解剖SQLSERVER 第一篇 数据库恢复软件商的黑幕(有删减版)
解剖SQLSERVER 第一篇 数据库恢复软件商的黑幕(有删减版)
这一系列,我们一起来解剖SQLSERVER
在系列的第一篇文章里本人可能会得罪某些人,但是作为一位SQLSERVER MVP,在我的MVP任期内希望可以对大家作出一些贡献
在第一篇里面涉及到某些内容可能不会以详细的方式给出截图并且和大家讲解,毕竟第一篇的篇幅比较长,希望大家见谅。。
在第一篇文章开始之前,先说三个题外话
第一个题外话 更新丢失
首先要做的事情是,跟大家道歉
在之前《SQLSERVER走起》的微信公众帐号里推送了一篇文章,题目是《RDS-SQLSERVER的READ COMMITTED与READ_COMMITTED_SNAPSHOT的区别及各自优缺点》
由于当时没有仔细看,就给大家推送了,文章里面的建议确实是误导了大家
文章里面这样说道
举个例子描述这个场景:
T1事务发起一个修改,读取原库存是10,需求修改库存减1,原库存应该变成9,因为是READ_COMMITTED_SNAPSHOT隔离级别,所以数据库会在tempdb里生成一个快照,但是事务未提交,在这时发起了第二事务T2,也来修改库存,因为看到事务T1未提交,所以他不能获取未提交事务修改的值9(如果获取9就是脏读了),而是他获取的是最后提交版本的库存为10,而正巧T2未提交前,T1先提交了,实际库存应该变9而不是10,但T2事务获取库存值是10,假设T2的需求是减库2,那么最后T2提交后,会覆盖T1事务所做的修改,库存变成了8(我们实际期望的是10-1-2=7),这样就造成了逻辑混乱。
实际上,这种情况不是逻辑混乱,这种情况是属于 “更新丢失”,大家随便拿起一本SQLSERVER教科书,里面都会有说到更新丢失这种现象

