再说一下表分区
再说一下表分区
网上表分区的文章成千上万,但是分区之后表数据的分布和流向都没有说
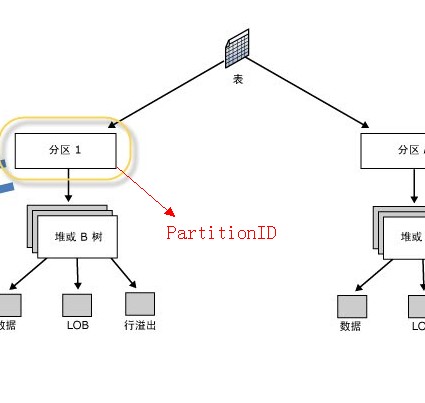
首先要说明的是表分区的分区不是指页面存储概念的分区,我用下面的图来表示
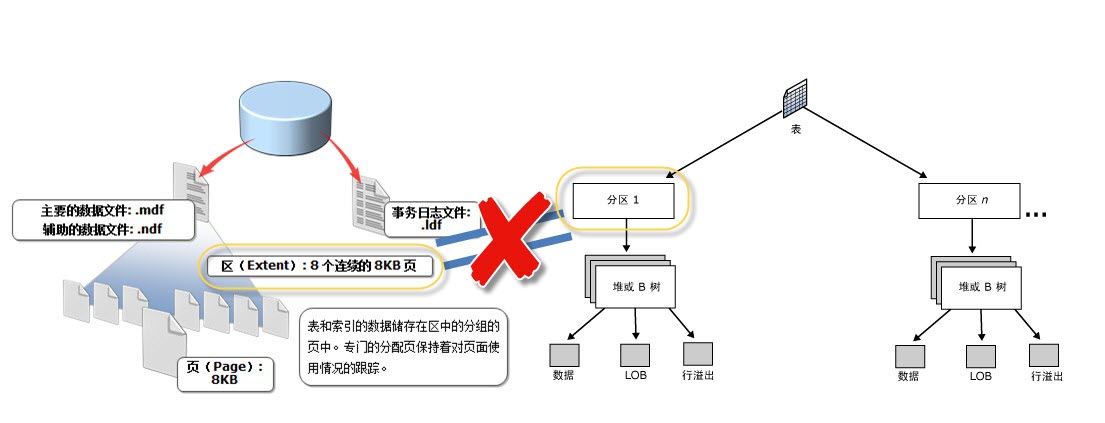
他们是没有关系的
正式开始
SQL脚本如下:
1 USE master 2 GO 3 4 --创建数据库 5 CREATE DATABASE [Test] 6 GO 7 8 USE [Test] 9 GO 10 11 12 --1.创建文件组 13 ALTER DATABASE [Test] 14 ADD FILEGROUP [FG_TestUnique_Id_01] 15 16 ALTER DATABASE [Test] 17 ADD FILEGROUP [FG_TestUnique_Id_02] 18 19 ALTER DATABASE [Test] 20 ADD FILEGROUP [FG_TestUnique_Id_03] 21 22 --2.创建文件 23 ALTER DATABASE [Test] 24 ADD FILE 25 (NAME = N'FG_TestUnique_Id_01_data',FILENAME = N'E:\FG_TestUnique_Id_01_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 26 TO FILEGROUP [FG_TestUnique_Id_01]; 27 28 ALTER DATABASE [Test] 29 ADD FILE 30 (NAME = N'FG_TestUnique_Id_02_data',FILENAME = N'E:\FG_TestUnique_Id_02_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 31 TO FILEGROUP [FG_TestUnique_Id_02]; 32 33 ALTER DATABASE [Test] 34 ADD FILE 35 (NAME = N'FG_TestUnique_Id_03_data',FILENAME = N'E:\FG_TestUnique_Id_03_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 36 TO FILEGROUP [FG_TestUnique_Id_03];
创建分区函数和分区方案
我们创建了一个用于数据类型为int的分区函数,按照数值来划分
文件组 分区 取值范围
[FG_TestUnique_Id_01] 1 (小于2, 2] --包括2
[FG_TestUnique_Id_02] 2 [3, 4]
[FG_TestUnique_Id_03] 3 (4,大于4) --不包括4
1 --3.创建分区函数 2 --我们创建了一个用于数据类型为int的分区函数,按照数值来划分 3 --文件组 分区 取值范围 4 --[FG_TestUnique_Id_01] 1 (小于2, 2]--包括2 5 --[FG_TestUnique_Id_02] 2 [3, 4] 6 --[FG_TestUnique_Id_03] 3 (4,大于4) --不包括4 7 8 CREATE PARTITION FUNCTION 9 Fun_TestUnique_Id(INT) AS 10 RANGE LEFT 11 FOR VALUES(2,4) 12 13 14 15 16 --4.创建分区方案 17 CREATE PARTITION SCHEME 18 Sch_TestUnique_Id AS 19 PARTITION Fun_TestUnique_Id 20 TO([FG_TestUnique_Id_01],[FG_TestUnique_Id_02],[FG_TestUnique_Id_03])
建立分区表
1 --5.创建分区表 2 CREATE TABLE testPartionTable 3 ( 4 id INT NOT NULL, 5 itemno CHAR(20), 6 itemname CHAR(40) 7 )ON Sch_TestUnique_Id([id]) 8 9 10 INSERT INTO [dbo].[testPartionTable] ( [id], [itemno], [itemname] ) 11 SELECT 1,'1','中国' UNION ALL 12 SELECT 2,'2','法国' UNION ALL 13 SELECT 3,'3','美国' UNION ALL 14 SELECT 4,'4','英国' UNION ALL 15 SELECT 5,'5','德国'
查看边界值点
1 --查看边界值点 2 select * from sys.partition_range_values 3 GO

查看表数据
1 SELECT * FROM [dbo].[testNonPartionTable] 2 GO

我们看一下当前数据库的情况
1 EXEC [sys].[sp_helpdb] @dbname = test -- sysname 2 GO

FG_TestUnique_Id_0X这三个文件组建立在三个ndf文件上,三个ndf文件都位于E盘
而fileid分别是3、4、5
我们看一下表的页面分配情况


1 CREATE TABLE DBCCResult ( 2 PageFID NVARCHAR(200), 3 PagePID NVARCHAR(200), 4 IAMFID NVARCHAR(200), 5 IAMPID NVARCHAR(200), 6 ObjectID NVARCHAR(200), 7 IndexID NVARCHAR(200), 8 PartitionNumber NVARCHAR(200), 9 PartitionID NVARCHAR(200), 10 iam_chain_type NVARCHAR(200), 11 PageType NVARCHAR(200), 12 IndexLevel NVARCHAR(200), 13 NextPageFID NVARCHAR(200), 14 NextPagePID NVARCHAR(200), 15 PrevPageFID NVARCHAR(200), 16 PrevPagePID NVARCHAR(200) 17 ) 18 19 --TRUNCATE TABLE [dbo].[DBCCResult] 20 INSERT INTO DBCCResult EXEC ('DBCC IND(test,testPartionTable,-1) ') 21 22 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
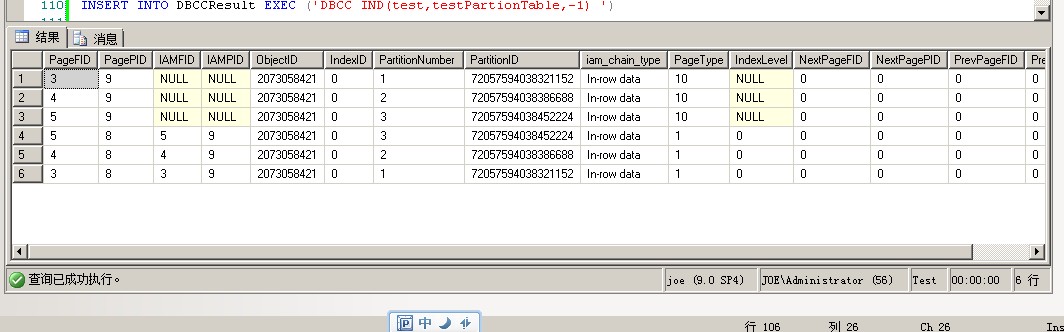
1 SELECT * 2 FROM sys.dm_db_index_physical_stats(DB_ID('test'), 3 OBJECT_ID('testPartionTable'), NULL, 4 NULL, 'detailed')

从上面两个图我们可以得知

-----------------------------------------------------------------------------------------------------------------

-------------------------------------------------------------------------------------------------------------

