HIve总结:
首先要学习Hive,第一步是了解Hive,Hive是基于Hadoop的一个数据仓库,可以将结构化的数据文件映射为一张表,并提供类sql查询功能,Hive底层将sql语句转化为mapreduce任务运行。相对于用java代码编写mapreduce来说,Hive的优势明显:快速开发,人员成本低,可扩展性(自由扩展集群规模),延展性(支持自定义函数)。
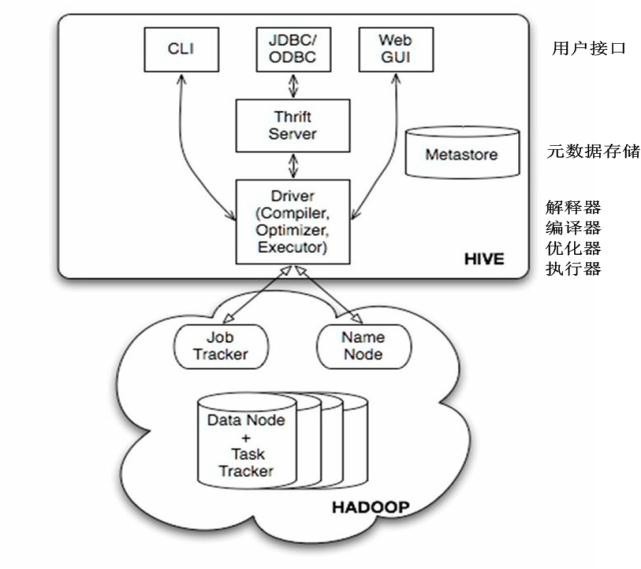
Hive的构架:
Hive提供了三种用户接口:CLI、HWI和客户端。客户端是使用JDBC驱动通过thrift,远程操作Hive。HWI即提供Web界面远程访问Hive。但是最常见的使用方式还是使用CLI方式。(在linux终端操作Hive)
Hive有三种安装方式:
1、内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错,不适合开发环境)
2、本地模式(本地安装mysql 替代derby存储元数据)
3、远程模式(远程安装mysql 替代derby存储元数据)
安装Hive:(本地模式)
首先Hive的安装是在Hadoop集群正常安装的基础上,并且集群启动
安装Hive之前我们要先安装mysql,
查看是否安装过mysql:rpm -qa|grep mysql*
查看有没有安装包:yum list mysql*
安装mysql客户端:yum install -y mysql
安装服务器端:yum install -y mysql-server
yum install -y mysql-devel
启动数据库 service mysqld start或者/etc/init.d/mysqld start
创建hadoop用户并赋予权限:
mysql>grant all on *.* to hadoop@'%' identified by 'hadoop';
mysql>grant all on *.* to hadoop@'localhost' identified by 'hadoop';
mysql>grant all on *.* to hadoop@'master' identified by 'hadoop';
mysql>flush privileges;
解压:tar -zxvf apache-hive-1.2.1-bin.tar.gz
配置:cd /apache-hive-1.2.1-bin/conf/ vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
</configuration>
复制依赖包:cp mysql-connector-java-5.1.43-bin.jar apache-hive-1.2.1-bin/lib/
配置环境变量:
export HIVE_HOME=$PWD/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/bin
启动hive:hive
hive中可以运行shell命令:! shell命令
hive中可以运行hadoop命令:
hive中的数据类型:
原子数据类型:TINYINT SMALLINT INT BIGINT FLOAT DOUBLE BOOLEAN STRING
复杂数据类型:STRUCT MAP ARRAY
hive的使用:
建表语句:
DDL:
创建内部表:
create table mytable(
id int,
name string)
row format delimited fields terminated by '\t' stored as textfile;
常见外部表:关键字 external
create external table mytable2(
id int,
name string)
row format delimited fields terminated by '\t' location '/user/hive/warehouse/mytable2';
创建分区表:分区字段要写在partiton by()
create table mytable3(
id int,
name string)
partitioned by(sex string) row format delimited fields terminated by '\t'stored as textfile;
静态分区插入数据
load data local inpath '/root/hivedata/boy.txt' overwrite into table mytable3 partition(sex='boy');
增加分区:
alter table mytable3 add partition (sex='unknown') location '/user/hive/warehouse/mytable3/sex=unknown';
删除分区:alter table mytable3 drop if exists partition(sex='unknown');
分区表默认为静态分区,可转换为自动套分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
给分区表灌入数据:
insert into table mytable3 partition (sex) select id,name,'boy' from student_mdf;
查询表分区:show partitions mytable3;
查询分区表数据:select * from mytable3;
查询表结构:desc mytable3;
DML:
重命名表:alter table student rename to student_mdf
增加列:alter table student_mdf add columns (sex string);