文章里面说的解决方案基本上是错误的
错误一:提高事务隔离级别将会造成更加多的死锁
错误二:没有对“更新丢失”进行错误处理
我的好朋友高继伟(博客园里的shanks_gao)跟这个阿里云SQLSERVER经理说过这个问题,但是最后他还是没有改过来
解决方案有两种,都是在默认隔离级别 READ COMMITTED下,不需要修改默认隔离级别
第一种:使用try catch捕获更新丢失
--示例 CREATE TABLE kucun(id INT PRIMARY KEY,qty INT,product NVARCHAR(20))
--插入一些测试数据 SELECT * FROM dbo.kucun ----------------------------------------------- --session 1 BEGIN TRAN DECLARE @qty INT SELECT @qty=qty FROM kucun WITH(UPDLOCK) WHERE [product]='牙膏' SELECT @qty UPDATE kucun SET qty=@qty-1 WHERE [product]='牙膏' COMMIT TRAN ------------------------------------------ --session 2 BEGIN TRAN DECLARE @qty INT SELECT @qty=qty FROM kucun WITH(UPDLOCK) WHERE [product]='牙膏' --阻塞 SELECT @qty --session 1提交之后才可以读,但是后面的update语句不会执行,这个时候更新丢失,使用try catch机制来捕获更新丢失 UPDATE kucun SET qty=@qty-1 WHERE [product]='牙膏' COMMIT TRAN
第二种: 如果使用的是SQLSERVER2008 可以使用merge语句来执行这个原子操作
--session 1
BEGIN TRAN
MERGE [dbo].[kucun] AS TGT
USING [dbo].[kucun] AS SRC
ON TGT.product = SRC.product AND TGT.id = SRC.id AND TGT.product = '牙膏'
WHEN MATCHED THEN
UPDATE SET
TGT.qty = TGT.qty - 1;
COMMIT TRAN
SELECT * FROM [dbo].[kucun] WHERE product = '牙膏'
--session 2
--当session 1没有提交的时候就会阻塞,当session 1提交的时候 session 2 也能成功update记录 ,不会造成更新丢失
BEGIN TRAN
MERGE [dbo].[kucun] AS TGT
USING [dbo].[kucun] AS SRC
ON TGT.product = SRC.product AND TGT.id = SRC.id AND TGT.product = '牙膏'
WHEN MATCHED THEN
UPDATE SET
TGT.qty = TGT.qty - 1;
COMMIT TRAN
希望大家升级一下SQLSERVER,使用SQLSERVER2008提供的最新的merge语句,因为merge语句确实能够减少很多不必要的麻烦,而且性能也会有提升
看到这里,可能大家对这种最基础最基础的知识不以为然,但是大家试想一下,恰好这种最基础的东西就有可能带来致命的后果
例子:
比如你的银行账户里有100万,你取出来了20万,还剩下80万
但是刚好遇到更新丢失,你的账户里面可能已经取出了钱但是系统里面没有扣取你的钱又或者扣除多了 、扣除少了
后果可大可小
还有库存系统,这里就不说了
大家可能觉得“桦仔想借用这个例子,趁机贬低他人来抬高自己” 。实际上,我对于这个经理也是很理解,
当你管理成千成万台服务器的时候,你的脑子里就会想到数据库架构、集群搭建、容灾、业务连续性。。。
这是数据库架构师要做的事,很难会顾及到这些基础的东西,我自己也是管理着公司很多的数据库
但是作为数据库专家,你给客户的建议应该要足够专业吧???
第二个题外话 估计行数
脚本
USE [sss]
SELECT @@VERSION
--Microsoft SQL Server 2005 - 9.00.4035.00 (X64)
--Nov 24 2008 16:17:31
--Copyright (c) 1988-2005 Microsoft Corporation
--Developer Edition (64-bit) on Windows NT 6.1 (Build 7601: Service Pack 1)
CREATE TABLE teststat(id INT,name NVARCHAR(20))
--首先插入5条记录
INSERT INTO teststat
SELECT 1 ,'nihao' UNION ALL
SELECT 2 ,'dajiahao' UNION ALL
SELECT 3 ,'nihao' UNION ALL
SELECT 4 ,'dajiahao' UNION ALL
SELECT 5 ,'nihao'
--显示实际执行计划
SELECT * FROM teststat
--预估行数5条
--查看缓存的执行计划
SELECT [cacheobjtype] ,
[objtype] ,
[usecounts] ,
[sql]
FROM sys.[syscacheobjects]
WHERE [sql] NOT LIKE '%cache%'
AND [sql] LIKE '%INSERT INTO%'
--再插入100条记录
INSERT INTO teststat(id,name)
SELECT 6,'dajiahao'
GO 100
--查询缓存的执行计划
SELECT [cacheobjtype] ,
[objtype] ,
[usecounts] ,
[sql]
FROM sys.[syscacheobjects]
WHERE [sql] NOT LIKE '%cache%'
AND [sql] LIKE '%INSERT INTO%'
--显示实际执行计划
SELECT * FROM teststat
--预估行数还是5条
--清空编译计划
DBCC FREEPROCCACHE
GO
--显示实际执行计划
SELECT * FROM teststat
--预估行数变成105条
第一次查看缓存的执行计划
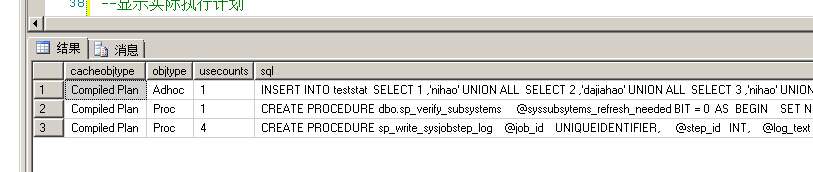
第二次查看缓存的执行计划
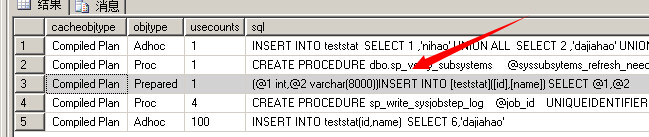
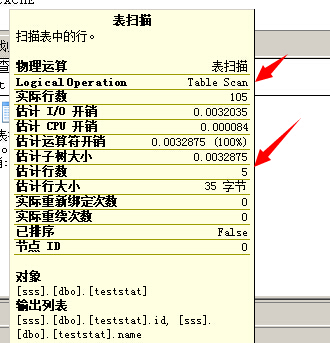
清空plan cache之后
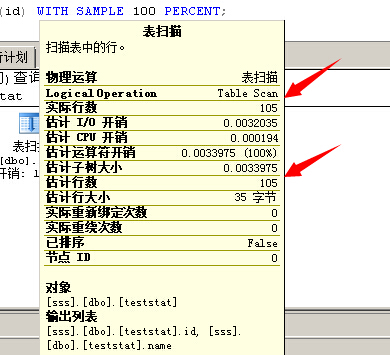
注意:DBCC FREEPROCCACHE是清空实例级别的计划缓存,请不要随意在生产环境下执行
第三个题外话 性能太差的SQLSERVER
某一天,开发又抱怨了:“SQLSERVER很慢,查询要差不多9秒,这个问题怎麽彻底解决!”
这个例子不是证明SQLSERVER多牛逼,只是为了说明数据量大的时候,SQLSERVER也可以应付
开发查询的是一张xxclassifyxx表,表数据1.8亿+
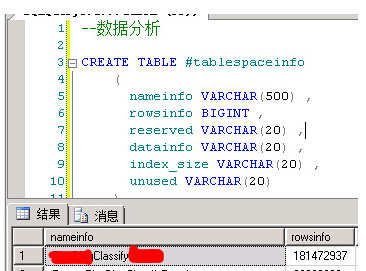
查询语句如下
SELECT TOP 500 * FROM DBO.xxCLASSIFYxx with (nolock) WHERE ID>5102332830 ORDER BY ID
表情况:
聚集索引建立在ID列上
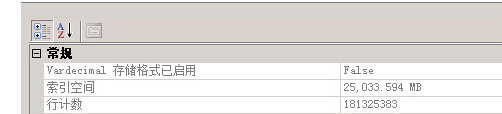
上面的查询大概需要8秒
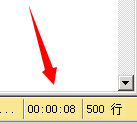
大家看到这个SQL语句可能一开始并没有什么头绪,但大家会发现,聚集索引既然建立在ID这一列上,那么ORDER BY ID是不是有点多余呢???
语句修改之前
执行时间 8秒 (500 行受影响) 表 'xxClassifyxx'。扫描计数 113,逻辑读取 619665 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。

