Oracle基础知识汇总一
以下为本人的学习笔记
oracle工具:
-
SQL * Plus,是安装Oracle数据库服务器或客户端时自动安装的交互式查询工具。 SQL * Plus有一个命令行界面,允许您连接到Oracle数据库服务器并交互执行语句。
-
SQL Developer,是一个用于在Oracle数据库中使用SQL的免费GUI工具。与SQL * Plus程序一样,SQL Developer在安装Oracle数据库服务器或客户端时自动安装。
一、oracle标准创建流程:
-
先创建表空间,创建用户让用户名与此表空间关联;
-
-
最后再赋予登录,增删改权限即可
-
创建表空间---创建用户(关联表空间)---赋予登录权限---赋予增删改权限
语法:
1.创建表空间(管理员操作)
create tablespace 表空间名称 #同java的声明语句一样,说明类型以及名称 datafile ‘存储的路径’ size 10M autoextend on next 10M
-
datafile用于设置物理文件名称
-
size用于设置表空间的初始大小
-
autoextend 用于设置自动增长,如果存储量超过初始大小,则自动扩容
-
next 用于设置扩容的空间大小
2.删除表空间(管理员操作)
注意必须先用语句执行,再手动删除磁盘空间,否则Oracle会崩溃
drop tablespace 表空间名称
3.创建用户(管理员才可以创建用户)
create user 用户名 identified by 密码 default tablespaces 表空间名称
identified by 用于设置用户的密码
default tablespace 用于指定默认表空间名
注意:用户创建成功了,但是缺失某个权限,导致登录失败
login denied 登录拒绝;就是缺失登录权限
4.赋予登录权限
grant connect to 用户名;
当建表时,显示没有操作权限
5.赋予增删改查的权限
grant resource to 用户名
回收权限 * 注意:同级别不能“互相伤害”,就是删除回收平级用户 *
6.赋予收回管理员权限
#给管理员权限 grant dba to 用户名 #回收管理员权限 revoke dba from 用户名;
7、其他流程操作语法
Oracle有几个默认用户
Sys,system,scott
Sys,system是管理员;Scott是普通用户
8、重置普通密码(管理员)
sys as sysdba #作为系统管理员身份登录 alter user 用户名 identified by 密码
9、用户被锁定,解锁
alter user 用户名 account unlock; #account:账户(译)
10、删除用户(管理员)
注意:删除用户时,如果有表则删除失败,因为安全起见;先删除所有表,再删除用户
drop user 用户名 cascade #cascade:大量(译)
登录新账号,使用OT用户帐户连接到数据库(ORCL):
SQL> CONNECT ot@orcl
输入口令:
已连接。
注意,OT用户仅存在于ORCL数据库中,因此,必须在CONNECT命令中明确指定用户名为ot@orcl
Create 表时,当有generated时不能有not null;
要在Oracle数据库中创建一个新表,可以使用CREATE TABLE语句
#11、复制另一个表的所有列 create table new_table as (select * from old_table where id<5000) #12、复制另一个表的选定列 create table new_table as (select column_1,column_2,column3... from old_table where id <5000) #13、从多个表复制选定的列 create table new_table as (select column_1,column_2,...from old_table1,old_table2,...)
