
[Lua]string(一):string库
参考链接:
http://cloudwu.github.io/lua53doc/manual.html#pdf-string.byte
1.string.gsub
gsub是Global SUBstitution的缩写,即全局替换
返回结果和匹配次数
local str, num = string.gsub("p皮啊b皮啊", "啊", "hi"); print(str);--p皮hib皮hi print(num);--2
2.string.gmatch
gmatch,全局匹配
返回一个迭代器函数
s = "hello啊啊world啊from啊Lua" for w in string.gmatch(s, "啊") do print(w) end -- 啊 -- 啊 -- 啊 -- 啊
3.string.sub
字符串截取,声明为:string.sub (s, i [, j]),表示截取第i到第j个字节的字符串
要注意的是在utf-8中,1个英文占1个字节,1个中文占3个字节,所以截取含中文的字符串可能会有问题
print(string.sub("abcd", 2, 3));--bc print(string.sub("a哈啊皮啊皮", 1, 2));--a�(乱码)
4.string.match
匹配,非全局
返回第一个匹配到的字符串
print(string.match("啊啊皮啊皮哈哈", "皮"));--皮
5.string.len
返回字节数
print(string.len("ab"));--2 print(string.len("a啊b"));--5
6.string.byte
返回指定范围的内部数字编码
print(string.byte("啊", 1, 3));--229 149 138
7.string.find
返回第一个匹配到的字符串的起始和结束位置
print(string.find("啊a皮啊哈", "皮"));--5 7
8.string.pack & string.unpack
参考链接:https://blog.csdn.net/oYuLinZuo/article/details/103800991
对于string.pack的第一个参数,解释如下:

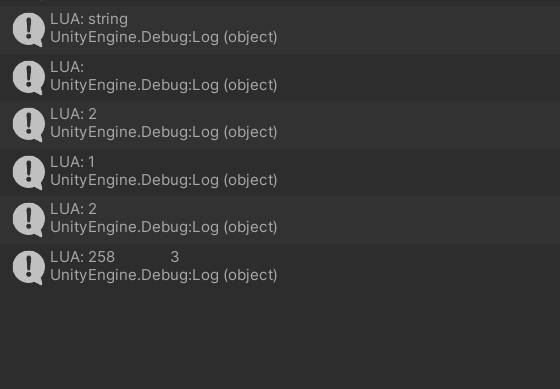
function Test() --258的二进制表示: --00000001 00000010 local str = string.pack(">I2", 258) --大端编码,编码一个2字节长的无符号int print(type(str)) print(str) print(string.len(str)) for i=1,string.len(str) do print(string.byte(str, i)) end print(string.unpack(">I2", str)) end
输出:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号