分区号1~3对应的文件组名和ndf文件名分别是:
分区号1 (PartitionNumber1)-》文件组FG_TestUnique_Id_01-》E:\FG_TestUnique_Id_01_data.ndf
分区号2 (PartitionNumber2)-》文件组FG_TestUnique_Id_02-》E:\FG_TestUnique_Id_02_data.ndf
分区号3 (PartitionNumber3)-》文件组FG_TestUnique_Id_03-》E:\FG_TestUnique_Id_03_data.ndf
表中只有一个数据页面8 和一个IAM页面9
但是每个ndf文件里面却都存储了一份数据页面8 和一份IAM页面9
而且每个ndf文件里面 数据页面存储的内容都不一样,虽然页面编号一样,都是8
数据页面存储的内容
我们来看一下每个ndf文件里面的数据页面都存储了些什么内容?
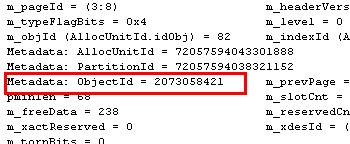
我们先来看一下testPartionTable表的objectID
1 SELECT OBJECT_ID('testPartionTable') AS 'OBJECTID'

先看FILEID为3的文件里面的数据页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,8,3) 4 GO
1 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 2 3 PAGE: (3:8) 4 5 6 BUFFER: 7 8 9 BUF @0x03DFDE90 10 11 bpage = 0x16EEE000 bhash = 0x00000000 bpageno = (3:8) 12 bdbid = 11 breferences = 0 bUse1 = 28337 13 bstat = 0x3c0000b blog = 0x212121bb bnext = 0x00000000 14 15 PAGE HEADER: 16 17 18 Page @0x16EEE000 19 20 m_pageId = (3:8) m_headerVersion = 1 m_type = 1 21 m_typeFlagBits = 0x4 m_level = 0 m_flagBits = 0x8000 22 m_objId (AllocUnitId.idObj) = 82 m_indexId (AllocUnitId.idInd) = 256 23 Metadata: AllocUnitId = 72057594043301888 24 Metadata: PartitionId = 72057594038321152 Metadata: IndexId = 0 25 Metadata: ObjectId = 2073058421 m_prevPage = (0:0) m_nextPage = (0:0) 26 pminlen = 68 m_slotCnt = 2 m_freeCnt = 7950 27 m_freeData = 238 m_reservedCnt = 0 m_lsn = (41:289:25) 28 m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 29 m_tornBits = 0 30 31 Allocation Status 32 33 GAM (3:2) = ALLOCATED SGAM (3:3) = ALLOCATED 34 PFS (3:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (3:6) = CHANGED 35 ML (3:7) = NOT MIN_LOGGED 36 37 Slot 0 Offset 0x60 Length 71 38 39 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 40 Memory Dump @0x0A70C060 41 42 00000000: 10004400 01000000 31202020 20202020 †..D.....1 43 00000010: 20202020 20202020 20202020 d6d0b9fa † .... 44 00000020: 20202020 20202020 20202020 20202020 † 45 00000030: 20202020 20202020 20202020 20202020 † 46 00000040: 20202020 0300f8†††††††††††††††††††††† ... 47 48 Slot 0 Column 0 Offset 0x4 Length 4 49 50 id = 1 51 52 Slot 0 Column 1 Offset 0x8 Length 20 53 54 itemno = 1 55 56 Slot 0 Column 2 Offset 0x1c Length 40 57 58 itemname = 中国 59 60 Slot 1 Offset 0xa7 Length 71 61 62 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 63 Memory Dump @0x0A70C0A7 64 65 00000000: 10004400 02000000 32202020 20202020 †..D.....2 66 00000010: 20202020 20202020 20202020 b7a8b9fa † .... 67 00000020: 20202020 20202020 20202020 20202020 † 68 00000030: 20202020 20202020 20202020 20202020 † 69 00000040: 20202020 0300f8†††††††††††††††††††††† ... 70 71 Slot 1 Column 0 Offset 0x4 Length 4 72 73 id = 2 74 75 Slot 1 Column 1 Offset 0x8 Length 20 76 77 itemno = 2 78 79 Slot 1 Column 2 Offset 0x1c Length 40 80 81 itemname = 法国 82 83 84 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
这个页面是属于testPartionTable表
1 Slot 0 Column 0 Offset 0x4 Length 4 2 3 id = 1 4 5 Slot 0 Column 1 Offset 0x8 Length 20 6 7 itemno = 1 8 9 Slot 0 Column 2 Offset 0x1c Length 40 10 11 itemname = 中国 12 13 Slot 1 Offset 0xa7 Length 71 14 15 16 17 Slot 1 Column 0 Offset 0x4 Length 4 18 19 id = 2 20 21 Slot 1 Column 1 Offset 0x8 Length 20 22 23 itemno = 2 24 25 Slot 1 Column 2 Offset 0x1c Length 40 26 27 itemname = 法国
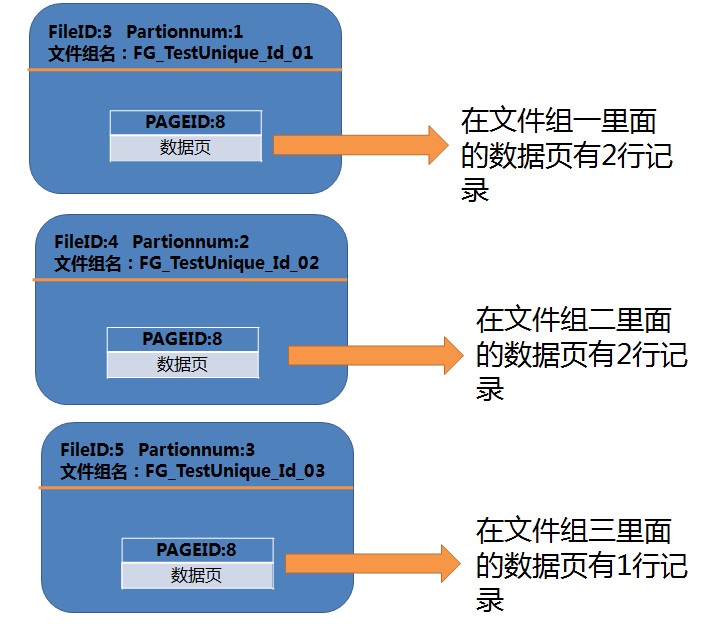
FILEID为3的文件里面的数据页面里存放了id为1和id为2的这两条记录
看FILEID为4的文件里面的数据页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,8,3) 4 GO
1 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 2 3 PAGE: (4:8) 4 5 6 BUFFER: 7 8 9 BUF @0x03E6777C 10 11 bpage = 0x19A78000 bhash = 0x00000000 bpageno = (4:8) 12 bdbid = 11 breferences = 0 bUse1 = 28520 13 bstat = 0x3c0000b blog = 0x212121bb bnext = 0x00000000 14 15 PAGE HEADER: 16 17 18 Page @0x19A78000 19 20 m_pageId = (4:8) m_headerVersion = 1 m_type = 1 21 m_typeFlagBits = 0x4 m_level = 0 m_flagBits = 0x8000 22 m_objId (AllocUnitId.idObj) = 83 m_indexId (AllocUnitId.idInd) = 256 23 Metadata: AllocUnitId = 72057594043367424 24 Metadata: PartitionId = 72057594038386688 Metadata: IndexId = 0 25 Metadata: ObjectId = 2073058421 m_prevPage = (0:0) m_nextPage = (0:0) 26 pminlen = 68 m_slotCnt = 2 m_freeCnt = 7950 27 m_freeData = 238 m_reservedCnt = 0 m_lsn = (41:289:49) 28 m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 29 m_tornBits = 0 30 31 Allocation Status 32 33 GAM (4:2) = ALLOCATED SGAM (4:3) = ALLOCATED 34 PFS (4:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (4:6) = CHANGED 35 ML (4:7) = NOT MIN_LOGGED 36 37 Slot 0 Offset 0x60 Length 71 38 39 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 40 Memory Dump @0x0A37C060 41 42 00000000: 10004400 03000000 33202020 20202020 †..D.....3 43 00000010: 20202020 20202020 20202020 c3c0b9fa † .... 44 00000020: 20202020 20202020 20202020 20202020 † 45 00000030: 20202020 20202020 20202020 20202020 † 46 00000040: 20202020 0300f8†††††††††††††††††††††† ... 47 48 Slot 0 Column 0 Offset 0x4 Length 4 49 50 id = 3 51 52 Slot 0 Column 1 Offset 0x8 Length 20 53 54 itemno = 3 55 56 Slot 0 Column 2 Offset 0x1c Length 40 57 58 itemname = 美国 59 60 Slot 1 Offset 0xa7 Length 71 61 62 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 63 Memory Dump @0x0A37C0A7 64 65 00000000: 10004400 04000000 34202020 20202020 †..D.....4 66 00000010: 20202020 20202020 20202020 d3a2b9fa † .... 67 00000020: 20202020 20202020 20202020 20202020 † 68 00000030: 20202020 20202020 20202020 20202020 † 69 00000040: 20202020 0300f8†††††††††††††††††††††† ... 70 71 Slot 1 Column 0 Offset 0x4 Length 4 72 73 id = 4 74 75 Slot 1 Column 1 Offset 0x8 Length 20 76 77 itemno = 4 78 79 Slot 1 Column 2 Offset 0x1c Length 40 80 81 itemname = 英国 82 83 84 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。