修改列名:alter table student_mdf change sex gender string;
替换列结构:alter table student_mdf replace columns (id string, name string);
装载数据:(本地数据)load data local inpath '/home/lym/zs.txt' overwrite into student_mdf;
(HDFS数据)load data inpath '/zs.txt' into table student_mdf;
插入一条数据:insert into table student_mdf values('1','zhangsan');
创建表接收查询结果:create table mytable5 as select id, name from mytable3;
导出数据:(导出到本地)insert overwrite local directory '/root/hivedata/mytable5.txt' select * from mytable5;
(导出到HDFS)
insert overwrite directory 'hdfs://master:9000/user/hive/warehouse/mytable5_load' select * from mytable5;
数据查询:
select * from mytable3; 查询全表
select uid,uname from student; 查询学生表中的学生姓名与学号字段
select uname,count(*) from student group by uname; 统计学生表中每个名字的个数
常用的功能还有 having、order by、sort by、distribute by、cluster by;等等
关联查询中有
内连接:将符合两边连接条件的数据查询出来
select * from t_a a inner join t_b b on a.id=b.id;
左外连接:以左表数据为匹配标准,右边若匹配不上则数据显示null
select * from t_a a left join t_b b on a.id=b.id;
右外连接:与左外连接相反
select * from t_a a right join t_b b on a.id=b.id;
左半连接:左半连接会返回左边表的记录,前提是其记录对于右边表满足on语句中的判定条件。
select * from t_a a left semi join t_b b on a.id=b.id;
全连接(full outer join):
select * from t_a a full join t_b b on a.id=b.id;
in/exists关键字(1.2.1之后新特性):效果等同于left semi join
select * from t_a a where a.id in (select id from t_b);
select * from t_a a where exists (select * from t_b b where a.id = b.id);
shell操作Hive指令:
-e:从命令行执行指定的HQL:
-f:执行HQL脚本
-v:输出执行的HQL语句到控制台
![]()
内置函数
查看内置函数:show functions;
显示函数的详细信息:DESC FUNCTION abs;
重要常用内置函数:sum()--求和 count()--求数据量 avg()--求平均值
distinct--去重 min--求最小值 max--求最大值
自定义函数:
1.先开发一个简单的Java类,org.apache.hadoop.hive.ql.exec.UDF,重载evaluate方法
import org.apache.hadoop.hive.ql.exec.UDF;
public final class AddUdf extends UDF {
public Integer evaluate(Integer a, Integer b) {
if (null == a || null == b) {
return null;
} return a + b;
}
public Double evaluate(Double a, Double b) {
if (a == null || b == null)
return null;
return a + b;}
}
2.打成jar包上传到服务器
3.将jar包添加到hive add jar /home/lan/jar/addudf.jar;
4.创建临时函数与开发好的class关联起来
CREATE TEMPORARY FUNCTION add_example AS 'org.day0914.AddUdf';
5.使用自定义函数 SELECT add_example(scores.math, scores.art) FROM scores;
销毁临时函数:DROP TEMPORARY FUNCTION add_example;
Hive相关工具:Sqoop Azkaban Flume
Sqoop
Sqoop是一个开源工具,它允许用户将数据从关系型数据库抽取到Hadoop中,用于进一步的处理。抽取出的数据可以被MapReduce程序使用,也可以被其他类似于Hive的工具使用。一旦形成分析结果,Sqoop便可以将这些结果导回数据库,供其他客户端使用
用户向 Sqoop 发起一个命令之后,这个命令会转换为一个基于 Map Task 的 MapReduce 作业。Map Task 会访问数据库的元数据信息,通过并行的 Map Task 将数据库的数据读取出来,然后导入 Hadoop 中。 将 Hadoop 中的数据,导入传统的关系型数据库中。它的核心思想就是通过基于 Map Task (只有 map)的 MapReduce 作业,实现数据的并发拷贝和传输,这样可以大大提高效率