实例: create table "regularcustomers"("RCUSTOMER_ID" number(10.0) not null enable, "rcustomer_name" varchar2(50) not null enable, "rc_city" varchar(50)) create table "irregularcustomers"("ircustomer_id" number(10.0) not null enable, "ircustomer_name" varchar2(50) not null enable, "irc_city" varchar2(50)) create table newcustomers3 as (select regularcustomer.rcustomer_id,regularcustomers.rc_city, irregularcustomers.ircustomer_name from regularcustomers,irregularcustomers where regularcustomers.rcustomer_id = i rregularcustomers.ircustomer_id and regularcustomers.rcustomer_id < 5000);
一、修改表结构
要修改现有表的结构,请使用ALTER TABLE语句
alter table table_name action
在上面的语句中,
-
首先,指定要修改的表名称。
-
其次,指出想在表名称后执行的操作。
ALTER TABLE语句可用来:
-
添加一个或多个列
-
修改列定义
-
删除一列或多列
-
重命名列
-
重命名表
1、要将新列添加到表中,请使用以下语法:
ALTER TABLE table_name ADD column_name type constraint; #type:数据类型。 constraint(译:限制):如not null;
1.1、要同时向表中添加多列,请按如下所示将新列置于括号内:
ALTER TABLE table_name ADD ( column_name type constraint, column_name type constraint, ... );
alter table users add (phone number(11) not null,email varchar(14) not null);
注意:不能添加表中已经存在的列; 这样做会导致错误。 另外,ALTER TABLE ADD列语句在表的末尾添加新列。
Oracle没有提供直接的方法来允许您像其他数据库系统(如MySQL)那样指定新列的位置。***
2、要修改列的属性,请使用以下语法:
ALTER TABLE table_name MODIFY column_name type constraint; #modify(译:修改):要与修改值区别开 #例: alter table students modify sbirthday Date null;
2.1、要修改多个列,请使用以下语法
alter table table_name modify(column_1 type constraint,column_2 type constraint,...);
3、要从表中删除现有的列,请使用以下语法:
ALTER TABLE table_name DROP COLUMN column_name; #例: alter table students drop column grade
3.1、要同时删除多个列,请使用以下语法:
ALTER TABLE table_name DROP (column_1,column_2,...); #删除多列时不用在前面添加column关键字 #例: alter table students drop (sname,sage,grade);
4、一个用于重命名列的子句,如下所示:
ALTER TABLE table_name RENAME COLUMN column_name TO new_name; #例: alter table students rename column sname to new_name;
5、要将一个表重命名为一个新的name的表名,使用下面的语法:
ALTER TABLE table_name RENAME TO new_table_name; #例: alter table students rename to persons; member_id NUMBER GENERATED BY DEFAULT AS IDENTITY,
(identity是定义自动加一的列,就像个自动编号。sqlserver裡也有。
這個值有個特點就是不會重複,所以你叫它自動生成的唯一值也可以。
GENERATED BY ALWAYS AS IDENTITY GENERATED BY DEFAULT AS IDENTITY # By always和by default是說明生成這個IDENTITY的方式。 # By always是完全由系統自動生成。 # by default是可以由用戶來指定一個值。) # count(xx)返回xx的记录数
二、删除表
要将表移动到回收站或将其从数据库中完全删除,请使用DROP TABLE语句:
DROP TABLE schema_name.table_name [CASCADE CONSTRAINTS | PURGE]; #cascade(译:大量),purge(译:清除)
-
首先,指出要在DROP TABLE子句之后删除的表及其模式。 -
如果不明确指定模式名称,则该语句假定将从模式中删除该表。
-
其次,指定CASCADE CONSTRAINTS子句删除引用表中主键和唯一键的所有参照完整性约束。 如果存在这种引用完整性约束,并且不使用此子句,Oracle将返回错误并停止删除表。
-
第三,如果想删除表格并且一次释放与之关联的空间,指定PURGE子句。 通过使用PURGE子句,Oracle不会将表及其依赖对象放入回收站
-
请注意,PURGE子句不允许您回滚或恢复删除的表, 因此,如果不希望敏感数据出现在回收站中,这很有用。
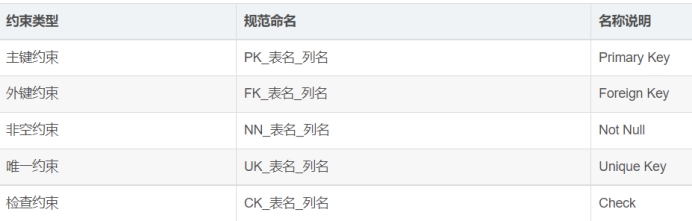
约束(constraint)包含以下五种:
-
NOT NULL (非空)--防止NULL值进入指定的列,在单列基础上定义,默认情况下,ORACLE允许在任何列中有NULL值.
-
CHECK (检查)--检查在约束中指定的条件是否得到了满足
-
UNIQUE (唯一)--保证在指定的列中没有重复值.在该表中每一个值或者每一组值都将是唯一的.
-
PRIMARY KEY (主键)--用来唯一的标识出表的每一行,并且防止出现NULL值,一个表只能有一个主键约束.
-
FOREIGN KEY (外部键)--通过使用公共列在表之间建立一种父子(parent-child)关系,在表上定义的外部键可以指向主键或者其他表的唯一键.
