
Java面试题汇总---整理版(附答案)
今天继续为大家整理Java面试题,并涉及数据库和网络等相关知识,希望能帮助到各位开发者。
1,为什么要用spring,Spring主要使用了什么模式?
spring能够很好的和各大框架整合,它通过IOC容器管理了对象的创建和销毁 工厂模式。在使用hiberna,mybatis的时候,不用每次都编写提交的事务的代码,可以使用spring的AOP来管理事务。AOP其实就是一个动态代理的实现(声明式事务和编程式事务)。
主要使用了模式:
工厂模式:每个Bean的创建通过方法;
单例模式:默认的每个Bean的作用域都是单例;
代理模式:关于Aop的实现通过代理模式;
2、Mybatis工作原理?
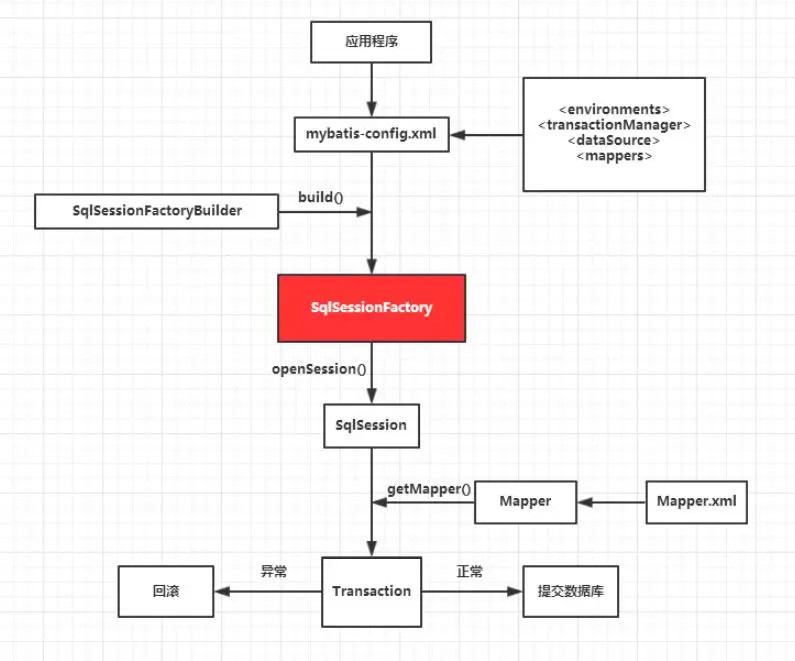
原理:
-
通过SqlSessionFactoryBuilder从mybatis-config.xml配置文件中构建出SqlSessionFactory。
-
SqlSessionFactory开启一个SqlSession,通过SqlSession实例获得Mapper对象并且运行Mapper映射的Sql语句。
-
完成数据库的CRUD操作和事务提交,关闭SqlSession。
3,mybatis的优缺点?
优点:SQL写在XML中,便于统一管理和优化
提供映射标签,支持对象和数据库的orm字段关系映射
可以对SQL进行优化
缺点: SQL工作量大
mybagtis移植姓不好
不支持级联
4,maven是什么?有什么作用?
是一个项目管理、构建工具
作用:帮助下载jar 寻找依赖,帮助下载依赖 热部署、热编译。
5,什么RESTful架构?
1)每一个URI代表一种资源;
2)客户端和服务器之间,传递这种资源的某种表现层;
3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化",
6,说说tcp/ip协议族
TCP/IP协议族是一个四层协议系统,自底而上分别是数据链路层、网络层、传输层和应用层。每一层完成不同的功能,且通过若干协议来实现,上层协议使用下层协议提供的服务。
1)数据链路层负责帧数据的传递。
2)网络层责数据怎样传递过去。
3)传输层负责传输数据的控制(准确性、安全性)
4)应用层负责数据的展示和获取
7,说说tcp三次握手,四次挥手。
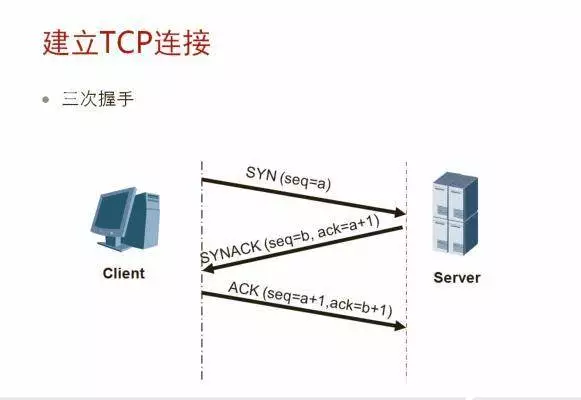
TCP的连接建立是一个三次握手过程,目的是为了通信双方确认开始序号,以便后续通信的有序进行。主要步骤如下:
1)连接开始时,连接建立方发送SYN包,并包含了自己的初始序号a;
2)连接接受方收到SYN包后会回复一个SYN包,其中包含对上一个a包的回应信息ACK,回应的序号为下一个希望收到包的序号,即a+1,然后还包了自己的初始序号b;
3. 连接建立方(Client)收到回应的SYN包以后,回复一个ACK包做响应,其中包含了下一个希望收到包的序号即b+1。
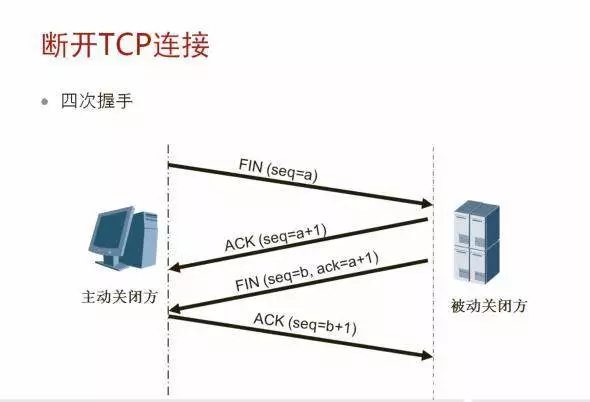
TCP终止连接的四次握手过程如下:
1. 首先进行关闭的一方(即发送第一个FIN)将执行主动关闭,而另一方(收到这个FIN)执行被动关闭。
2. 当服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
3. 同时TCP服务器还向应用程序(即丢弃服务器)传送一个文件结束符。接着这个服务器程序就关闭它的连接,导致它的TCP端发送一个FIN。
