第一次个人编程作业
| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 设计一个论文查重法 |
**一、GitHub链接 **
二、PSP表格设计
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 315 | 600 |
| ·Estimate | ·估计这个任务需要多少时间 | 315 | 1090 |
| Development | 开发 | 250 | 120 |
| ·Analysis | ·需求分析 (包括学习新技术) | 120 | 600 |
| · Design Spec | · 生成设计文档 | 10 | 60 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 20 |
| · Coding | · 具体编码 | 30 | 120 |
| · Code Review | · 代码复审 | 10 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 120 |
| Reporting | 报告 | 65 | 50 |
| · Test Repor | · 测试报告 | 30 | 10 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 315 | 1140 |
三、计算模块接口的设计与实现过程
对要求进行分析可知,程序应分为三个部分:事先准备工作,求文本相似度,保存工作。
1、事先准备工作:
由于采用命令行读取参数工作,因此需要引入argparse包,即
import argparse
parser = argparse.ArgumentParser()#为读取命令行参数作准备
parser.add_argument('add1', type=str, default = None)
parser.add_argument('add2', type=str, default=None)
parser.add_argument('add3', type=str, default=None)
args = parser.parse_args()
以上代码即为读取命令行中的三个文本做好准备。
文本绝对路径由命令行读取而来,通过绝对路径,采用read()读取对应文件,且以防出现乱码,需要强制encoding='utf-8'