数据导入:首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上
数据导出:首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中
sqoop查询语句
进入sqoop安装主目录:cd /home/lanou/sqoop-1.4.5.bin__hadoop-2.0.4-alpha
将HDFS上的数据导入到MySQL中:bin/sqoop export --connect jdbc:mysql://192.168.2.136:3306/test --username hadoop --password hadoop --table name_cnt --export-dir '/user/hive/warehouse/mydb.db/name_cnt' --fields-terminated-by '\t'
将MySQL中的数据导入到HDFS上:
bin/sqoop import --connect jdbc:mysql://192.168.2.136:3306/test --username hadoop --password hadoop --table name_cnt -m 1
sqoop:表示sqoop命令
export:表示导出
--connect jdbc:mysql://192.168.2.136:3306/test :表示告诉jdbc,连接mysql的url。
--username hadoop: 连接mysql的用户名
--password hadoop: 连接mysql的密码
--table name_cnt: 从mysql要导出数据的表名称
--export-dir '/user/hive/warehouse/mydb.db/name_cnt' hive中被导出的文件
--fields-terminated-by '\t': 指定输出文件中的行的字段分隔符
Azkaban
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
Azkaban功能特点:1.兼容所有Hadoop版本
2.可以通过WebUI来进行管理配置,操作方便
3.更容易设置job的依赖关系
4.可以配置定时任务调度
5.邮件警告失败或成功 等等
Azkaban架构:
Azkaban使用MySQL去做一些状态的存储
Azkaban Web服务:Azkaban使用Jetty作为Web服务器,用作控制器以及提供Web界面
AzkabanWebServer对数据库的使用:项目管理:对项目权限和上传文件的管理;执行流程状态:对正在执行的程序进行跟踪;查看任务执行结果以及历史日志;调度程序:保持预定的工作状态。
Azkaban执行服务器,执行提交的工作流
AzkabanExecutorServer 对数据库的使用:获取项目:从数据库中检索项目文件;执行工作流或Jobs:从数据库获取要执行的任务流;Logs:存储作业的输出日志,并将其流入数据库;不同的依赖进行交流:如果一个流在不同的执行器上运行,它将从数据库中获取状态
安装Azkaban:
1.要先配置mysql。
1.1修改mysql的编码,vim /etc/my.cnf
![]()
![]()
1.2重启mysql,service mysqld restart 然后进入mysql,创建azkaban数据库并授权,刷新权限。与创建hive数据库相同。
2.配置Azkaban Web Server
2.1解压Azkaban压缩包 unzip azkaban-web-2.5.0.zip
2.2上传mysql驱动包
cp mysql-connector-java-5.1.43/mysql-connector-java-5.1.43-bin.jar azkaban-web-2.5.0/extlib/
2.3修改配置文件
修改azkaban.properties文件 cd azkaban-web-2.5.0/conf/ vim azkaban.properties
#默认时区改为亚洲/上海 默认为美国
default.timezone.id=Asia/Shanghai
#数据库连接IP
mysql.host=master
修改文件权限: chmod 755 /home/lanou/azkaban/azkaban-web-2.5.0/bin/*
配置jetty ssl:keytool -keystore keystore -alias jetty -genkey -keyalg RSA
Enter keystore password: password
What is your first and last name? 您的名字与姓氏是什么?
[Unknown]: jetty.mortbay.org
What is the name of your organizational unit?您的组织单位名称是什么?
[Unknown]: Jetty
What is the name of your organization?您的组织名称是什么?
[Unknown]: Mort Bay Consulting Pty. Ltd.
What is the name of your City or Locality?您所在的城市或区域名称是什么?
[Unknown]:
What is the name of your State or Province?您所在的州或省份名称是什么?
[Unknown]:
What is the two-letter country code for this unit?该单位的两字母国家代码是什么
[Unknown]:
Is CN=jetty.mortbay.org, OU=Jetty, O=Mort Bay Consulting Pty. Ltd.,
L=Unknown, ST=Unknown, C=Unknown correct?正确吗?