语句修改之后,只是去掉了ORDER BY ID
SELECT TOP 500 * FROM DBO.xxCLASSIFYxx with (nolock) WHERE ID>5102332830
(500 行受影响) 表 'xxClassifyxx'。扫描计数 1,逻辑读取 32 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
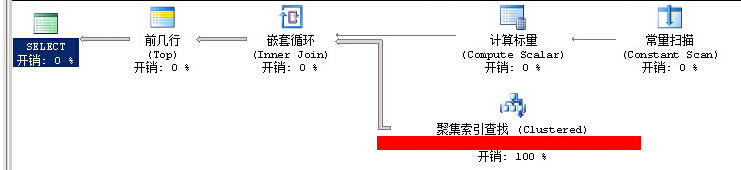
修改之后所用时间

在这里,加ORDER BY ID和不加ORDER BY ID对于SQLSERVER来看是不同的
正题
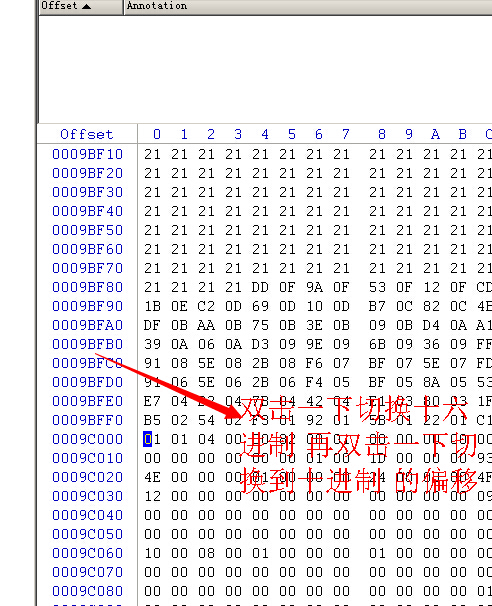

按照公式 逻辑页面号 * 8192 来算出偏移位置
这个计算公式没有错,只是,如果你真的要靠这个公式来找数据页面,很多时候会找不到
例如没有考虑到逻辑碎片的问题,而且我们平时搜索数据的时候一般都不会使用这个公式
还有大家在研究的时候不要将DBCC PAGE的输出中左边的偏移值和winhex中左边的偏移值对应起来
DBCC PAGE