2、求文本相似度:
该设计选取使用sklearn库来完成余弦相似度计算流程图如下:
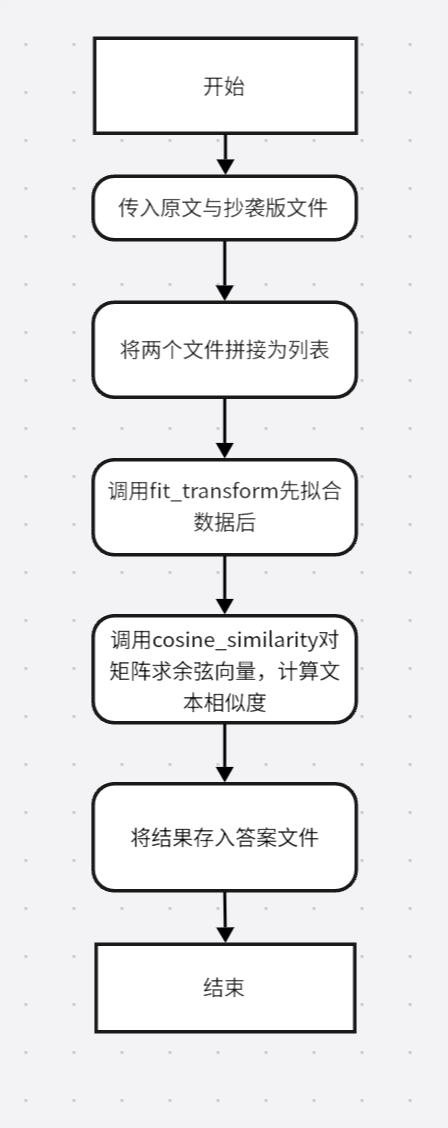
代码如下:
vectorizer = CountVectorizer()
list = [p1, p2]#将两个文件拼接为列表
vectors = vectorizer.fit_transform(list)#先拟合数据,然后转化它将其转化为标准形式,一步到位
similarity = cosine_similarity(vectors)
return similarity[0][1]
四、计算模块接口部分的性能改进
记录在改进计算模块性能上所花费的时间:
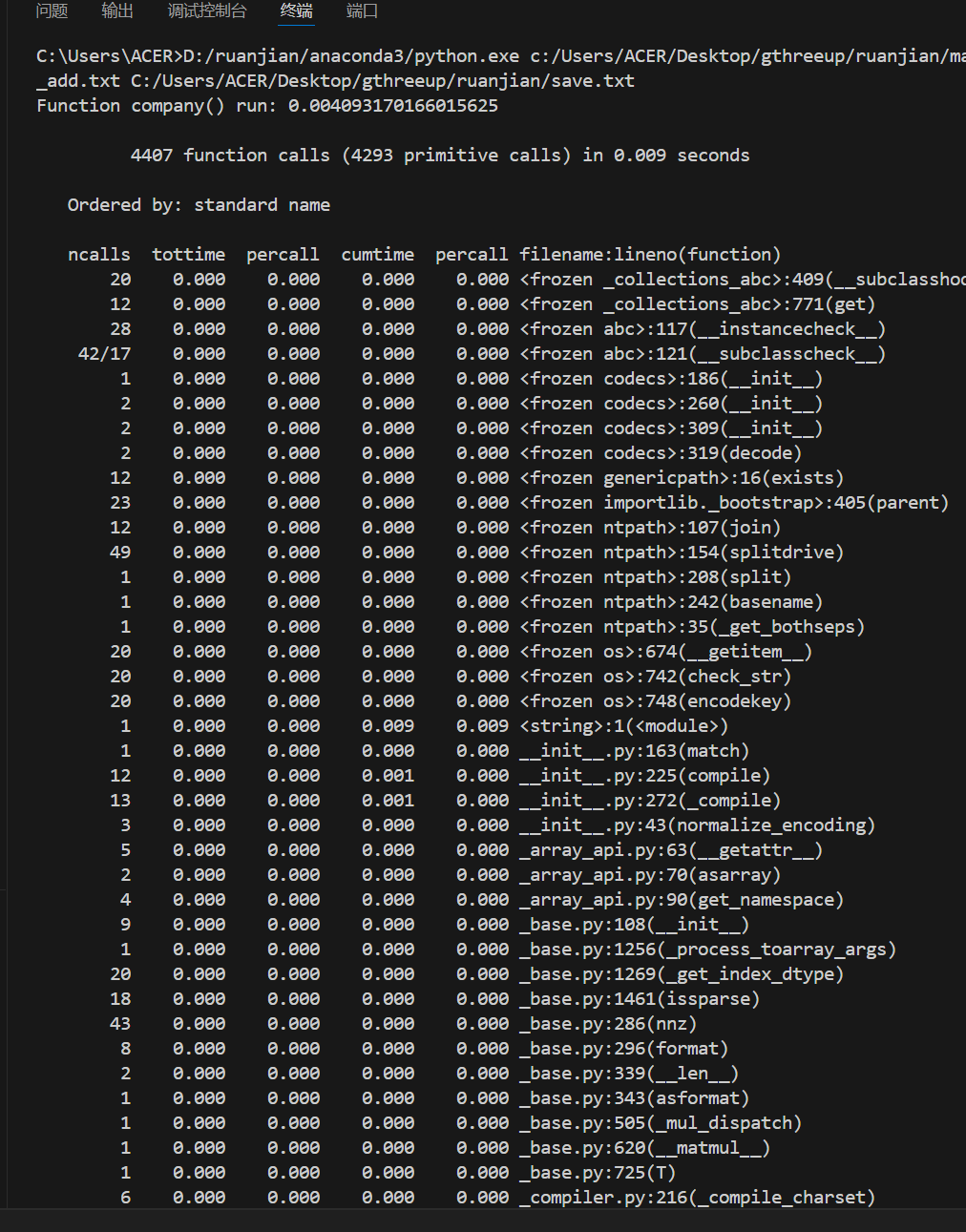
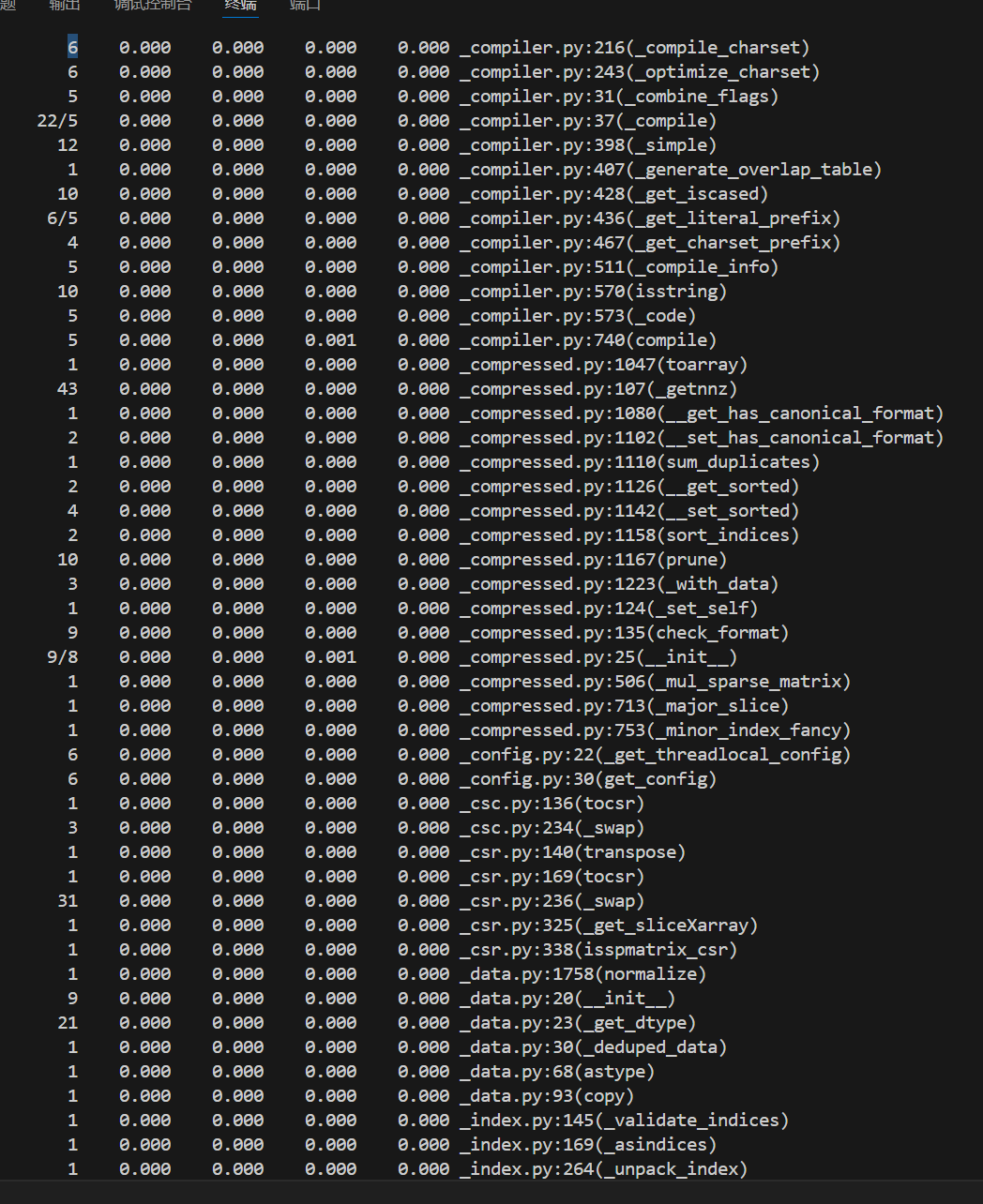
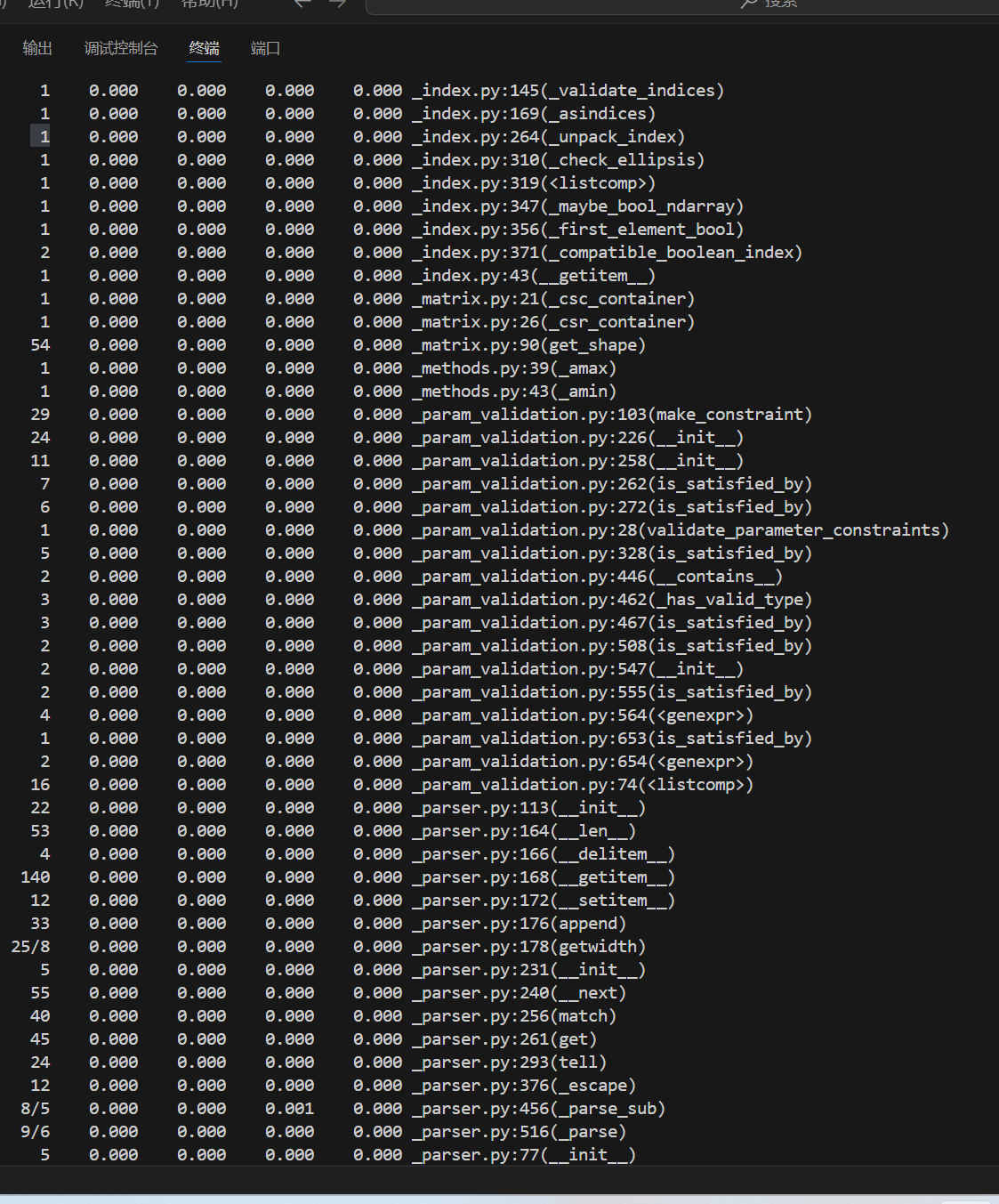
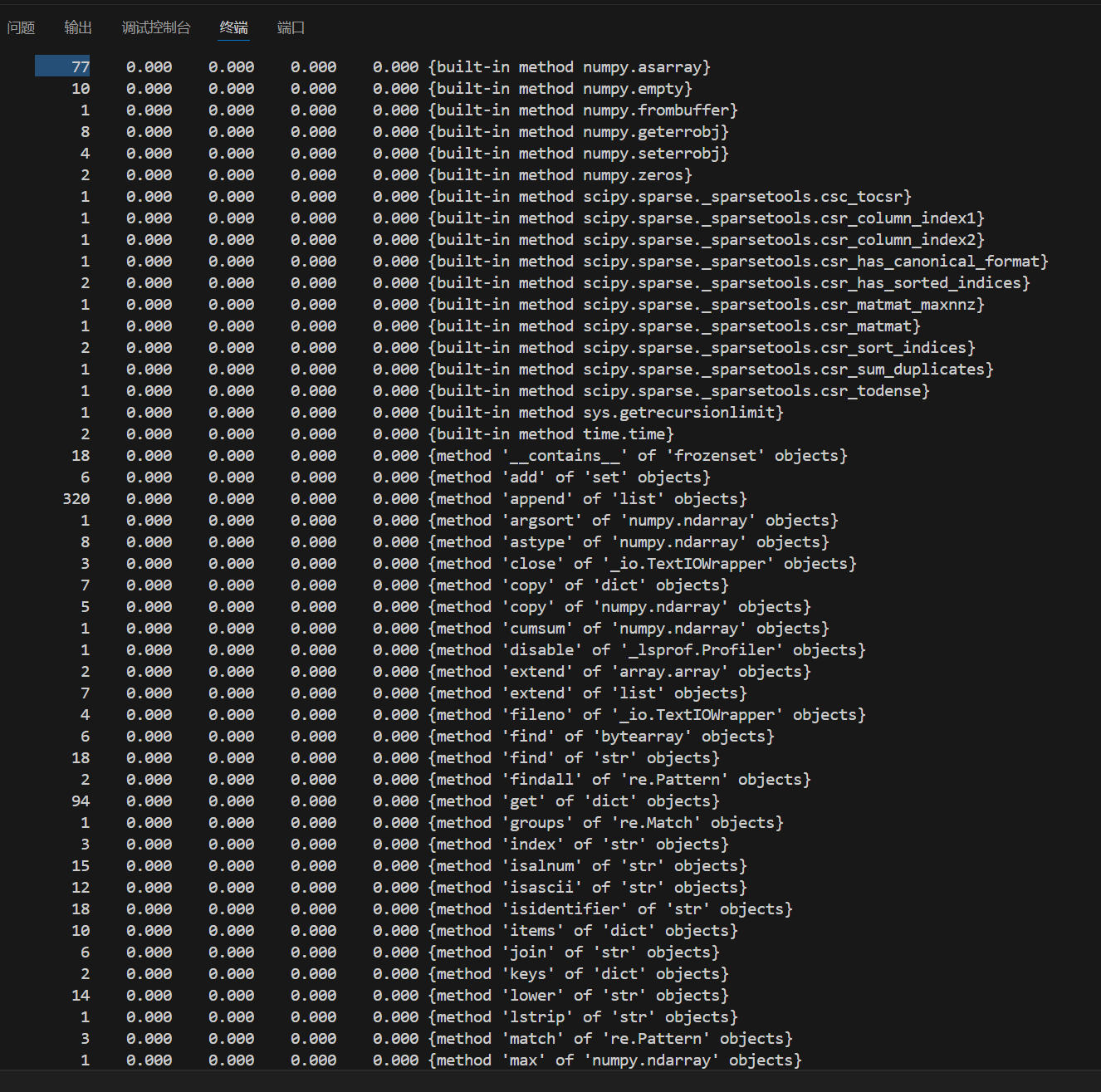
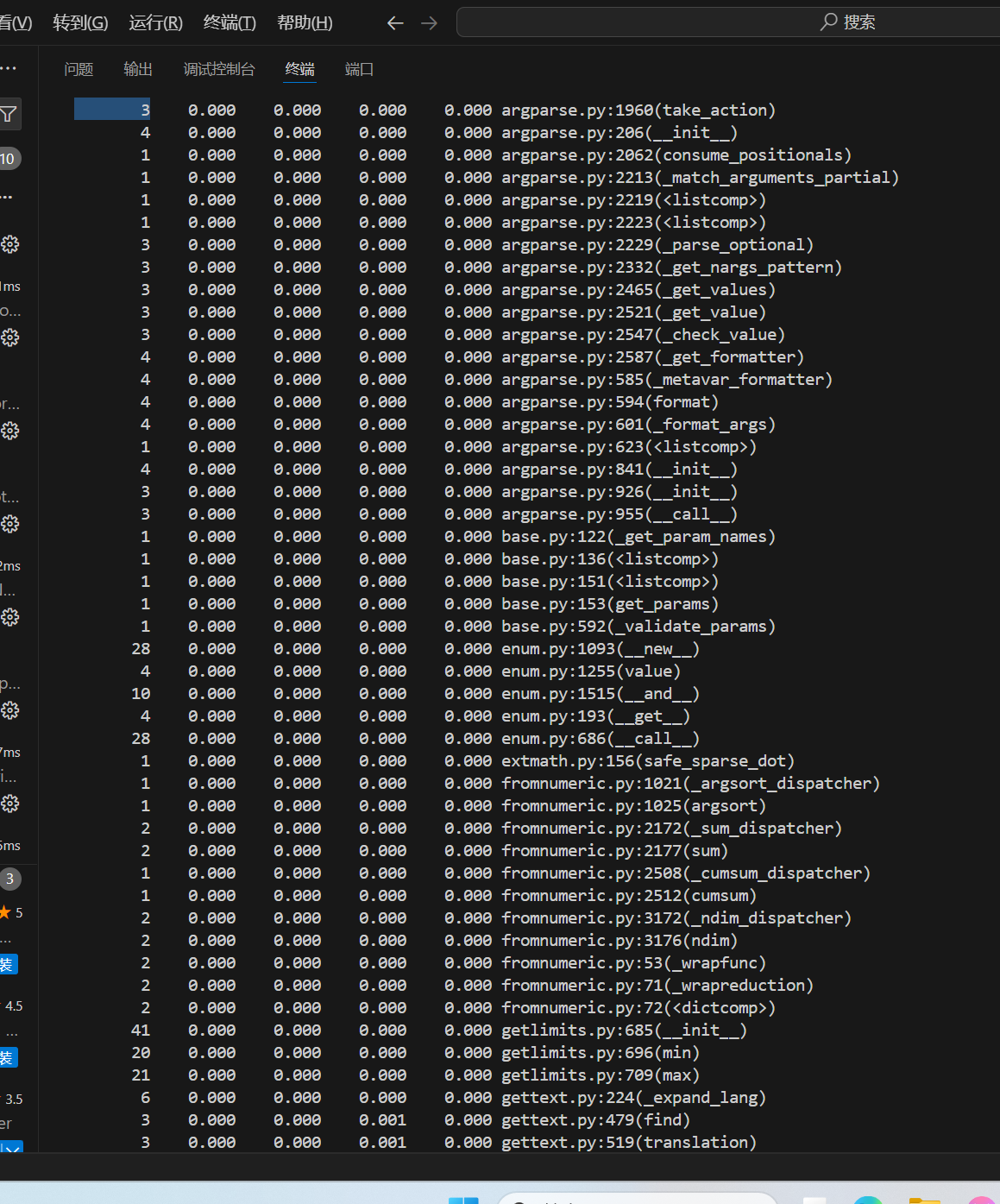
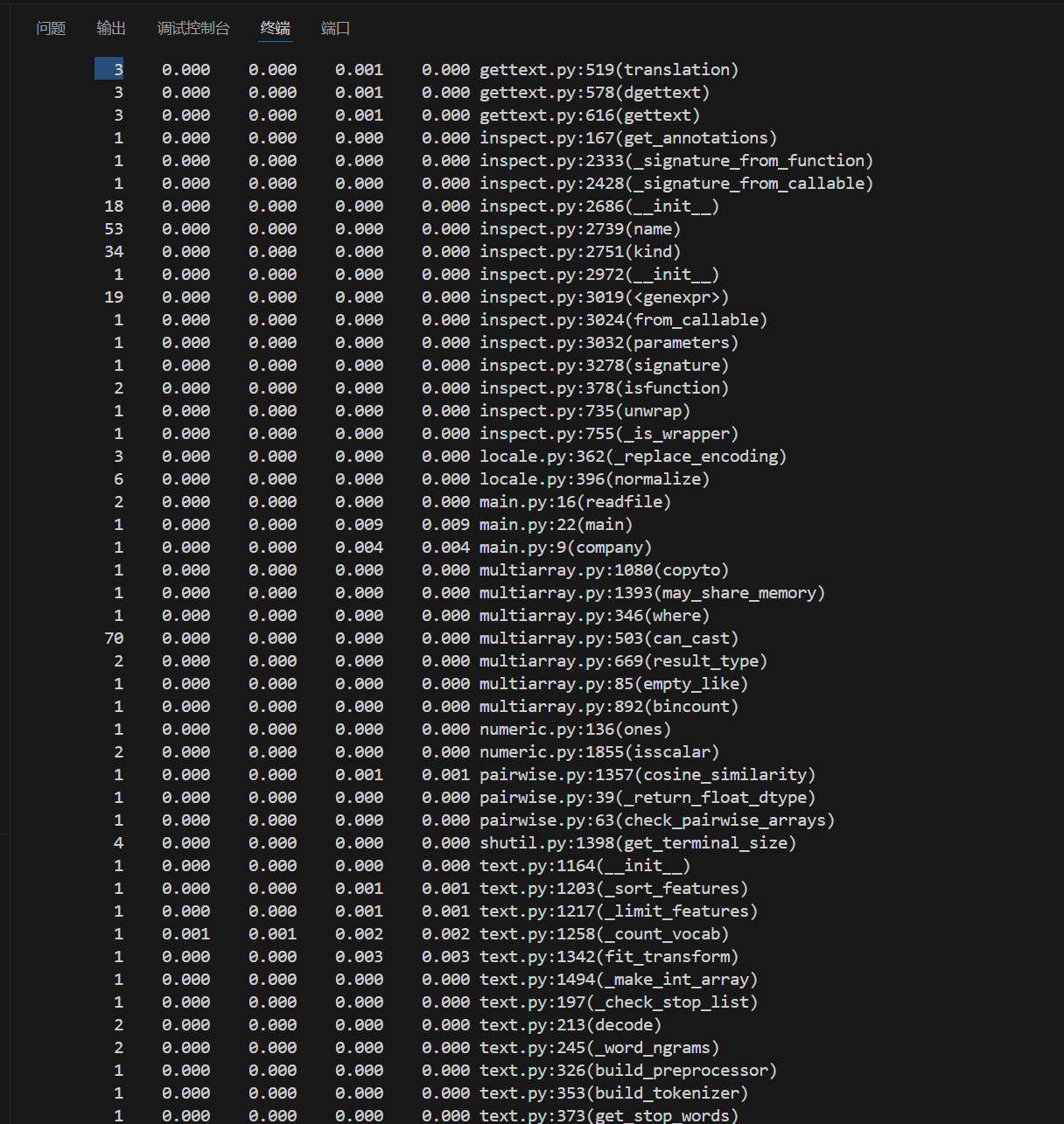
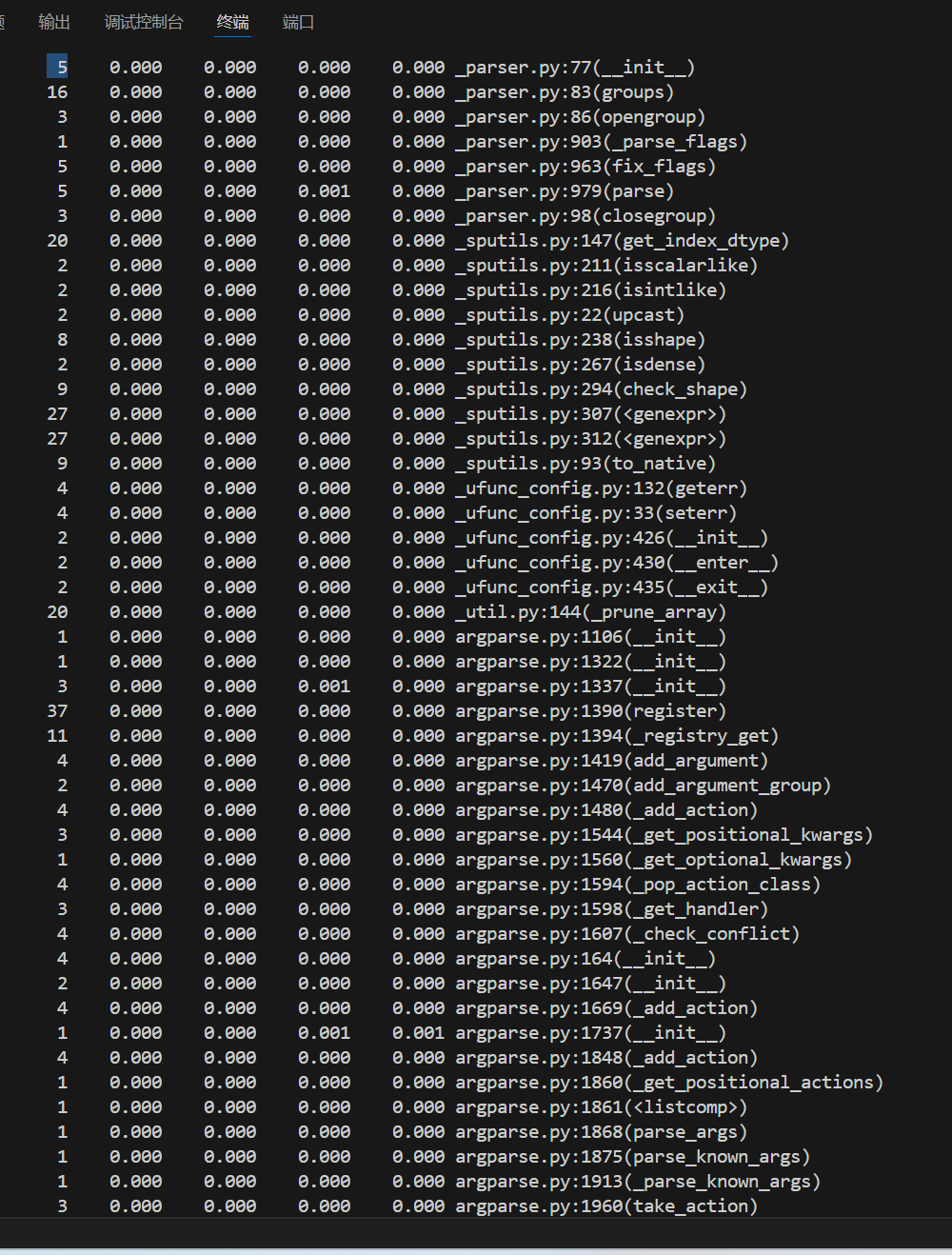
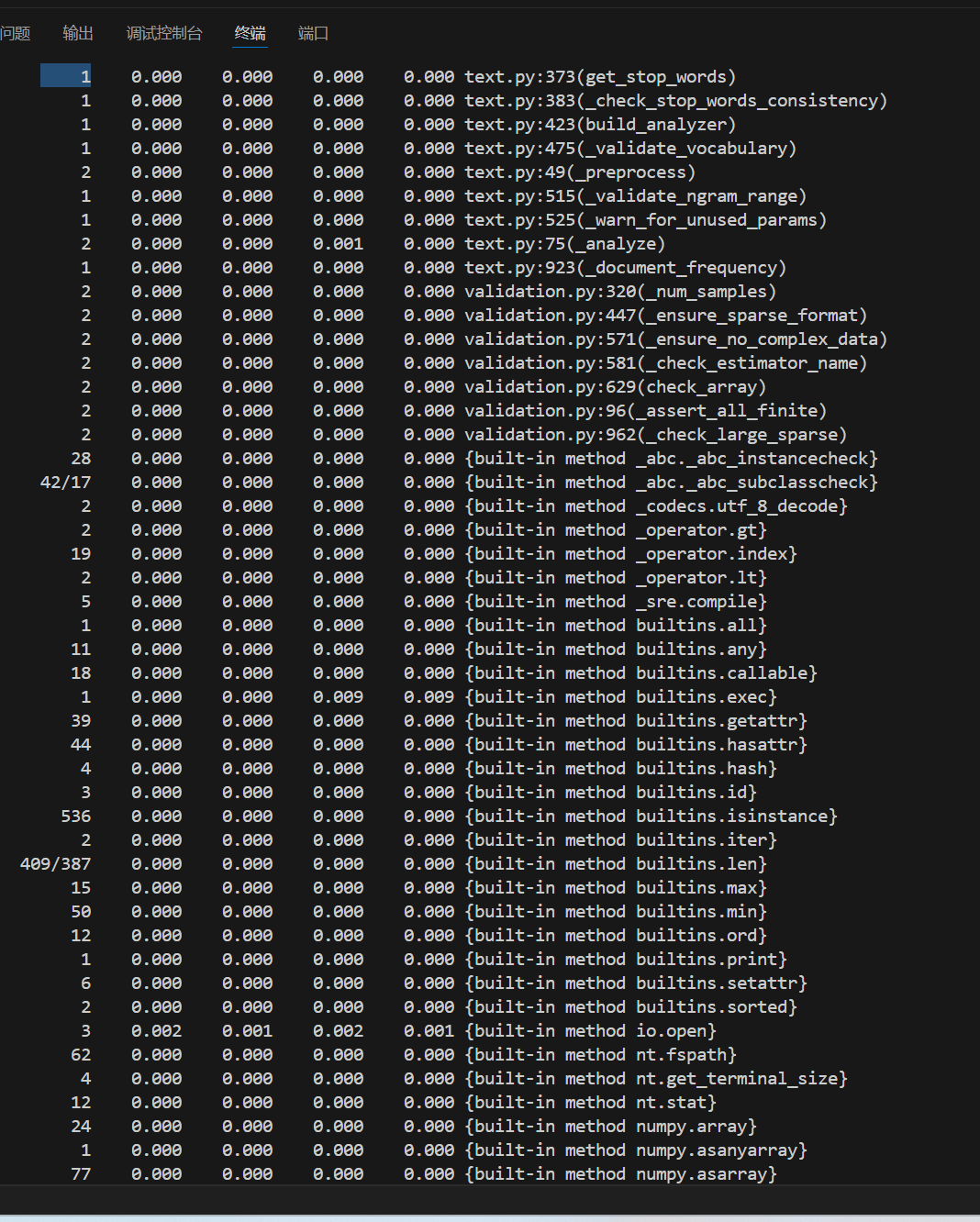
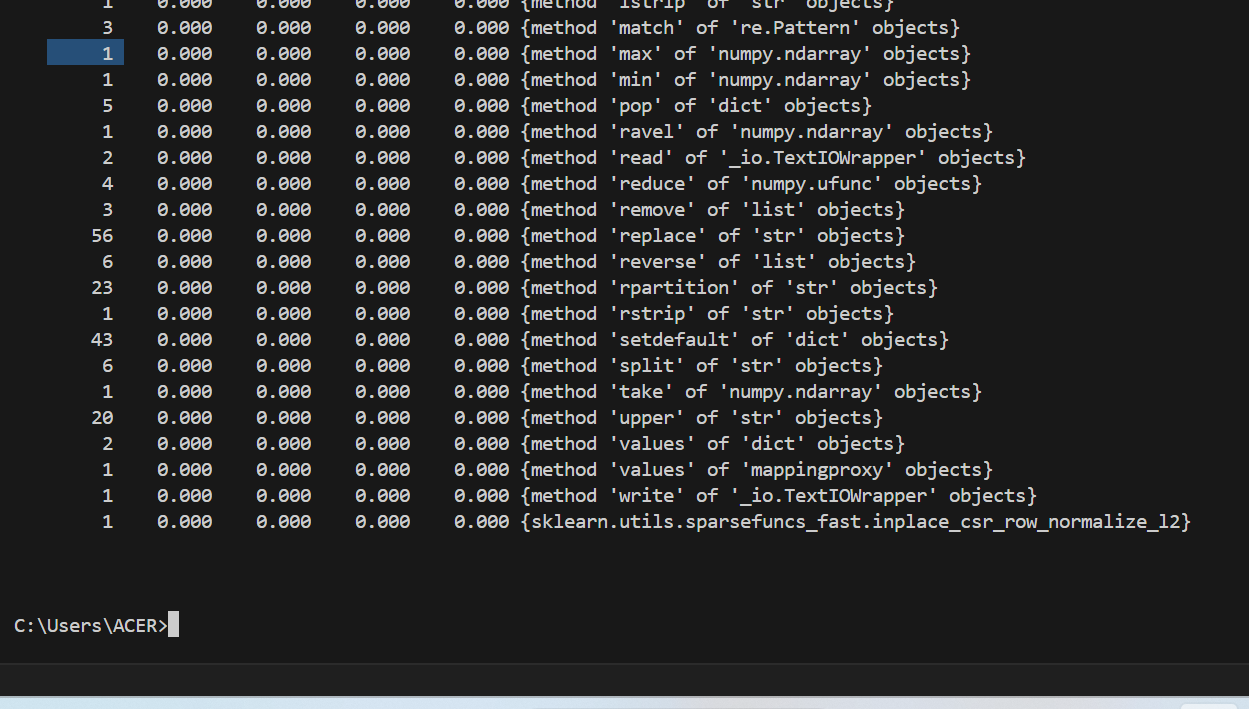
