
使用python获取学习强国上的新闻
项目流程 通过学习强国网站 拉取重要新闻,重要活动,重要会议,重要讲话四个模块的数据和页面内容。
第一步:创建爬虫对象news_scrapy,并引入要使用的程序包
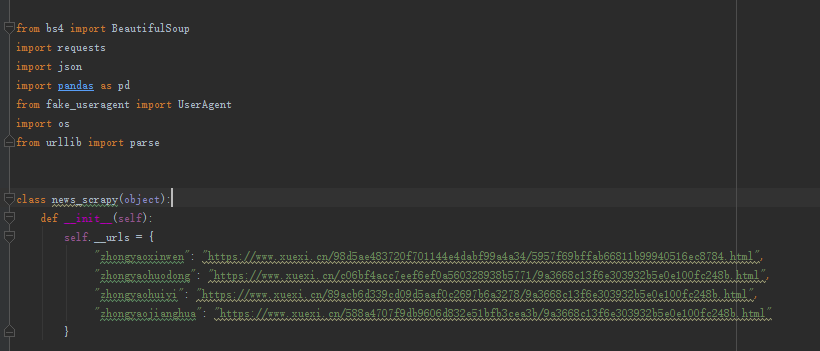
其中包括定义要拉取的4个站点的URL。
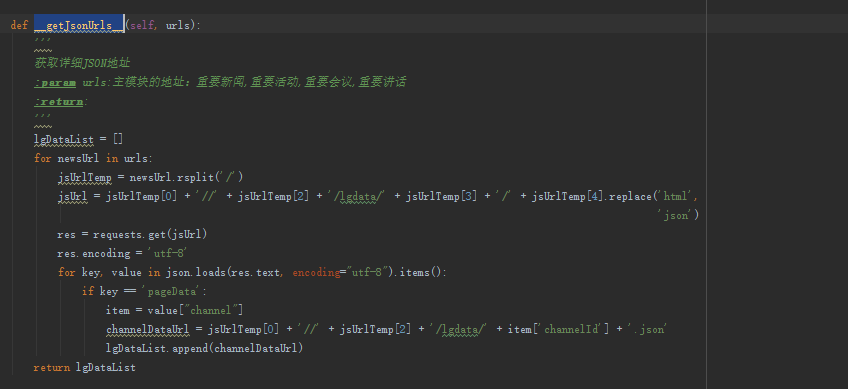
第二步:获取每个站点的列表数据 方法名称__getJsonUrls__
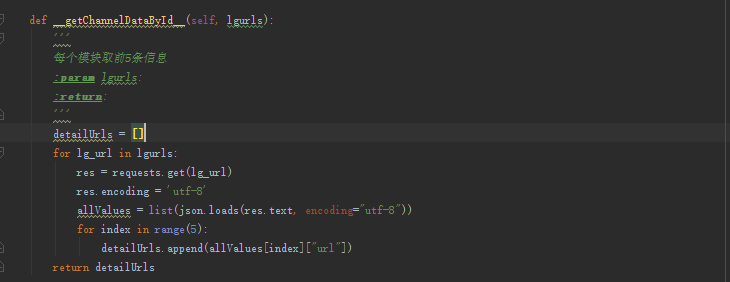
第三步:获取列表中每个地址的对应URL数据 方法名__getChannelDataById__
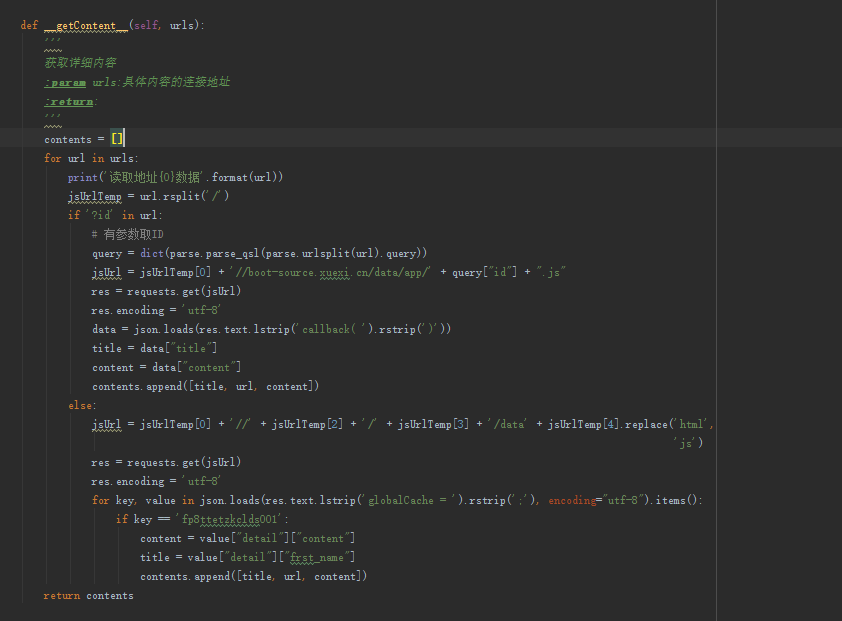
第四步:通过URL地址获取页面的详细内容 方法名__getContent__
第五步:把获取的内容写入CSV中
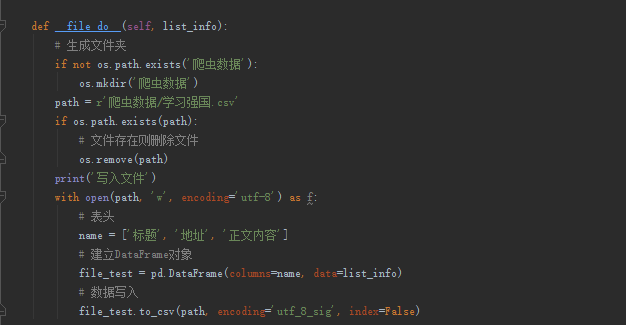
最后生成的CSV数据如图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号