WINHEX

测试脚本
 View Code
View Code
我们看下怎么用VS查看数据文件内容
我们使数据库脱机,然后把mdf文件拖入VS

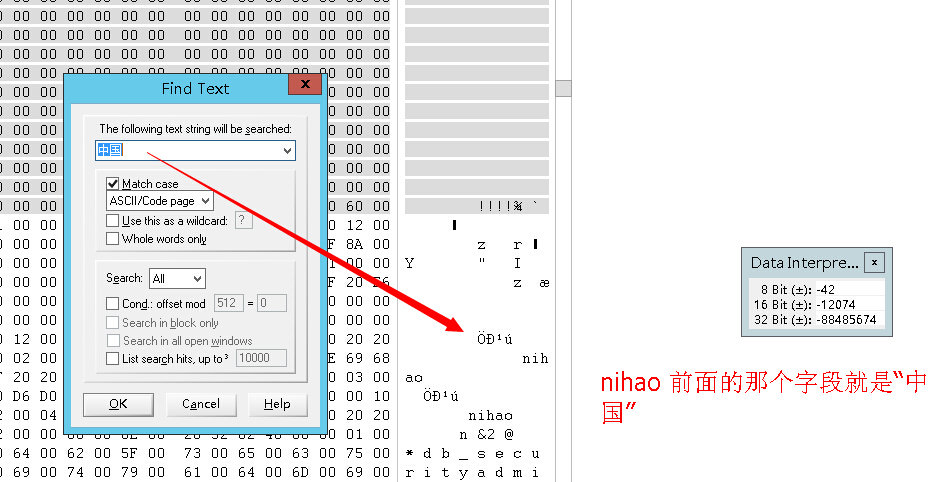
用winhex修改数据,选中要修改的数据的字节区域,然后右键—》edit-》你可以选择剪切、添加字节、填充零等等

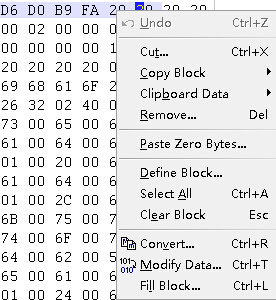
用Visual Studio修改数据更简单,选中要修改的字节区域,然后直接输入16进制数就可以了