这个页面是属于testPartionTable表
1 Slot 0 Offset 0x60 Length 71 2 3 4 Slot 0 Column 0 Offset 0x4 Length 4 5 6 id = 3 7 8 Slot 0 Column 1 Offset 0x8 Length 20 9 10 itemno = 3 11 12 Slot 0 Column 2 Offset 0x1c Length 40 13 14 itemname = 美国 15 16 Slot 1 Offset 0xa7 Length 71 17 18 19 Slot 1 Column 0 Offset 0x4 Length 4 20 21 id = 4 22 23 Slot 1 Column 1 Offset 0x8 Length 20 24 25 itemno = 4 26 27 Slot 1 Column 2 Offset 0x1c Length 40 28 29 itemname = 英国
FILEID为4的文件里面的数据页面里存放了id为3和id为4的这两条记录
看FILEID为5的文件里面的数据页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,8,3) 4 GO

这个页面是属于testPartionTable表
1 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 2 3 PAGE: (5:8) 4 5 6 BUFFER: 7 8 9 BUF @0x03E7B0FC 10 11 bpage = 0x1A2A8000 bhash = 0x00000000 bpageno = (5:8) 12 bdbid = 11 breferences = 0 bUse1 = 28674 13 bstat = 0x3c0000b blog = 0x212121bb bnext = 0x00000000 14 15 PAGE HEADER: 16 17 18 Page @0x1A2A8000 19 20 m_pageId = (5:8) m_headerVersion = 1 m_type = 1 21 m_typeFlagBits = 0x4 m_level = 0 m_flagBits = 0x8000 22 m_objId (AllocUnitId.idObj) = 84 m_indexId (AllocUnitId.idInd) = 256 23 Metadata: AllocUnitId = 72057594043432960 24 Metadata: PartitionId = 72057594038452224 Metadata: IndexId = 0 25 Metadata: ObjectId = 2073058421 m_prevPage = (0:0) m_nextPage = (0:0) 26 pminlen = 68 m_slotCnt = 1 m_freeCnt = 8023 27 m_freeData = 167 m_reservedCnt = 0 m_lsn = (41:326:23) 28 m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 29 m_tornBits = 0 30 31 Allocation Status 32 33 GAM (5:2) = ALLOCATED SGAM (5:3) = ALLOCATED 34 PFS (5:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (5:6) = CHANGED 35 ML (5:7) = NOT MIN_LOGGED 36 37 Slot 0 Offset 0x60 Length 71 38 39 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 40 Memory Dump @0x0A37C060 41 42 00000000: 10004400 05000000 35202020 20202020 †..D.....5 43 00000010: 20202020 20202020 20202020 b5c2b9fa † .... 44 00000020: 20202020 20202020 20202020 20202020 † 45 00000030: 20202020 20202020 20202020 20202020 † 46 00000040: 20202020 0300f8†††††††††††††††††††††† ... 47 48 Slot 0 Column 0 Offset 0x4 Length 4 49 50 id = 5 51 52 Slot 0 Column 1 Offset 0x8 Length 20 53 54 itemno = 5 55 56 Slot 0 Column 2 Offset 0x1c Length 40 57 58 itemname = 德国 59 60 61 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
1 Slot 0 Offset 0x60 Length 71 2 3 4 Slot 0 Column 0 Offset 0x4 Length 4 5 6 id = 5 7 8 Slot 0 Column 1 Offset 0x8 Length 20 9 10 itemno = 5 11 12 Slot 0 Column 2 Offset 0x1c Length 40 13 14 itemname = 德国
FILEID为5的文件里面的数据页面里存放了id为5这条记录
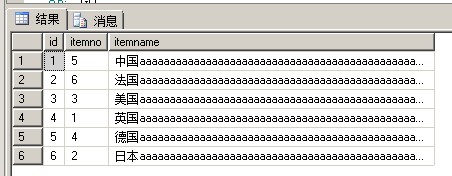
再看我们刚才建立的分区函数,和各个ndf里的数据页面存储的记录条数
1 创建分区函数 2 我们创建了一个用于数据类型为int的分区函数,按照数值来划分 3 文件组 分区 取值范围 4 [FG_TestUnique_Id_01] 1 (小于2, 2]--包括2 5 [FG_TestUnique_Id_02] 2 [3, 4] 6 [FG_TestUnique_Id_03] 3 (4,大于4) --不包括4 7 8 CREATE PARTITION FUNCTION 9 Fun_TestUnique_Id(INT) AS 10 RANGE LEFT 11 FOR VALUES(2,4)
当执行select * from testPartionTable的时候,就需要跨这三个ndf文件来读取记录
IO一定会有所影响,所以一般应用都是按照月份、性别等来进行分区,确保查询数据的时候不要跨多个文件组
如果表没有分区是怎样的?
SQL脚本如下,建立testNonPartionTable表:
1 USE [Test] 2 GO 3 CREATE TABLE testNonPartionTable 4 ( 5 id INT NOT NULL, 6 itemno CHAR(20), 7 itemname CHAR(40) 8 ) 9 10 11 INSERT INTO [dbo].[testNonPartionTable] ( [id], [itemno], [itemname] ) 12 SELECT 1,'1','中国' UNION ALL 13 SELECT 2,'2','法国' UNION ALL 14 SELECT 3,'3','美国' UNION ALL 15 SELECT 4,'4','英国' UNION ALL 16 SELECT 5,'5','德国' 17 18 --TRUNCATE TABLE [dbo].[DBCCResult] 19 INSERT INTO DBCCResult EXEC ('DBCC IND(test,testNonPartionTable,-1) ') 20 21 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,1,47,3) 4 GO
1 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 2 3 PAGE: (1:47) 4 5 6 BUFFER: 7 8 9 BUF @0x03E83C38 10 11 bpage = 0x1763C000 bhash = 0x00000000 bpageno = (1:47) 12 bdbid = 11 breferences = 0 bUse1 = 29165 13 bstat = 0x3c0000b blog = 0xca2159bb bnext = 0x00000000 14 15 PAGE HEADER: 16 17 18 Page @0x1763C000 19 20 m_pageId = (1:47) m_headerVersion = 1 m_type = 1 21 m_typeFlagBits = 0x4 m_level = 0 m_flagBits = 0x8000 22 m_objId (AllocUnitId.idObj) = 86 m_indexId (AllocUnitId.idInd) = 256 23 Metadata: AllocUnitId = 72057594043564032 24 Metadata: PartitionId = 72057594038583296 Metadata: IndexId = 0 25 Metadata: ObjectId = 2105058535 m_prevPage = (0:0) m_nextPage = (0:0) 26 pminlen = 68 m_slotCnt = 5 m_freeCnt = 7731 27 m_freeData = 451 m_reservedCnt = 0 m_lsn = (41:355:23) 28 m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 29 m_tornBits = 0 30 31 Allocation Status 32 33 GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED 34 PFS (1:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (1:6) = CHANGED 35 ML (1:7) = NOT MIN_LOGGED 36 37 Slot 0 Offset 0x60 Length 71 38 39 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 40 Memory Dump @0x0A37C060 41 42 00000000: 10004400 01000000 31202020 20202020 †..D.....1 43 00000010: 20202020 20202020 20202020 d6d0b9fa † .... 44 00000020: 20202020 20202020 20202020 20202020 † 45 00000030: 20202020 20202020 20202020 20202020 † 46 00000040: 20202020 0300f8†††††††††††††††††††††† ... 47 48 Slot 0 Column 0 Offset 0x4 Length 4 49 50 id = 1 51 52 Slot 0 Column 1 Offset 0x8 Length 20 53 54 itemno = 1 55 56 Slot 0 Column 2 Offset 0x1c Length 40 57 58 itemname = 中国 59 60 Slot 1 Offset 0xa7 Length 71 61 62 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 63 Memory Dump @0x0A37C0A7 64 65 00000000: 10004400 02000000 32202020 20202020 †..D.....2 66 00000010: 20202020 20202020 20202020 b7a8b9fa † .... 67 00000020: 20202020 20202020 20202020 20202020 † 68 00000030: 20202020 20202020 20202020 20202020 † 69 00000040: 20202020 0300f8†††††††††††††††††††††† ... 70 71 Slot 1 Column 0 Offset 0x4 Length 4 72 73 id = 2 74 75 Slot 1 Column 1 Offset 0x8 Length 20 76 77 itemno = 2 78 79 Slot 1 Column 2 Offset 0x1c Length 40 80 81 itemname = 法国 82 83 Slot 2 Offset 0xee Length 71 84 85 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 86 Memory Dump @0x0A37C0EE 87 88 00000000: 10004400 03000000 33202020 20202020 †..D.....3 89 00000010: 20202020 20202020 20202020 c3c0b9fa † .... 90 00000020: 20202020 20202020 20202020 20202020 † 91 00000030: 20202020 20202020 20202020 20202020 † 92 00000040: 20202020 0300f8†††††††††††††††††††††† ... 93 94 Slot 2 Column 0 Offset 0x4 Length 4 95 96 id = 3 97 98 Slot 2 Column 1 Offset 0x8 Length 20 99 100 itemno = 3 101 102 Slot 2 Column 2 Offset 0x1c Length 40 103 104 itemname = 美国 105 106 Slot 3 Offset 0x135 Length 71 107 108 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 109 Memory Dump @0x0A37C135 110 111 00000000: 10004400 04000000 34202020 20202020 †..D.....4 112 00000010: 20202020 20202020 20202020 d3a2b9fa † .... 113 00000020: 20202020 20202020 20202020 20202020 † 114 00000030: 20202020 20202020 20202020 20202020 † 115 00000040: 20202020 0300f8†††††††††††††††††††††† ... 116 117 Slot 3 Column 0 Offset 0x4 Length 4 118 119 id = 4 120 121 Slot 3 Column 1 Offset 0x8 Length 20 122 123 itemno = 4 124 125 Slot 3 Column 2 Offset 0x1c Length 40 126 127 itemname = 英国 128 129 Slot 4 Offset 0x17c Length 71 130 131 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP 132 Memory Dump @0x0A37C17C 133 134 00000000: 10004400 05000000 35202020 20202020 †..D.....5 135 00000010: 20202020 20202020 20202020 b5c2b9fa † .... 136 00000020: 20202020 20202020 20202020 20202020 † 137 00000030: 20202020 20202020 20202020 20202020 † 138 00000040: 20202020 0300f8†††††††††††††††††††††† ... 139 140 Slot 4 Column 0 Offset 0x4 Length 4 141 142 id = 5 143 144 Slot 4 Column 1 Offset 0x8 Length 20 145 146 itemno = 5 147 148 Slot 4 Column 2 Offset 0x1c Length 40 149 150 itemname = 德国 151 152 153 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
1 itemname = 中国 2 3 Slot 1 Offset 0xa7 Length 71 4 5 6 Slot 1 Column 0 Offset 0x4 Length 4 7 8 id = 2 9 10 Slot 1 Column 1 Offset 0x8 Length 20 11 12 itemno = 2 13 14 Slot 1 Column 2 Offset 0x1c Length 40 15 16 itemname = 法国 17 18 Slot 2 Offset 0xee Length 71 19 20 21 Slot 2 Column 0 Offset 0x4 Length 4 22 23 id = 3 24 25 Slot 2 Column 1 Offset 0x8 Length 20 26 27 itemno = 3 28 29 Slot 2 Column 2 Offset 0x1c Length 40 30 31 itemname = 美国 32 33 Slot 3 Offset 0x135 Length 71 34 35 36 Slot 3 Column 0 Offset 0x4 Length 4 37 38 id = 4 39 40 Slot 3 Column 1 Offset 0x8 Length 20 41 42 itemno = 4 43 44 Slot 3 Column 2 Offset 0x1c Length 40 45 46 itemname = 英国 47 48 Slot 4 Offset 0x17c Length 71 49 50 51 52 Slot 4 Column 0 Offset 0x4 Length 4 53 54 id = 5 55 56 Slot 4 Column 1 Offset 0x8 Length 20 57 58 itemno = 5 59 60 Slot 4 Column 2 Offset 0x1c Length 40 61 62 itemname = 德国
五条记录都在同一个数据页面
参考文章:
http://www.cnblogs.com/zhijianliutang/archive/2012/10/28/2743722.html
如有不对的地方,欢迎大家拍砖o(∩_∩)o
----------------------------------------------------------------
2013-10-19 晚上补充
我们用Internal Viewer来查看TEST数据库
在Internal Viewer查看到TEST数据库是分区的,十分形象
也能够看到那3个pageid为8的数据页面