由上图可知,耗时最长函数为io.open,因为是库函数,没有改进方案。
五、计算模块部分单元测试展示
单元测试代码如下:
import sys
import argparse
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
#采用余弦相似度算法计算文本相似度
def company(p1, p2):
vectorizer = CountVectorizer()
list = [p1, p2]#将两个文件拼接为列表
vectors = vectorizer.fit_transform(list)#先拟合数据,然后转化它将其转化为标准形式,一步到位
similarity = cosine_similarity(vectors)
return similarity[0][1]
def readfile(address):
f = open(address,'r',encoding='utf-8') #设置文件对象
p = f.read()
f.close()
return p
if __name__ == '__main__':
parser = argparse.ArgumentParser()#为读取命令行参数作准备
parser.add_argument('add1', type=str, default = None)
parser.add_argument('add2', type=str, default=None)
parser.add_argument('add3', type=str, default=None)
args = parser.parse_args()
p1=readfile(args.add1)
p2=readfile(args.add2)
result = company(p1, p2)*100
f=open(args.add3,'w',encoding='utf-8')
f.write("两个文本相似度为: %.2f"%result)#采用百分制,保留两位小数
f.close()
测试的函数为main函数,readfile函数和company函数,对main函数,覆盖率为百分百。
六、计算模块部分异常处理说明
文件不存在:

发生场景为:命令行参数中,原文路径或者抄袭版文本路径错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号