在修改数据之前,把页面校验设置为NONE
ALTER DATABASE [sss] SET PAGE_VERIFY NONE
如果你修改数据页头的话,在修改完毕之后数据库还可以联机,但是你修改数据行的话,问题就严重了
消息 824,级别 24,状态 2,第 1 行 SQL Server 检测到基于一致性的逻辑 I/O 错误 校验和不正确(应为: 0xb70c8233,但实际为: 0xb7438233)。在文件 'E:\DataBase\sss.mdf' 中、偏移量为 0x0000000009a000 的位置对数据库 ID 8 中的页 (1:77) 执行 读取 期间,发生了该错误。SQL Server 错误日志或系统事件日志中的其他消息可能提供了更详细信息。这是一个威胁数据库完整性的严重错误条件,必须立即纠正。请执行完整的数据库一致性检查(DBCC CHECKDB)。此错误可以由许多因素导致;有关详细信息,请参阅 SQL Server 联机丛书。
消息 5028,级别 16,状态 4,第 1 行 系统无法激活足够的数据库来重建日志。 sss的 DBCC 结果。 CHECKDB 在数据库 'sss' 中发现 0 个分配错误和 0 个一致性错误。 消息 7909,级别 20,状态 1,第 1 行 紧急模式修复失败。您必须从备份中还原。 消息 601,级别 12,状态 3,第 1 行 由于数据移动,无法继续以 NOLOCK 方式扫描。 消息 926,级别 14,状态 1,第 1 行 无法打开数据库 'sss'。恢复操作已将该数据库标记为 SUSPECT。有关详细信息,请参阅 SQL Server 错误日志。 消息 5069,级别 16,状态 1,第 1 行 ALTER DATABASE 语句失败。 消息 5125,级别 24,状态 2,第 1 行 文件 'E:\DataBase\sss.mdf' 似乎已被操作系统截断。其大小应为 3072 KB,但实际大小为 3064 KB。 消息 3414,级别 21,状态 1,第 1 行 恢复期间出 错,导致数据库 'sss' (数据库 ID 8)无法重新启动。请诊断并纠正这些恢复错误,或者从已知的正确备份中还原。如果无法更正错误,或者为意外错误,请与技术支持人员联系。
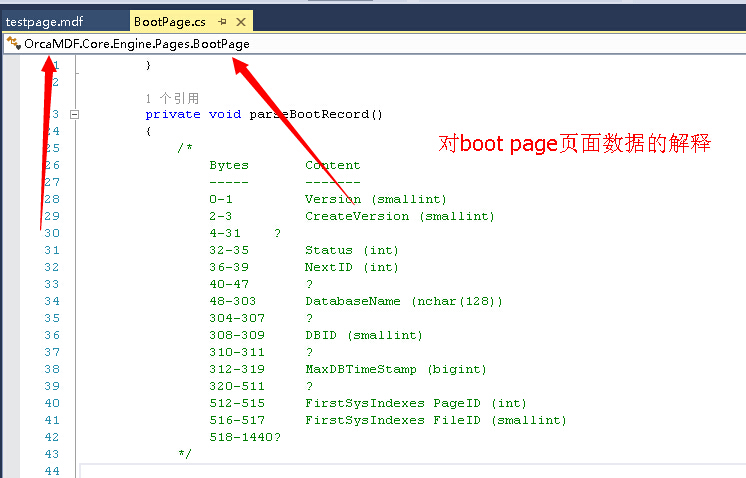
分享某位牛人的代码
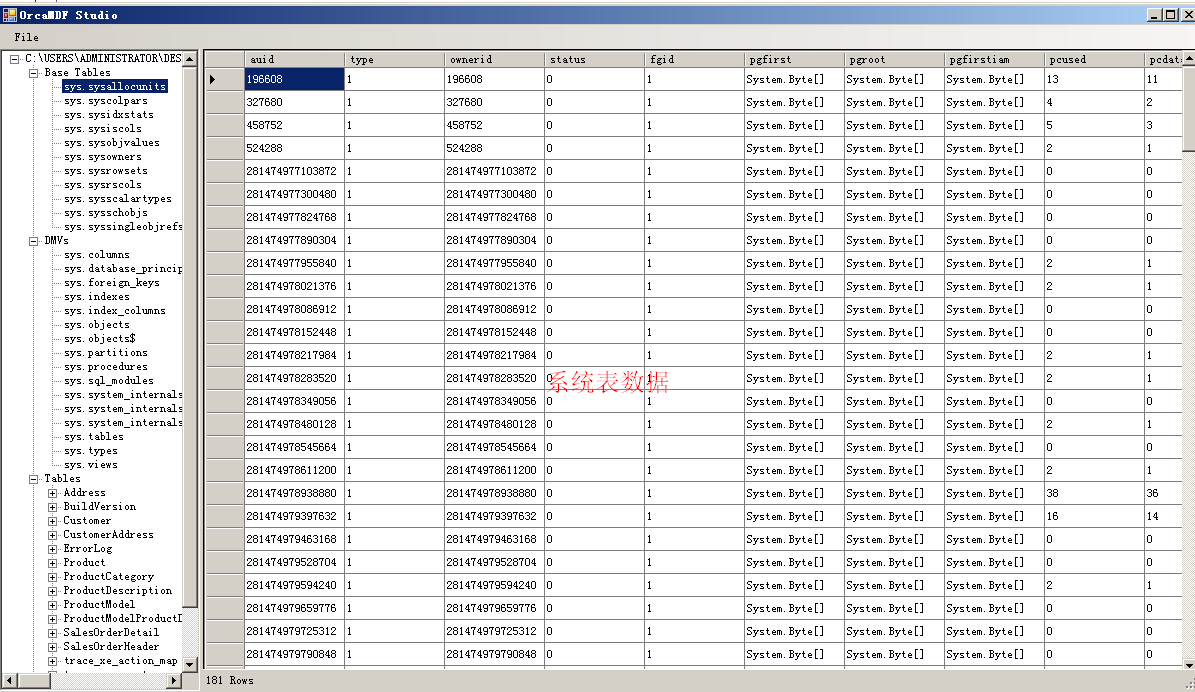
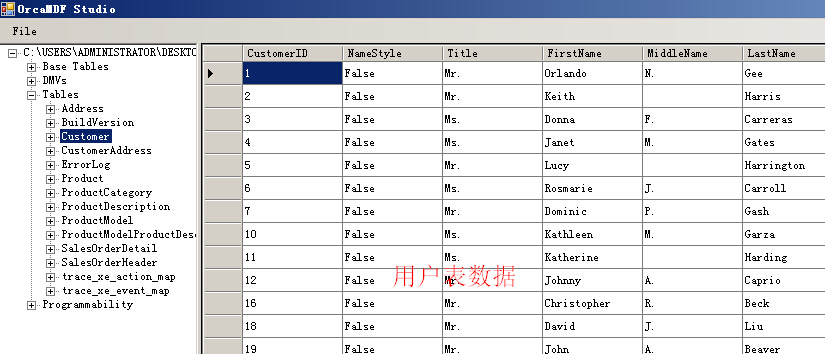
无论系统表、DMV、用户表、系统存储过程、系统视图都可以读取出来
附加到SQLSERVER之后,查看数据库属性,作者使用的是微软的标准示例数据库adventureworkoltp来做的测试