我们进入第4个文件的数据页面,即是:E:\FG_TestUnique_Id_02_data.ndf里的数据页面
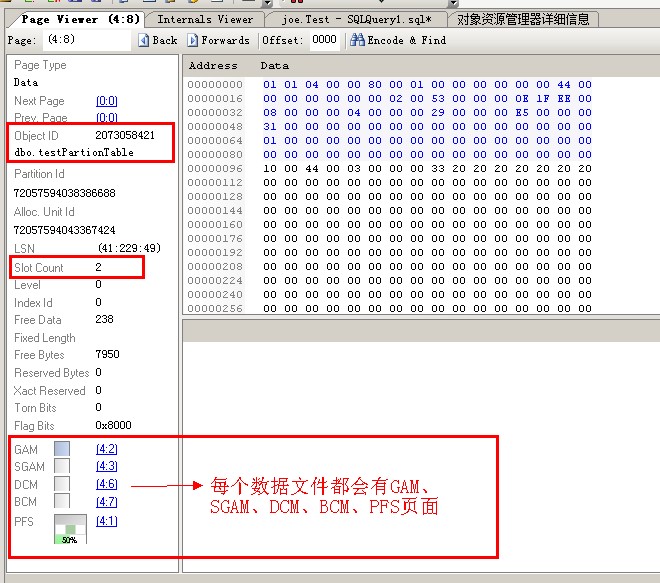
可以看到每个数据文件都会有GAM、SGAM、DCM、BCM、PFS页面
另外的两个数据页面我就不打开来看了
关于GAM、SGAM、DCM、BCM、PFS这些页面的作用可以参考下面文章:
SQL Server 2008 连载之存储结构之DCM、BCM
SQL Server 2008连载之存储结构之GAM、SGAM
关于索引对齐/分区对齐
大家可以先看一下我之前写的文章,看一下数据页面之间是怎麽关联的,先了解一下
SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(下)
MSDN中的解释
索引分区
除了对表的数据集进行分区之外,还可以对索引进行分区。使用相同的函数对表及其索引进行分区通常可以优化性能。
当索引和表按照相同的顺序使用相同的分区函数和列时,表和索引将对齐。如果在已经分区的表中建立索引,
SQL Server 会自动将新索引与该表的分区架构对齐,除非该索引的分区明显不同。当表及其索引对齐后,
SQL Server 则可以更有效地将分区移入和移出分区表,因为所有相关的数据和索引都使用相同的算法进行划分。
如果定义表和索引时不仅使用了相同的分区函数,还使用了相同的分区架构,则这些表和索引将被认为是按存储位置对齐。
按存储位置对齐的一个优点是,相同边界内的所有数据都位于相同的物理磁盘上。在这种情况下,
可以单独在某个时间段内执行备份操作,还可以根据数据的变化在备份频率和备份类型方面改变您的策略。
如果连接或收集了相同文件或文件组中的表和索引,则可以发现更多的好处。SQL Server 可以通过在多个分区中并行操作来获益。
在按存储位置对齐和多 CPU 的情况下,每个处理器都可以直接处理特定的文件或文件组,而不会与数据访问产生任何冲突,
因为所有需要的数据都位于同一个磁盘上。这样,可以并行运行多个进程,而不会相互干扰。
建立索引:是否分区?
默认情况下,分区表中创建的索引也使用相同的分区架构和分区列。
如果属于这种情况,索引将与表对齐。尽管未作要求,但将表与其索引对齐可以使管理工作更容易进行,
对于滑动窗口方案尤其如此。
例如,要创建唯一的索引,分区列必须是一个关键列;这将确保对相应的分区进行验证,以保证索引的唯一性。
因此,如果需要在一列上对表进行分区,而必须在另一个列上创建唯一的索引,这些表和索引将无法对齐。
在这种情况下,可以在唯一的列(如果是多列的唯一键,则可以是任一关键列)中对索引进行分区,或者根本就不进行分区。
请注意,在分区表中移入和移出数据时,必须删除和创建此索引。
注意:如果您打算使用现有数据加载表并立即在其中添加索引,则通常可以通过以下方式获得更好的性能:
先加载到未分区、未建立索引的表中,然后在加载数据后创建分区索引。
通过为分区架构定义群集索引,可以在加载数据后更有效地为表分区。
这也是为现有表分区的不错方法。要创建与未分区表相同的表并创建与已分区群集索引相同的群集索引,
请用一个文件组目标位置替换创建表中的 ON 子句。然后,在加载数据之后为分区架构创建群集索引。
索引对齐,简单来讲,因为索引也可以创建在不同的文件组中,那里创建索引的时候也可以根据
分区架构和分区列来创建索引,这样索引数据和表数据都放在同一个文件组中,叫索引对齐
------------------------------------------------------------------------------
聚集索引表
聚集索引建立在分区列
我们drop掉testPartionTable表,重新建立testPartionTable表
1 --5.创建分区表 2 CREATE TABLE testPartionTable 3 ( 4 id INT NOT NULL, 5 itemname NVARCHAR(4000) 6 )ON Sch_TestUnique_Id([id]) 7 8 9 INSERT INTO [dbo].[testPartionTable] ( [id], [itemname] ) 10 SELECT 1,'中国'+REPLICATE('a',3500) UNION ALL 11 SELECT 2,'法国'+REPLICATE('a',3500) UNION ALL 12 SELECT 3,'美国'+REPLICATE('a',3500) UNION ALL 13 SELECT 4,'英国'+REPLICATE('a',3500) UNION ALL 14 SELECT 5,'德国'+REPLICATE('a',3500) 15 16 SELECT * FROM [dbo].[testPartionTable] 17 GO 18 19 --查看边界值点 20 select * from sys.partition_range_values 21 GO
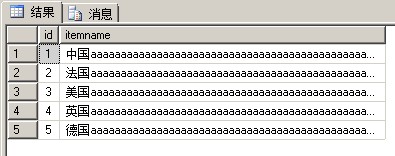
这个表有一个特点:就是一条记录占用一个数据页面
创建聚集索引,聚集索引字段创建在分区字段id上
1 --创建聚集索引 2 CREATE CLUSTERED INDEX cix_id ON testPartionTable(id ASC)
我们看一下,创建聚集索引之后,表的页面的分配情况
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 INSERT INTO DBCCResult EXEC ('DBCC IND(test,testPartionTable,-1) ') 3 4 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

