python中的编解码
下面写的都是自我理解的,如有错漏,欢迎指正
本文主要涉及:unicode、utf-8、ascii码、b''、\u、\x 这些经常用的,之间的转换及含义
先来一些概念:
-
unicode、utf-8、ascii是编码类型,由于计算机只识别0和1,所以自然界的问题,在计算机中处理,需要编码成这些类型。
-
ascii码是最开始的,美国人用的包含26个字母及其他的一些符号的,只有1个字节。
-
unicode是包含了其他国家,例如中文,韩文,日文等的一些,通常有2个字节,有些有4个字节。
-
utf-8是本着节约的精神,在unicode的基础上做优化的,兼容ascii码。
1 python2和python3的字符串默认编码
1.1 通过ord获取字符的码号(python3)
1.2 交互模式下的显示中文(python3)
| 直接写字符串 | 使用\u的形式 | 使用u''的形式 | ||
|---|---|---|---|---|
|
>>> '你好'
'你好'
|
>>> u'\u4f60\u597d'
'你好'
|
>>> u'你好'
'你好'
|
>>> u'你好'.encode('utf-8')
b'\xe4\xbd\xa0\xe5\xa5\xbd'
|
1.3 创建一个简单的python文件
分别调用python2和python3进行观察
作者结论:
-
python3默认使用unicode编码字符串,而python2使用的是ascii码
-
我认为文件开头的encoding='utf-8'应该只需要在python2中使用(还没测试)
-
unicode通常为2个字节,有时候为4个字节(不知道是如何区分的呢?)
1.4 如何区分unicode的2字节和4字节字符?(# 没有做测试)
在网上看到的一句,4字节字符的前两个字节范围是d800-dbff,后两个字节范围是dc00-dfff
2 unicode与utf-8与b''
\u表示unicode编码
\x为16进制
b''为python中的byte表示,一般用于网络传输
2.1 三者的转换
三者的关系,可以通过下图观察。
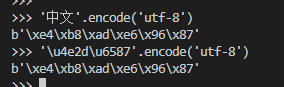
作者结论:
-
encode将字符串编码成了'utf-8'的格式,成了一个个字节,一般我们打开文件(open),可能会指定encoding=utf-8,表示文本是以此编码格式进行存储在硬盘中的。
-
unicode不等同于utf-8
-
可以看到上面的从unicode的四字节,变成了utf-8的六字节,所以也论证了个说法,即在英文多的情况下用utf-8比较节省,中文多的情况下unicode可能才更节省。
3 unicode兼容ascii码的测试
unicode兼容ascii码,所以只需要在前面补'0'就可以打印出对应的值
-
\x为十六进制,后面紧跟一个字节,一个字节8位,2**8=256=16*16,所以后面跟两个16进制字母
-
\u通常为两个字节,所以后面是4个16进制字母
-
b''流用于在网络中传输,都是单个字节的,收端使用相应的编码进行解码。
4 python的显示自动优化
|
>>> '\x61\x62\x63'.encode('utf-8')
b'abc'
|
>>> 'abc'.encode('utf-8')
b'abc'
|
>>> '你好'.encode('utf-8')
b'\xe4\xbd\xa0\xe5\xa5\xbd'
|
理论上来说,使用了encode方法,那应该返回字节码才对,但返回的仍然是原本的'abc',这其实是因为python做了展示的优化,能用ascii码表示的字符,都会如此展示(ps:我个人觉得还不如不展示,容易使人迷惑)。如果是中文的话,就仍会返回\x这种形式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号