTA-OS将要求用户提供多个堆栈值。
三、扩展任务的堆栈管理
RTA-OS独特地扩展了单堆栈模型,在不影响基本任务性能的情况下为扩展任务提供支持。扩展任务管理要求RTA-OS知道任务和ISR使用了多少堆栈。是否是拓展任务只和是否有挂起状态(event)相关,和抢占属性、CanCallSchedule无关。
在RTA-OS中,扩展任务的生命周期如下:
- Suspended→Ready:任务被添加到Ready 序列
- Ready→Running:任务已调度,但与内容位于堆栈顶部的基本任务不同,内容位于堆栈空间中,所有低优先级任务的预先计算的最坏情况抢占深度处。
- Running→Ready:扩展任务被抢占。如果抢占任务是一个基本任务,那么它会像往常一样在堆栈顶部调度;如果抢占任务是一个扩展任务,那么它将按照预先计算的所有低优先级任务的最坏情况抢占深度进行调度。
- Running→Waiting:任务的等待事件堆栈内容(包括操作系统上下文、本地数据、函数调用的堆栈帧等)保存到内部操作系统缓冲区中
- Waiting→Ready:任务添加到Ready 队列
- Running→Suspended:任务的“等待事件堆栈”内容将从内部操作系统缓冲区复制回堆栈中所有低优先级任务预先计算的最坏情况抢占深度。
四、强制堆栈信息
计算出的最坏情况分派点定义了需要启动扩展任务的字节数,该字节数与调用StartOS()时堆栈指针的地址有关。这些偏移量作为ROM数据存储在扩展任务控制块中,并在运行时添加到堆栈的基址。
此处笔者在代码中找到了此处的“偏移量”
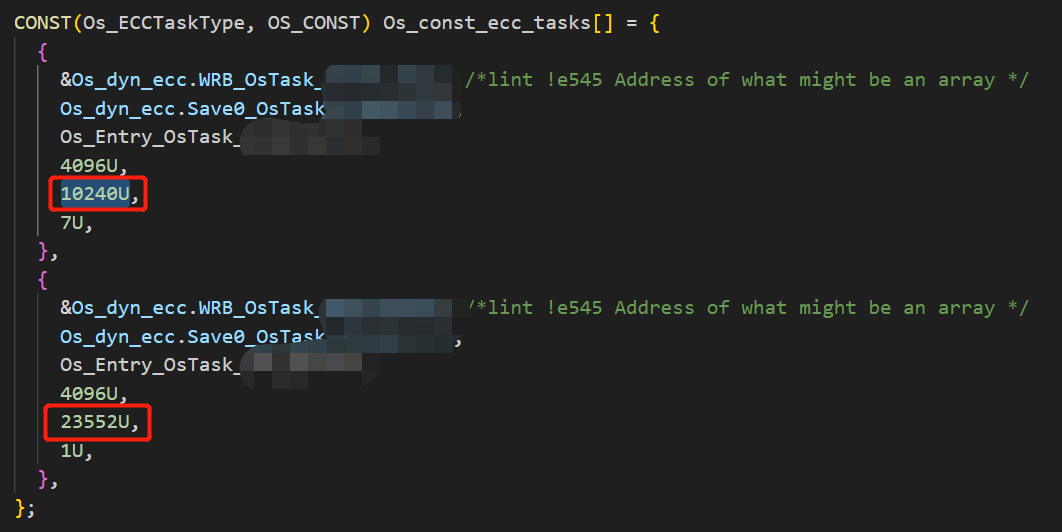
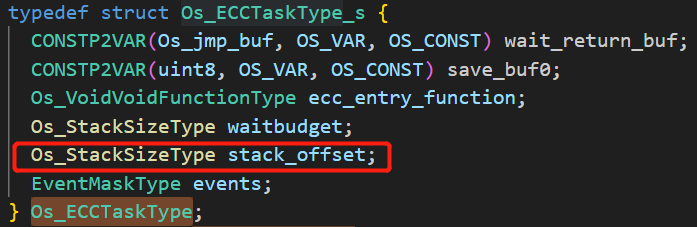
此处的stack_offset是根据stack allocation information计算出来的,通过实验,发现了以下规律:
前提是:直有Ecc任务+不可抢占的Bcc任务
- offset只与'比此ECC任务优先级低的任务'的优先级的总数量相关
- 只与此ECC任务所在核的低优先级任务有关,其他核任务不相干
- 低于此ECC任务的任务优先级顺序无关、绝对值无关
- 与核的数量无关
- OsRTATarget->SpECC++SpStartOS+SpIDisp+SpPreemption四个属性可以指定基础的stack_offset,之后系统任务每多一个优先级增加5K+其StackAllocation属性值,因此如果计算出的此偏移超过芯片堆栈大小就会直接跑飞,且不会触发下文的overrun错误
- 某些属性可以被指定以只使用5中提到的基础的stack_offset,非抢占系统会减小5k的数值
五、处理堆栈溢出
如果用户提供给RTA-OS的堆栈分配太小(运行时错误的潜在来源),有三种错误情况可能发生:
- 当RTA-OS尝试调度扩展任务时,堆栈指针的当前值高于计算的最坏情况调度点,因此扩展任务无法启动。这意味着堆栈上的一个(或多个)低优先级任务占用了太多空间。
- 扩展任务无法从等待状态恢复,因为堆栈指针高于它应该的值。当为扩展任务正在等待的事件调用SetEvent()并且扩展任务现在是系统中优先级最高的任务时,可能会发生这种情况。
- 扩展任务无法进入等待状态,因为任务正在使用的堆栈的当前数量大于配置的“WaitEvent()堆栈”的大小。
当RTA-OS检测到扩展任务堆栈管理出现问题时,它将调用ShutdownOS(),错误代码为E_OS_STACKFAULT。如果要调试该问题,则可以启用堆栈故障Hook。
配置后,RTA-OS将在堆栈故障发生时调用用户提供的回调OS_Cbk_StackOverflowHook(),而不是ShutdownOS()。回调传递了两个参数:溢出的字节数、溢出的原因。
六、栈监控
见UserGuide第十四章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号