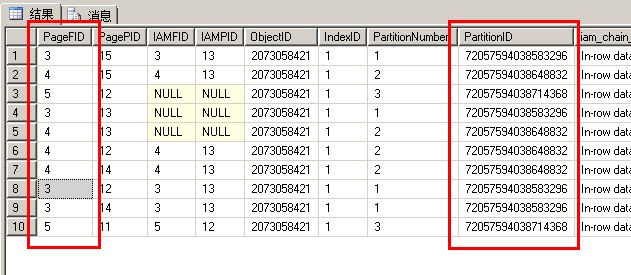
上图中,红色框的列都需要注意的
分区号1/fileid3 (PartitionNumber1)-》文件组FG_TestUnique_Id_01-》E:\FG_TestUnique_Id_01_data.ndf
分区号2/fileid4 (PartitionNumber2)-》文件组FG_TestUnique_Id_02-》E:\FG_TestUnique_Id_02_data.ndf
分区号3/fileid5 (PartitionNumber3)-》文件组FG_TestUnique_Id_03-》E:\FG_TestUnique_Id_03_data.ndf
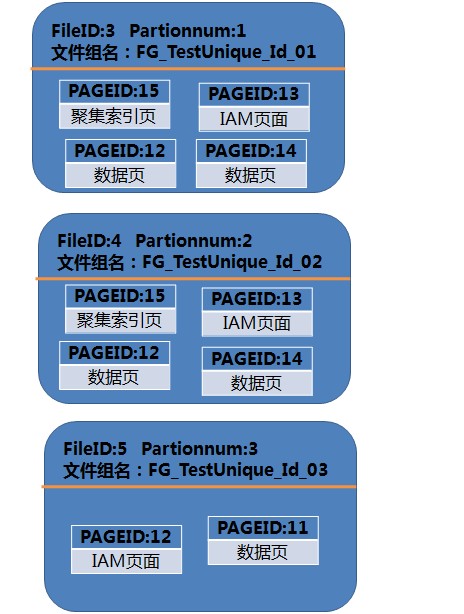
从上图可以得出:
fileid3/分区号1:聚集索引页15,IAM页13,数据页12,数据页14
fileid4/分区号2:聚集索引页15,IAM页13,数据页12,数据页14
fileid5/分区号3:IAM页12,数据页11
fileid PartitionID
fileid3:72057594038583296
fileid4:72057594038648832
fileid5:72057594038714368
PartitionID指的是:表的分区ID,如果一张表没有使用表分区技术,每张表本来默认会有一个分区
如果使用了表分区技术,那么,每个分区都会有一个分区ID(PartitionID)
页面12既是IAM页面也是数据页面
不同的是:一个页面12在fileid5文件里作为IAM页面,另一个页面12在fileid4文件里作为数据页面
可以看到fileid3文件和fileid4文件里的数据页面是首尾相连的,都标记了与那个文件的哪个页面进行相连
唯独fileid5文件里面没有聚集索引页面,可能因为只有一个数据页11,所以没有聚集索引页面
而且也看不到fileid5文件里数据页有首尾相连标记

-------------------------------------------------------------------
----------------------------------------------------------------------
页面指向
文件4里数据页面12-》文件4里数据页面14
文件3里数据页面12-》文件3里数据页面14
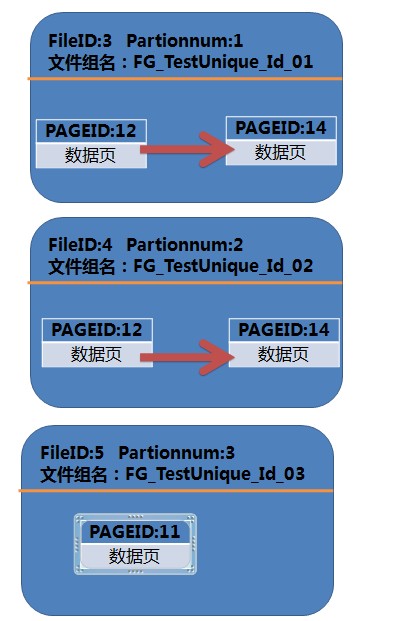
可以看到三个文件组之间或者三个ndf文件之间,数据页面与数据页面之间已经没有联系了,
只有大家都在同一个ndf文件里才能首尾相连,才有联系
我们看一下聚集索引页面
fileid为3的聚集索引页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,15,3) 4 GO

fileid为4的聚集索引页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,15,3) 4 GO

每个文件中的聚集索引页面都各自为政,都只管他自己的文件里的数据页面,而别的文件里的数据页面他是不管的
我们看一下数据页面,这里我只显示有用的信息,数据页面的其他没用信息我都删掉了
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,12,3) 4 GO
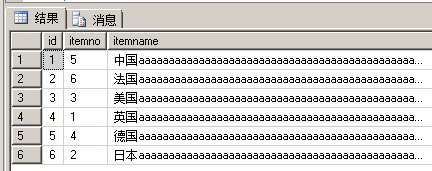
1 PAGE: (3:12) 2 3 4 5 UNIQUIFIER = [NULL] 6 7 Slot 0 Column 1 Offset 0x4 Length 4 8 9 id = 1 10 11 Slot 0 Column 2 Offset 0x11 Length 7004 12 13 itemname = 中国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa 14 15 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,14,3) 4 GO
1 PAGE: (3:14) 2 3 4 5 6 UNIQUIFIER = [NULL] 7 8 Slot 0 Column 1 Offset 0x4 Length 4 9 10 id = 2 11 12 Slot 0 Column 2 Offset 0x11 Length 7004 13 14 itemname = 法国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa 15 16 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,12,3) 4 GO
1 PAGE: (4:12) 2 3 4 5 UNIQUIFIER = [NULL] 6 7 Slot 0 Column 1 Offset 0x4 Length 4 8 9 id = 3 10 11 Slot 0 Column 2 Offset 0x11 Length 7004 12 13 itemname = 美国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa 14 15 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,14,3) 4 GO
1 PAGE: (4:14) 2 3 4 UNIQUIFIER = [NULL] 5 6 Slot 0 Column 1 Offset 0x4 Length 4 7 8 id = 4 9 10 Slot 0 Column 2 Offset 0x11 Length 7004 11 12 itemname = 英国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa 13 14 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,11,3) 4 GO
1 PAGE: (5:11) 2 3 UNIQUIFIER = [NULL] 4 5 Slot 0 Column 1 Offset 0x4 Length 4 6 7 id = 5 8 9 Slot 0 Column 2 Offset 0x11 Length 7004 10 11 itemname = 德国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa 12 13 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
从上面的结果得出:
fileid3:数据页12存放的 id值为1
fileid3:数据页14存放的 id值为2
fileid4:数据页12存放的 id值为3
fileid4:数据页14存放的 id值为4
fileid5:数据页11存放的 id值为5
fileid3/分区号1:id值为1和2
fileid4/分区号2:id值为3和4
fileid5/分区号3:id值为5
按照了分区函数来分
1 --我们创建了一个用于数据类型为int的分区函数,按照数值来划分 2 --文件组 分区 取值范围 3 --[FG_TestUnique_Id_01] 1 (小于2, 2]--包括2 4 --[FG_TestUnique_Id_02] 2 [3, 4] 5 --[FG_TestUnique_Id_03] 3 (4,大于4) --不包括4 6 7 CREATE PARTITION FUNCTION 8 Fun_TestUnique_Id(INT) AS 9 RANGE LEFT 10 FOR VALUES(2,4)
而且聚集索引页面保存的id值也是按照分区函数来分的
fileid3/分区号1:id值为1和2
fileid4/分区号2:id值为3和4
那么这时候可以说聚集索引和数据都按照分区函数来划分,是索引对齐的
-----------------------------------------------------------------------------------------------------
聚集索引建立在非分区列
我们drop掉testPartionTable表,重新建立testPartionTable表
1 CREATE TABLE testPartionTable 2 ( 3 id INT NOT NULL, 4 itemno CHAR(20), 5 itemname NVARCHAR(4000) 6 )ON Sch_TestUnique_Id([id]) 7 8 9 10 11 12 INSERT INTO [dbo].[testPartionTable] ( [id],[itemno], [itemname] ) 13 SELECT 1,'5','中国'+REPLICATE('a',3500) UNION ALL 14 SELECT 2,'6','法国'+REPLICATE('a',3500) UNION ALL 15 SELECT 3,'3','美国'+REPLICATE('a',3500) UNION ALL 16 SELECT 4,'1','英国'+REPLICATE('a',3500) UNION ALL 17 SELECT 5,'4','德国'+REPLICATE('a',3500) UNION ALL 18 SELECT 6,'2','日本'+REPLICATE('a',3500) 19 20 SELECT * FROM [dbo].[testPartionTable] 21 GO 22 23 --查看边界值点 24 select * from sys.partition_range_values 25 GO
创建聚集索引之前testPartionTable表页面分配情况