这几个库的版本号是611,655,661,706
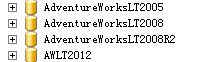
我们可以自己新建一个数据库,然后测试一下
牛人的博客地址:http://improve.dk/
项目代码已经放上去GITHUB:https://github.com/improvedk/OrcaMDF
分享SQLSERVER技术内幕系列图书笔记
本人把一些SQLSERVER技术内幕读书笔记分享出来,其实也不算是分享,因为这些笔记一直躺在我的博客里
大家可以对我做的笔记进行搜索,技术内幕系列图书最大的一个特征是 :Microsoft Press 权威性不可忽视
笔记地址
《Microsoft SQL Server 6.5 技术内幕 笔记》
《Microsoft SQL Server 2005技术内幕:T-SQL查询笔记》
《Microsoft SQL Server 2005技术内幕:存储引擎笔记》
《Microsoft SQL Server 2005技术内幕 查询、调整和优化笔记》
《Microsoft SQL Server 2005技术内幕: T-SQ程序设计 笔记》
《Microsoft SQL Server 2008技术内幕:T-SQL查询 笔记》
《MICROSOFT SQL SERVER 2008技术内幕:T-SQL语言基础 笔记》

EXEC sys.[sp_helpconstraint] @objname = N'[dbo].[nums]', -- nvarchar(776)
@nomsg = '' -- varchar(5)
select object_id, type, name,[parent_object_id] from sys.objects where parent_object_id = OBJECT_ID('customer')
and type in ('C ','PK','UQ','F ', 'D ') -- ONLY 6.5 sysconstraints objects
《SQLSERVER2005存储引擎》
SQLSERVER2005存储引擎里面把cachestore翻译为 存储仓库
还有SQLOS
SQLSERVER的工作线程是映射到Windows的线程池,SQLSERVER每条工作线程内存的分配都是由Windows来分配
SQL2005引入SQLOS,开始由SQLSERVER自己来调度线程,而先前是由Windows来调度
《SQLSERVER2005: T-SQ程序设计》
人们总是说游标性能不好,这本书里面解释了游标实际上也有他的优势的地方
《深入解析SQLSERVER2008 》
DBCC的工作原理解释得很清楚,大部分内容跟《SQLSERVER2005存储引擎》有重叠
在最后一章DBCC 揭秘,译者把鬼影记录翻译为备份记录,搞到一头雾水
一边看书,一边思考
例如这篇文章《大表分批删除脚本》 作者为什么要写 DELETE TOP (5000) 呢? 有可能是5000行锁升级到表锁的原因
还有这一篇文章《恢复SQLSERVER被误删除的数据》
大家看完书本之后,看一下存储过程的代码,自己是否理解里面代码的意思