4. 客户必须发回一个确认,并将确认序号设置为收到序号加1。
8,GIT和SVN的区别。
主要区别如下:
1)GIT是分布式的,SVN不是。
2)GIT把内容按元数据方式存储,而SVN是按文件。
3)GIT分支和SVN的分支不同。
4)GIT没有一个全局的版本号,而SVN有。
5)GIT的内容完整性要优于SVN。
9,BIO、NIO和AIO的区别
Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java AIO: 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
NIO比BIO的改善之处是把一些无效的连接挡在了启动线程之前,减少了这部分资源的浪费(因为我们都知道每创建一个线程,就要为这个线程分配一定的内存空间)。
AIO比NIO的进一步改善之处是将一些暂时可能无效的请求挡在了启动线程之前,比如在NIO的处理方式中,当一个请求来的话,开启线程进行处理,但这个请求所需要的资源还没有就绪,此时必须等待后端的应用资源,这时线程就被阻塞了。
10,为什么要用线程池?
线程池是指在初始化一个多线程应用程序过程中创建一个线程集合,然后在需要执行新的任务时重用这些线程而不是新建一个线程。
使用线程池的好处:
1、线程池改进了一个应用程序的响应时间。由于线程池中的线程已经准备好且等待被分配任务,应用程序可以直接拿来使用而不用新建一个线程。
2、线程池节省了CLR 为每个短生存周期任务创建一个完整的线程的开销并可以在任务完成后回收资源。
3、线程池根据当前在系统中运行的进程来优化线程时间片。
4、线程池允许我们开启多个任务而不用为每个线程设置属性。
5、线程池允许我们为正在执行的任务的程序参数传递一个包含状态信息的对象引用。
6、线程池可以用来解决处理一个特定请求最大线程数量限制问题。
11,悲观锁和乐观锁的区别,怎么实现?
悲观锁:一段执行逻辑加上悲观锁,不同线程同时执行时,只能有一个线程执行,其他的线程在入口处等待,直到锁被释放。
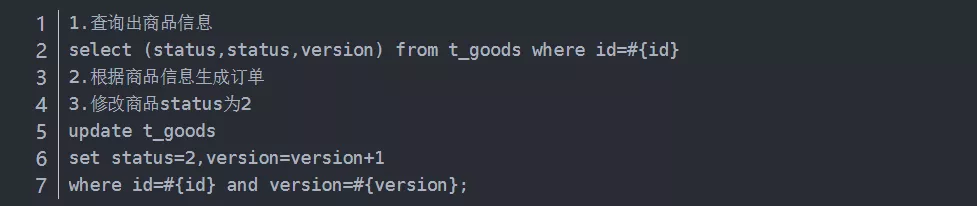
乐观锁:一段执行逻辑加上乐观锁,不同线程同时执行时,可以同时进入执行,在最后更新数据的时候要检查这些数据是否被其他线程修改了(版本和执行初是否相同),没有修改则进行更新,否则放弃本次操作。
悲观锁的实现:
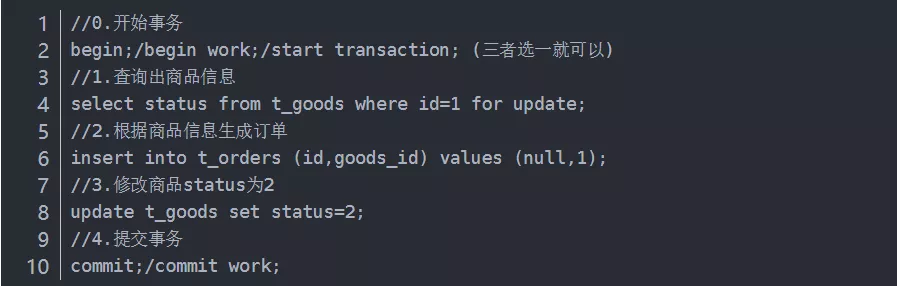
乐观锁的实现:
12,java中的堆和栈分别是什么数据结构,为什么要分为堆和栈来存储数据?
栈是一种具有后进先出性质的数据结构,也就是说后存放的先取,先存放的后取。堆是一种经过排序的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。由于堆的这个特性,常用来实现优先队列,堆的存取是随意的。
为什么要划分堆和栈:
1)从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。
2)堆与栈的分离,使得堆中的内容可以被多个栈共享。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。
3)栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。
4)体现了Java面向对象这一核心特点(也可以继续说一些自己的理解)。
如果你想学习或了解更多,请关注此公众号,在公众号联系或私聊