这次我们将聚集索引创建在非分区字段itemno上
1 --创建聚集索引 2 CREATE CLUSTERED INDEX cix_id ON testPartionTable([itemno] ASC) 3 GO
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 INSERT INTO DBCCResult EXEC ('DBCC IND(test,testPartionTable,-1) ') 3 4 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

建立聚集索引之后,页面会重新分配
这个在SQLSERVER聚集索引与非聚集索引的再次研究(下)里已经讲过了
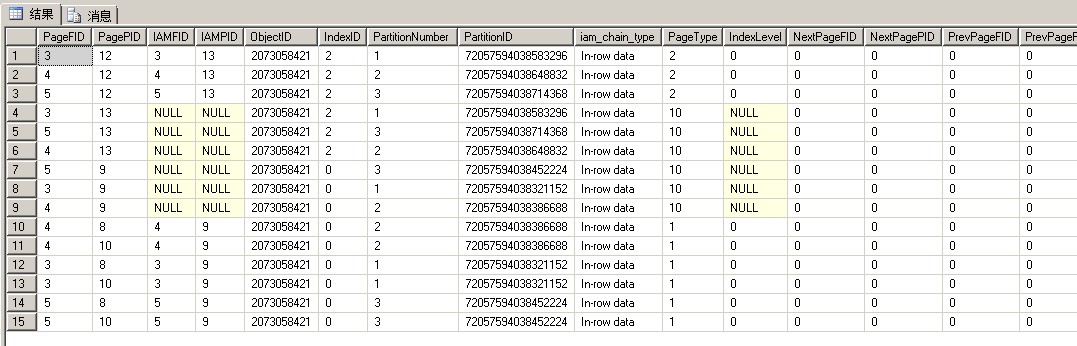
从上图可以得出:
fileid3/分区号1:聚集索引页23,IAM页21,数据页20,数据页22
fileid4/分区号2:聚集索引页23,IAM页21,数据页20,数据页22
fileid5/分区号3:聚集索引页23,IAM页21,数据页20,数据页22
这里跟刚才不一样的是:多了聚集索引页23
fileid5/分区号3:聚集索引页23,IAM页21,数据页20,数据页22
fileid5/分区号3(刚才):IAM页12,数据页11
而且可以看到fileid5文件里数据页有首尾相连标记
刚才:

现在:

这里可以反映出:一个文件/文件组里的数据页多于一个才会出现聚集索引页面
我们看一下 聚集索引页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,23,3) 4 GO

1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,23,3) 4 GO

1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,23,3) 4 GO


聚集索引页面告诉我们:虽然我们在itemno字段上建立聚集索引,但是SQLSERVER在聚集索引页面里
还是以id为聚集索引键来建立聚集索引,直白一点来说就是SQLSERVER会在id列上建立聚集索引,按照id字段来进行排序
无论你在非分区列的那个列上建立聚集索引,SQLSERVER都只会在分区列上建立聚集索引(可能有点绕口o(∩_∩)o )
1 INSERT INTO [dbo].[testPartionTable] ( [id],[itemno], [itemname] ) 2 SELECT 1,'5','中国'+REPLICATE('a',3500) UNION ALL 3 SELECT 2,'6','法国'+REPLICATE('a',3500) UNION ALL 4 SELECT 3,'3','美国'+REPLICATE('a',3500) UNION ALL 5 SELECT 4,'1','英国'+REPLICATE('a',3500) UNION ALL 6 SELECT 5,'4','德国'+REPLICATE('a',3500) UNION ALL 7 SELECT 6,'2','日本'+REPLICATE('a',3500) 8 9 --创建聚集索引 10 CREATE CLUSTERED INDEX cix_id ON testPartionTable([itemno] ASC) 11 GO
我们看一下数据页面
1 PAGE: (3:20) 2 3 UNIQUIFIER = [NULL] 4 5 Slot 0 Column 1 Offset 0x4 Length 20 6 7 itemno = 5 8 9 Slot 0 Column 2 Offset 0x18 Length 4 10 11 id = 1 12 13 Slot 0 Column 3 Offset 0x25 Length 7004 14 15 itemname = 中国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (3:22) 2 3 UNIQUIFIER = [NULL] 4 5 Slot 0 Column 1 Offset 0x4 Length 20 6 7 itemno = 6 8 9 Slot 0 Column 2 Offset 0x18 Length 4 10 11 id = 2 12 13 Slot 0 Column 3 Offset 0x25 Length 7004 14 15 itemname = 法国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (4:20) 2 3 UNIQUIFIER = [NULL] 4 5 Slot 0 Column 1 Offset 0x4 Length 20 6 7 itemno = 1 8 9 Slot 0 Column 2 Offset 0x18 Length 4 10 11 id = 4 12 13 Slot 0 Column 3 Offset 0x25 Length 7004 14 15 itemname = 英国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (4:22) 2 3 UNIQUIFIER = [NULL] 4 5 Slot 0 Column 1 Offset 0x4 Length 20 6 7 itemno = 3 8 9 Slot 0 Column 2 Offset 0x18 Length 4 10 11 id = 3 12 13 Slot 0 Column 3 Offset 0x25 Length 7004 14 15 itemname = 美国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (5:20) 2 3 UNIQUIFIER = [NULL] 4 5 Slot 0 Column 1 Offset 0x4 Length 20 6 7 itemno = 2 8 9 Slot 0 Column 2 Offset 0x18 Length 4 10 11 id = 6 12 13 Slot 0 Column 3 Offset 0x25 Length 7004 14 15 itemname = 日本aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (5:22) 2 3 UNIQUIFIER = [NULL] 4 5 Slot 0 Column 1 Offset 0x4 Length 20 6 7 itemno = 4 8 9 Slot 0 Column 2 Offset 0x18 Length 4 10 11 id = 5 12 13 Slot 0 Column 3 Offset 0x25 Length 7004 14 15 itemname = 德国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
注意:我这里为了节省篇幅,将数据页面的内容进行了删减
fileid3/分区号1:id值为1和2
fileid4/分区号2:id值为3和4
fileid5/分区号3:id值为5和6
那么就是说,对于聚集索引表来说,无论聚集索引建立在分区列还是非分区列,都会索引对齐
非聚集索引表
非聚集索引建立在分区列
我们drop掉数据库test,重新建立数据库test
1 USE master 2 GO 3 DROP DATABASE [Test] 4 GO
SQL脚本都跟刚才一样的
1 USE master 2 GO 3 4 --创建数据库 5 CREATE DATABASE [Test] 6 GO 7 8 USE [Test] 9 GO 10 11 12 --1.创建文件组 13 ALTER DATABASE [Test] 14 ADD FILEGROUP [FG_TestUnique_Id_01] 15 16 ALTER DATABASE [Test] 17 ADD FILEGROUP [FG_TestUnique_Id_02] 18 19 ALTER DATABASE [Test] 20 ADD FILEGROUP [FG_TestUnique_Id_03] 21 22 --2.创建文件 23 ALTER DATABASE [Test] 24 ADD FILE 25 (NAME = N'FG_TestUnique_Id_01_data',FILENAME = N'E:\FG_TestUnique_Id_01_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 26 TO FILEGROUP [FG_TestUnique_Id_01]; 27 28 ALTER DATABASE [Test] 29 ADD FILE 30 (NAME = N'FG_TestUnique_Id_02_data',FILENAME = N'E:\FG_TestUnique_Id_02_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 31 TO FILEGROUP [FG_TestUnique_Id_02]; 32 33 ALTER DATABASE [Test] 34 ADD FILE 35 (NAME = N'FG_TestUnique_Id_03_data',FILENAME = N'E:\FG_TestUnique_Id_03_data.ndf',SIZE = 1MB, FILEGROWTH = 1MB ) 36 TO FILEGROUP [FG_TestUnique_Id_03]; 37 38 39 --3.创建分区函数 40 --我们创建了一个用于数据类型为int的分区函数,按照数值来划分 41 --文件组 分区 取值范围 42 --[FG_TestUnique_Id_01] 1 (小于2, 2]--包括2 43 --[FG_TestUnique_Id_02] 2 [3, 4] 44 --[FG_TestUnique_Id_03] 3 (4,大于4) --不包括4 45 46 CREATE PARTITION FUNCTION 47 Fun_TestUnique_Id(INT) AS 48 RANGE LEFT 49 FOR VALUES(2,4) 50 51 52 53 54 --4.创建分区方案 55 CREATE PARTITION SCHEME 56 Sch_TestUnique_Id AS 57 PARTITION Fun_TestUnique_Id 58 TO([FG_TestUnique_Id_01],[FG_TestUnique_Id_02],[FG_TestUnique_Id_03]) 59 60 --5.创建分区表 61 --DROP TABLE testPartionTable 62 CREATE TABLE testPartionTable 63 ( 64 id INT NOT NULL, 65 itemno CHAR(20), 66 itemname NVARCHAR(4000) 67 )ON Sch_TestUnique_Id([id]) 68 69 70 71 72 73 INSERT INTO [dbo].[testPartionTable] ( [id],[itemno], [itemname] ) 74 SELECT 1,'5','中国'+REPLICATE('a',3500) UNION ALL 75 SELECT 2,'6','法国'+REPLICATE('a',3500) UNION ALL 76 SELECT 3,'3','美国'+REPLICATE('a',3500) UNION ALL 77 SELECT 4,'1','英国'+REPLICATE('a',3500) UNION ALL 78 SELECT 5,'4','德国'+REPLICATE('a',3500) UNION ALL 79 SELECT 6,'2','日本'+REPLICATE('a',3500) 80 81 SELECT * FROM [dbo].[testPartionTable] 82 GO 83 84 --查看边界值点 85 select * from sys.partition_range_values 86 GO
1 CREATE TABLE DBCCResult ( 2 PageFID NVARCHAR(200), 3 PagePID NVARCHAR(200), 4 IAMFID NVARCHAR(200), 5 IAMPID NVARCHAR(200), 6 ObjectID NVARCHAR(200), 7 IndexID NVARCHAR(200), 8 PartitionNumber NVARCHAR(200), 9 PartitionID NVARCHAR(200), 10 iam_chain_type NVARCHAR(200), 11 PageType NVARCHAR(200), 12 IndexLevel NVARCHAR(200), 13 NextPageFID NVARCHAR(200), 14 NextPagePID NVARCHAR(200), 15 PrevPageFID NVARCHAR(200), 16 PrevPagePID NVARCHAR(200) 17 ) 18 19 --TRUNCATE TABLE [dbo].[DBCCResult] 20 INSERT INTO DBCCResult EXEC ('DBCC IND(test,testPartionTable,-1) ') 21 22 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
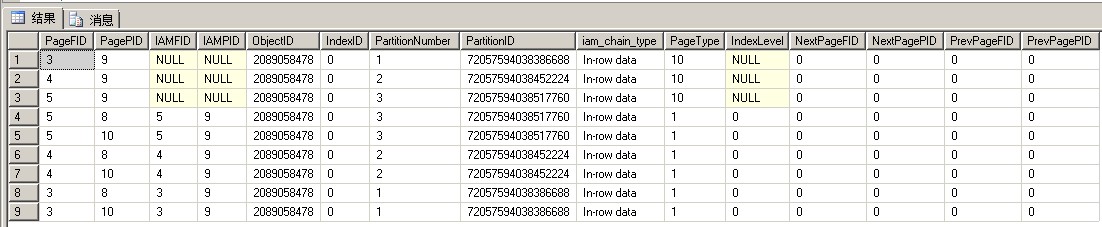
在id字段上建立非聚集索引
1 --创建非聚集索引 2 CREATE INDEX cix_id ON testPartionTable([id] ASC) 3 GO
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 INSERT INTO DBCCResult EXEC ('DBCC IND(test,testPartionTable,-1) ') 3 4 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
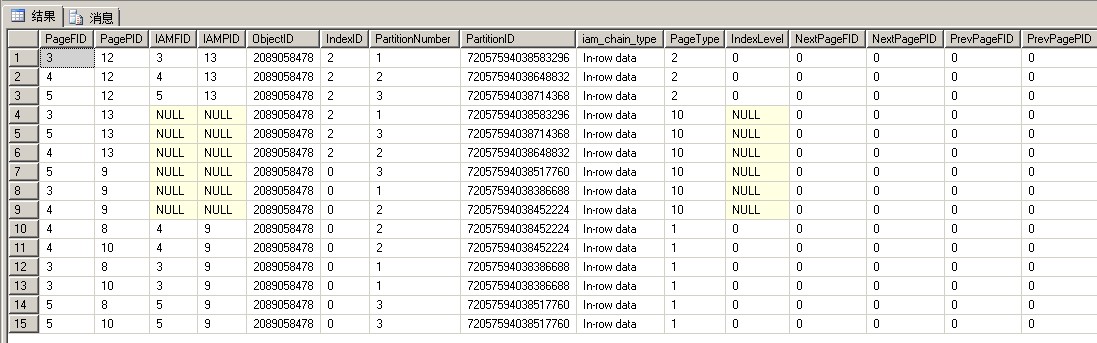
我们比较一下创建非聚集索引之前和之后的图片