结尾

解剖SQL Server系列目录
解剖SQLSERVER 第四篇 OrcaMDF里对dates类型数据的解析(译)
解剖SQLSERVER 第五篇 OrcaMDF里读取Bits类型数据(译)
解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions (译)
解剖SQLSERVER 第七篇 OrcaMDF 特性概述(译)
解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
解剖SQLSERVER 第九篇 OrcaMDF现在能通过系统DMVs显示元数据(译)
解剖SQLSERVER 第十篇 OrcaMDF Studio 发布+ 特性重温(译)
解剖SQLSERVER 第十一篇 对SQLSERVER的多个版本进行自动化测试(译)
解剖SQLSERVER 第十二篇 OrcaMDF 行压缩支持(译)
解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译)
解剖SQLSERVER 第十四篇 Vardecimals 存储格式揭秘(译)
解剖SQLSERVER 第十五篇 SQLSERVER存储过程的源文本存放在哪里?(译)
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
解剖SQLSERVER 第十七篇 使用 OrcaMDF Corruptor 故意损坏数据库(译)
解剖SQLSERVER 完结篇 关于Internals Viewer源代码
由于本人精力有限而且E文水平不太好,翻译过程可能有错漏,望大家见谅
建议先看一下技术内幕的书,否则一头栽进代码你会理解不了
通过阅读这些译文大家可能会觉得SQLSERVER的新存储格式比较复杂,要赶上SQLSERVER的步伐不太容易,
改天微软推出一个SQLSERVER补丁包,并在补丁包里面添加新的存储格式你的软件可能又要歇菜了~
而我写这系列文章并不是要与这些数据库恢复软件商作对,而是让大家知道他们能够恢复哪些数据,有哪些数据超出了他们的数据恢复能力
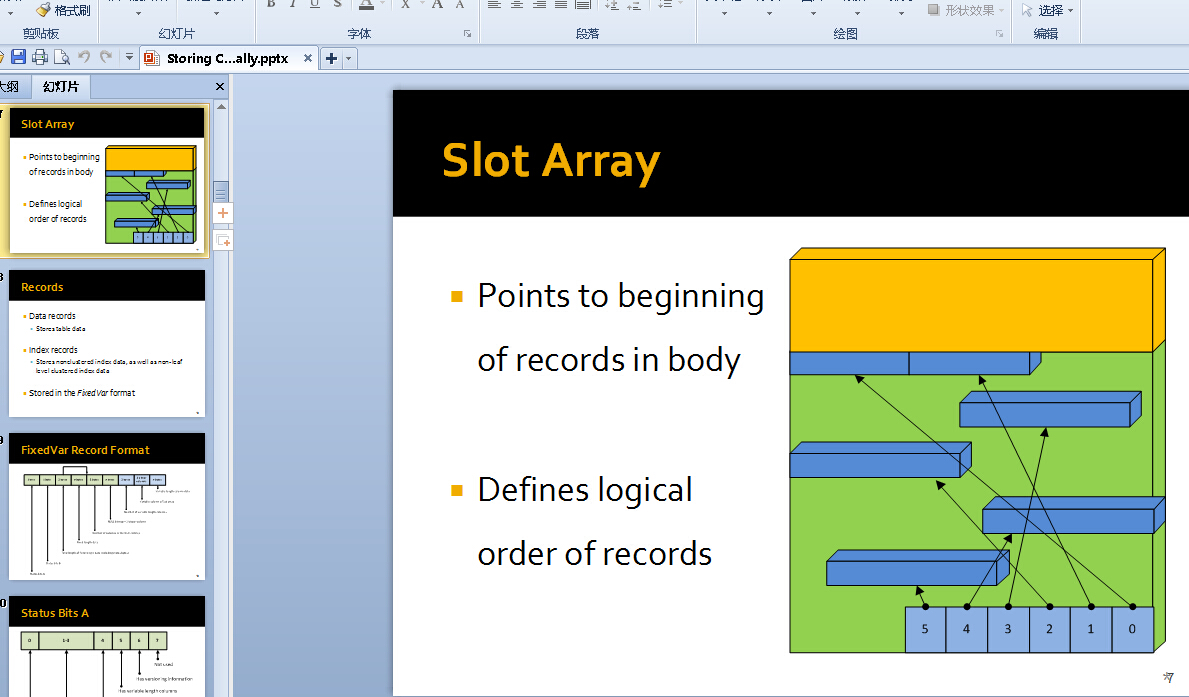
Mark S. Rasmussen的PPT:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号