[no]: yes
Enter key password for <jetty>
(RETURN if same as keystore password): password
这里的密码要与 azkaban-web-2.5.0/conf/azkaban.properties 中设置的密码相同,否则会报错Keystore was tampered with, or password was incorrect。
1.job:
type=command
command=hadoop fs -mkdir /test
command.1=hadoop fs -put /home/lym /hadoop-2.7.1/README.txt /test
2.job:
type=command
command=hadoop jar /home/lym/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test /test-out
dependencies=1
实现上传/README.txt并且用wordcount计算
把需要运行的job放在同一个文件下面打成.zip格式的包,注意 Azkaban目前只支持.zip格式
页面操作:首先是登陆azkaban;创建一个工程;上传job;执行job;查看job执行情况
绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况
Flume
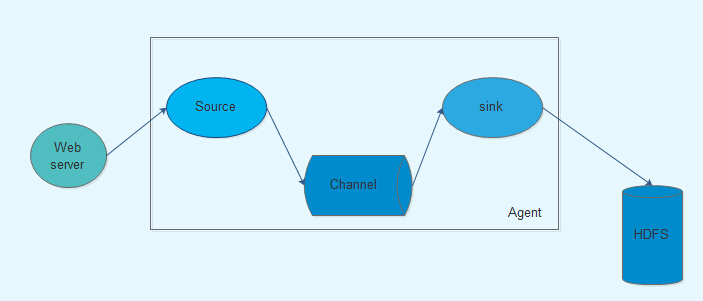
Flume是Cloudera提供的日志收集系统,具有分布式、高可靠、高可用性等特点,对海量日志采集、聚合和传输,Flume支持在日志系统中制定各类数据发送,同时,Flume提供对数据进行简单处理,并写到各种数接受方的能力。其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
![]()
Flume的核心是把数据从数据源收集过来,在送到目的地,为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据
Flume传输的数据基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event从Source,流向Channel,再到Sink,本身为一个byte数组,并可携带headers信息。Event代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event可以从一个地方流向另外一个地方
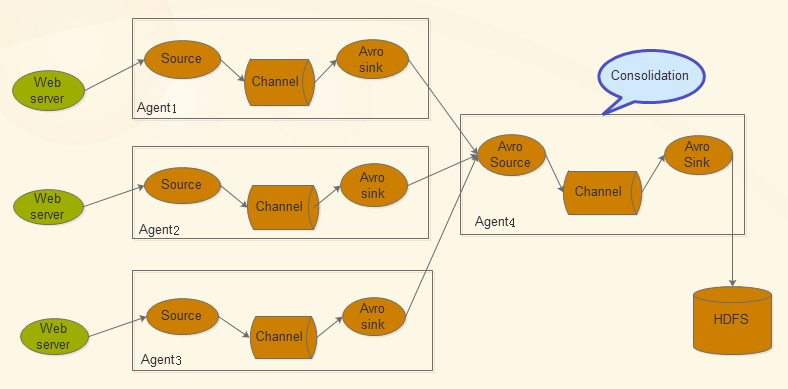
Flume允许多个agent连在一起,形成前后相连的多级跳:
![]()
核心组件:source channel sink
source:source负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个channel;source必须至少和一个channel关联
channel:channel位于source和sink之间,用于缓存进来的event;当Sink成功的将event发送到下一跳的channel或最终目的时候,event从Channel移除
sink:Sink负责将event传输到下一跳或最终目的;sink在设置存储数据时,可以向文件系统、数据库、Hadoop存数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到hadoop中,便于日后进行相应的数据分析;必须作用于一个确切的channel
安装部署:
1.下载 http://mirror.bit.edu.cn/apache/flume/1.6.0/
2.解压 tar -xvf apache-flume-1.6.0-bin.tar.gz tar -xvf apache-flume-1.6.0-src.tar.gz
3.将源码合并至安装目录apache-flume-1.6.0-bin下:
cp -r apache-flume-1.6.0-src apache-flume-1.6.0-bin/
3.配置环境变量 vim ~/.bash_profile
export FLUME_HOME=/home/lan/apache-flume-1.6.0-bin/
export PATH=$PATH:$FLUME_HOME/bin
4.测试flume-ng是否安装成功:flume-ng version
测试flume-ng功能:将收集到的日志输出到hdfs上为
新建一个flume代理agent1的配置文件example.conf:
cd apache-flume-1.6.0-bin/conf/ vim example.conf
#agent1
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = c1
#source1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/lan/agent1log
agent1.sources.source1.channels = c1
agent1.sources.source1.fileHeader = false
#sink1
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://master:9000/agentlog
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat = TEXT
agent1.sinks.sink1.hdfs.rollInteval = 4
agent1.sinks.sink1.channel = c1
#channel1
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /home/lan/agent1_tmp1
agent1.channels.c1.dataDirs = /home/lan/agent1_tmpdata
#agent1.channels.channel1.capacity = 10000
#agent1.channels.channel.transactionCapacity = 1000
新建agent1log :mkdir agent1log
启动flume-ng:
cd apache-flume-1.6.0-bin
flume-ng agent -n agent1 -c conf -f /home/lan/apache-flume-1.6.0-bin/conf/example.conf -Dflume.root.logger=DEBUG,console
另启一个terminal,在监测目录下创建新的文件test2.txt
cd ~/agent1log
vim test2.txt
查看sink1的输出,发现目标路径下有一个以FlumeData开始,产生文件的时间戳为后缀的文件,说明flume能监测到目标目录变化,将产生变化的部分实时地收集到sink的输出中。







 浙公网安备 33010602011771号
浙公网安备 33010602011771号