-----------------------------------------------------------------------------------------------------------------------
放大左下角的图片
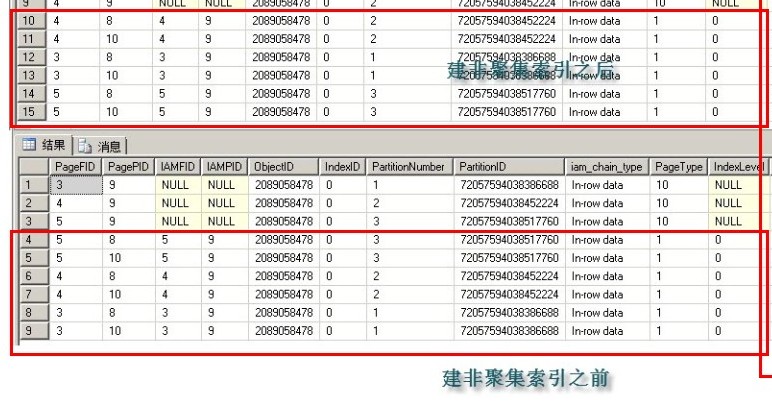
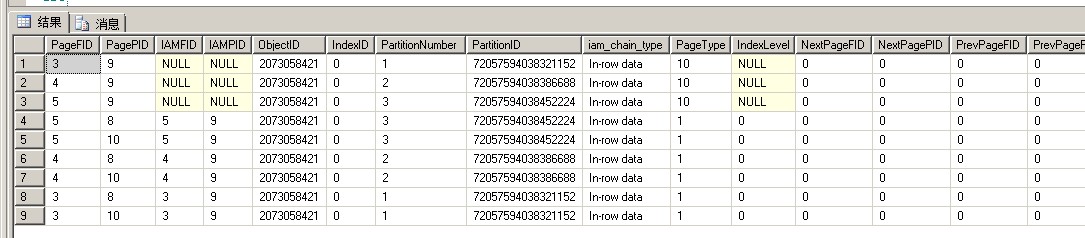
可以看到只是在每个文件fileid3、fileid4、fileid5里新建了非聚集索引页面12和IAM页面13,其他什么都没有改变
fileid3/分区号1:非聚集索引页12,IAM页13,IAM页9,数据页8,数据页10
fileid4/分区号2:非聚集索引页12,IAM页13,IAM页9,数据页8,数据页10
fileid5/分区号3:非聚集索引页12,IAM页13,IAM页9,数据页8,数据页10

----------------------------------------------------------------------------
我们看一下非聚集索引页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,12,3) 4 GO

1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,12,3) 4 GO

1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,12,3) 4 GO
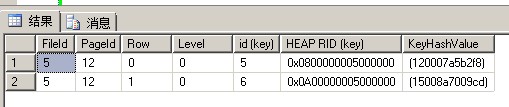
每个文件中的非聚集索引页面都各自为政,都只管他自己的文件里的数据页面,而别的文件里的数据页面他是不管的
这里HEAP RID(key)只会指向本文件里的数据页面,不会指向其他文件的数据页面,因为如果指向其他文件的数据页面的话
那么就不用每个文件都有一个非聚集索引页面12了
我们看一下数据页面,这里我只显示有用的信息,数据页面的其他没用信息我都删掉了
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,8,3) 4 GO
1 PAGE: (3:8) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 1 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 5 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 中国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,10,3) 4 GO
1 PAGE: (3:10) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 2 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 6 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 法国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,8,3) 4 GO
1 PAGE: (4:8) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 3 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 3 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 美国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,10,3) 4 GO
1 PAGE: (4:10) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 4 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 1 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 英国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,8,3) 4 GO
1 PAGE: (5:8) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 5 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 4 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 德国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,10,3) 4 GO
1 PAGE: (5:10) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 6 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 2 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 日本aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
fileid3/分区号1:id值为1和2
fileid4/分区号2:id值为3和4
fileid5/分区号3:id值为5和6

非聚集索引和数据都按照分区函数来划分,是索引对齐的
非聚集索引建立在非分区列
我们drop掉testPartionTable表,重新建立testPartionTable表
1 CREATE TABLE testPartionTable 2 ( 3 id INT NOT NULL, 4 itemno CHAR(20), 5 itemname NVARCHAR(4000) 6 )ON Sch_TestUnique_Id([id]) 7 8 9 10 11 12 INSERT INTO [dbo].[testPartionTable] ( [id],[itemno], [itemname] ) 13 SELECT 1,'5','中国'+REPLICATE('a',3500) UNION ALL 14 SELECT 2,'6','法国'+REPLICATE('a',3500) UNION ALL 15 SELECT 3,'3','美国'+REPLICATE('a',3500) UNION ALL 16 SELECT 4,'1','英国'+REPLICATE('a',3500) UNION ALL 17 SELECT 5,'4','德国'+REPLICATE('a',3500) UNION ALL 18 SELECT 6,'2','日本'+REPLICATE('a',3500) 19 20 SELECT * FROM [dbo].[testPartionTable] 21 GO 22 23 --查看边界值点 24 select * from sys.partition_range_values 25 GO
创建非聚集索引之前testPartionTable表页面分配情况
这次我们将非聚集索引创建在非分区字段itemno上
1 --创建非聚集索引 2 CREATE INDEX ix_id ON testPartionTable([itemno] ASC) 3 GO
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 INSERT INTO DBCCResult EXEC ('DBCC IND(test,testPartionTable,-1) ') 3 4 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
这里跟聚集索引不同,原来的数据页面不会重新分配
从上图可以得出:
fileid3/分区号1:非聚集索引页12,IAM页13,IAM页9,数据页8,数据页10
fileid4/分区号2:非聚集索引页12,IAM页13,IAM页9,数据页8,数据页10
fileid5/分区号3:非聚集索引页12,IAM页13,IAM页9,数据页8,数据页10
我们看一下非聚集索引页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,3,12,3) 4 GO

1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,4,12,3) 4 GO

1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE(test,5,12,3) 4 GO


非聚集索引页面告诉我们:非聚集索引里面会包含分区依据列,但是索引键还是不变还是itemno
我们看一下数据页面
1 PAGE: (3:8) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 1 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 5 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 中国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (3:10) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 2 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 6 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 法国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (4:8) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 3 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 3 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 美国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (4:10) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 4 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 1 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 英国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (5:8) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 5 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 4 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 德国aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
1 PAGE: (5:10) 2 3 Slot 0 Column 0 Offset 0x4 Length 4 4 5 id = 6 6 7 Slot 0 Column 1 Offset 0x8 Length 20 8 9 itemno = 2 10 11 Slot 0 Column 2 Offset 0x23 Length 7004 12 13 itemname = 日本aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
fileid3/分区号1:id值为1和2
fileid4/分区号2:id值为3和4
fileid5/分区号3:id值为5和6
对于非聚集索引表来说,无论非聚集索引建立在分区列还是非分区列,都会索引对齐
补两张图
表分区下的聚集索引
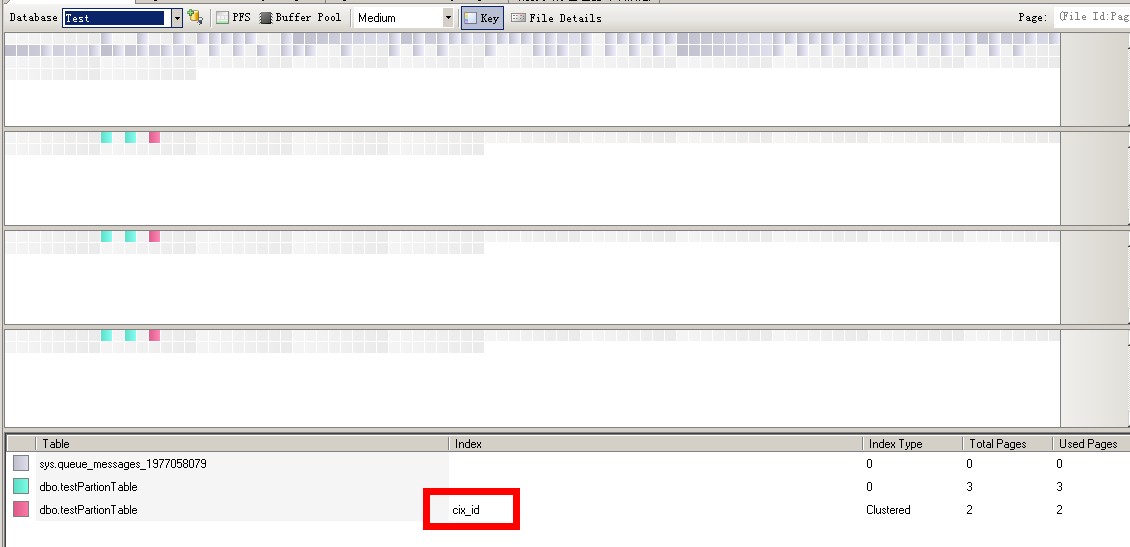
可以看到每个分区都有两个数据页和一个聚集索引页,而主文件组/fileid1里是没有任何表数据的
表分区下的非聚集索引
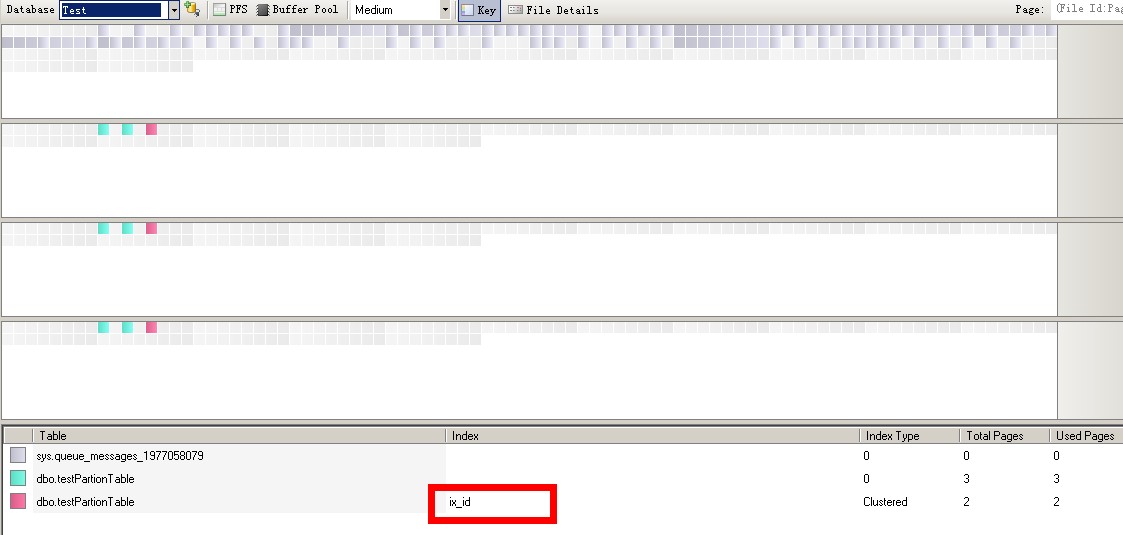
可以看到每个分区都有两个数据页和一个非聚集索引页,而主文件组/fileid1里是没有任何表数据的
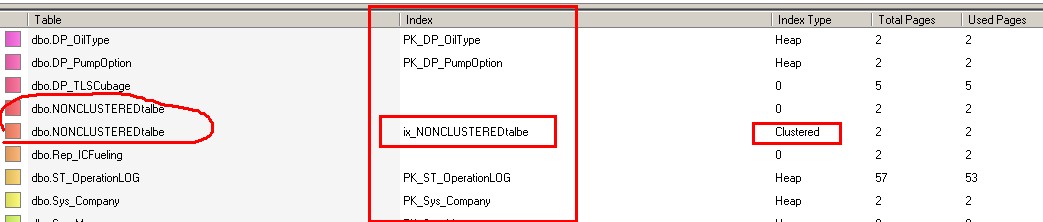
这里不知道是不是Intelnals Viewer的BUG,就算是非聚集索引都会显示为聚集索引
1 USE [GPOSDB] 2 GO 3 CREATE TABLE NONCLUSTEREDtalbe(id int,NAME CHAR(20)) 4 INSERT INTO NONCLUSTEREDtalbe 5 SELECT 1,'nin' UNION ALL 6 SELECT 2,'nin' UNION ALL 7 SELECT 3,'nin' UNION ALL 8 SELECT 4,'nin' 9 10 CREATE NONCLUSTERED INDEX ix_NONCLUSTEREDtalbe ON NONCLUSTEREDtalbe(id ASC)
总结
缺点:这里不但数据分布在多个文件里,连聚集索引页面和非聚集索引页面都分布在多个文件里
如果是聚集索引/非聚集索引查找也需要到多个文件里去查找
因为在表分区了之后多个文件组之间/多个ndf文件之间,数据页面与数据页面之间已经没有联系了
必须到每个ndf文件里的聚集索引页面/非聚集索引页面去查找,直到找到所需的数据为止
所以,在使用表分区的时候一定要做好分区字段的选择,避免select * from 表 不加where 分区字段=
造成的扫描所有分区
无论是索引页还是数据页,将一个页面在每个分区里都保存一份这就是分区,表分区没有什么神秘的o(∩_∩)o
看一下插入和查询的执行计划



 浙公网安备 33010602011771号
浙公网安备 33010602011771号