DROP TABLE brands CASCADE CONSTRAINTS;
这个语句不仅删除了brands表,而且还删除了cars表中的外键约束fk_brand。
如果再次执行语句以获取cars表中的外键约束,则不会看到任何返回的行。
三、删除列
Oracle使用SET UNUSED COLUMN子句删除列从大表中删除列的过程可能耗费时间和资源。
因此,通常使用ALTER TABLE SET UNUSED COLUMN语句来逻辑删除列,如下所示:
ALTER TABLE table_name SET UNUSED COLUMN column_name; //unused:未使用的
当执行了该语句,该列就不再可见。在非高峰时段,可以使用以下语句在物理上删除未使用的列:
ALTER TABLE table_name DROP UNUSED COLUMNS; #unused:未使用的
如果要减少累积的撤消日志量,可以使用CHECKPOINT选项,该选项在指定的行数已被处理后强制检查点。
ALTER TABLE table_name DROP UNUSED COLUMNS CHECKPOINT 250;
在sysdba管理员登录下,可以删除表,无法删除表中的列。
四、修改列定义
1、修改列的可见性
默认情况下,表列是可见的。可以在创建表或使用ALTER TABLE MODIFY列语句时定义不可见列。
例如,以下语句使full_name列不可见:
ALTER TABLE accounts MODIFY full_name INVISIBLE; #invisible(译:不可见的)
要将列从不可见变为可见,请使用以下语句:
ALTER TABLE accounts MODIFY full_name VISIBLE; #visible(译:可见的)
2、允许或不允许null示例
以下语句将email列更改为接受非空(not null)值:
ALTER TABLE accounts MODIFY email VARCHAR2( 100 ) NOT NULL;
但是,Oracle发出以下错误:
SQL Error: ORA-02296: cannot enable (OT.) - null values found因为当将列从可为null改为not null时,
必须确保现有数据符合新约束(也就是说,如果原来数据中NULL是不行的)。
为了解决这个问题,首先更新email列的值:
UPDATE accounts SET email = LOWER(first_name || '.' || last_name || '@oraok.com') ;
请注意,LOWER()函数将字符串转换为小写字母。
然后改变email列的约束:
ALTER TABLE accounts MODIFY email VARCHAR2( 100 ) NOT NULL;
现在,它应该就会按预期那样工作了。
-
修改虚拟列假设按以下两列的格式填写全名:
#last_name, first_name #为此,可以更改虚拟列full_name的表达式,如下所示: ALTER TABLE accounts MODIFY full_name VARCHAR2(52) GENERATED ALWAYS AS (last_name || ', ' || first_name); #generated always as :系统自动生成 alter table students modify email generated always as ('ss'||'s');
-
修改列的默认值添加一个名为status的新列,默认值为1到accounts表中。参考以下语句 -
ALTER TABLE accounts ADD status NUMBER( 1, 0 ) DEFAULT 1 NOT NULL ; #当执行了该语句,就会将accounts表中的所有现有行的status列中的值设置为1。 #要将status列的默认值更改为0,请使用以下语句: ALTER TABLE accounts MODIFY status DEFAULT 0; #status列默认值已经设置为0 ,后面添加的新列,status也为0 # 例: alter table students modify sage default 0 not null
五、截断表
如果要从表中删除所有数据,可以使用不带WHERE子句的DELETE语句,如下所示:
DELETE FROM table_name;
对于有少量行记录的表,DELETE语句做得很好。 但是,当拥有大量行记录的表时,使用DELETE语句删除所有数据效率并不高。
Oracle引入了TRUNCATE TABLE语句,用于删除大表中的所有行。
以下说明了Oracle TRUNCATE TABLE语句的语法:
TRUNCATE TABLE schema_name.table_name #truncate(译:截断的) [CASCADE] [[ PRESERVE | PURGE] MATERIALIZED VIEW LOG ]] #perserve(译:坚持)materialized (译:具体的)materialized view log(译:物化视图日志) [[ DROP | REUSE] ]STORAGE ] #reuse(译:重新使用,再次使用)storage(译:存储)
默认情况下,要从表中删除所有行,请指定要在TRUNCATE TABLE子句中截断的表的名称:
TRUNCATE TABLE table_name;
在这种情况下,因为我们没有明确指定模式名称,所以Oracle假定从当前的模式中截断表。如果表通过外键约束与其他表有关系,则需要使用CASCADE子句:
TRUNCATE TABLE table_name CASCADE;
在这种情况下,TRUNCATE TABLE CASCADE语句删除table_name表中的所有行,并递归地截断链中的关联表。
请注意,TRUNCATE TABLE CASCADE语句需要使用ON DELETE CASCADE子句定义的外键约束才能工作。
通过MATERIALIZED VIEW LOG子句,可以指定在表上定义的物化视图日志是否在截断表时被保留或清除。 默认情况下,物化视图日志被保留。
STORAGE子句允许选择删除或重新使用由截断行和关联索引(如果有的话)释放的存储。 默认情况下,存储被删除。
请注意,要截断表,它必须在您自己的模式中,或者必须具有DROP ANY TABLE系统权限。
六、重命名表
RENAME table_name TO new_name;
在RENAME表语句中:
首先,指定将要重命名的表名称。
其次,指定新的表名。新名称不能与同一模式中的另一个表相同。
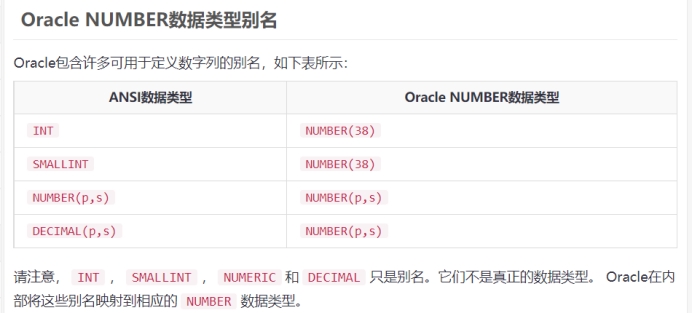
七、Number 类型
Oracle NUMBER数据类型用于存储可能为负值或正值的数值。以下说明了NUMBER数据类型的语法:
NUMBER[(precision [, scale])] #precision(译:精确) scale(译:规模)
NUMBER数据类型具有以下精度和尺度。
-
精度是一个数字中的位数(包含整数的个数,以及小数的个数)。 范围从1到38。
-
尺度是数字中小数点右侧的位数。 范围从-84到127
例如,数字1234.56的精度是6,尺度是2。所以要存储这个数字,需要定义为:NUMBER(6,2)。
要定义一个整数,可以使用下面的形式:
NUMBER(p)Oracle允许规模为负数,例如,下面的数字将数值四舍五入到数百。
NUMBER(5,-2)请注意,如果在NUMBER(p,s)列中插入数字,并且数字超过精度p,则Oracle将发出错误。
但是,如果数量超过尺度s,则Oracle将对该值进行四舍五入。
#number(10,1) #number(3) create table number_name(num numeric(7,2)); #不用为num设置type ,numeric已经包含是number类型了 insert into students (sage) values (22);
* 注意:插入语句只插一个列,一个值时,也要使用括号,并且关键字要用values而不是value *
八、float数据类型
以下显示FLOAT数据类型的语法:
FLOAT(p)
我们只能指定FLOAT数据类型的精度。不能指定尺度,因为Oracle数据库从数据中解析尺度的。 FLOAT的最大精度是126。
九、char数据类型
Oracle CHAR数据类型用于存储固定长度的字符串。 CHAR数据类型可以存储1到2000字节的字符串。
DUMP(x)函数来返回x列详细信息:
LENGTHB(x)函数来获取x列使用的字节数
RTRIM()函数从CHAR数据中去除空格
十、nchar数据类型
Oracle NCHAR数据类型概述Oracle NCHAR数据类型用于存储固定长度的Unicode字符数据。
NCHAR的字符集只能是AL16UTF16或UTF8,在数据库创建时指定为国家字符集。
NCHAR与CHAR比较/区别
-
首先,NCHAR的最大长度只在字符长度语义上,而CHAR的最大长度可以是字符长度或字节长度语义。
-
其次,NCHAR将字符存储在国家默认字符集中,而CHAR将字符存储在默认字符集中。
十一、varchar2数据类型
存储可变长度的字符串,可以使用Oracle VARCHAR2数据类型。 VARCHAR2列可以存储1到4000字节的值。 这意味着对于单字节字符集,最多可以在VARCHAR2列中存储4000个字符。
十二、nvarchar2数据类型
NVARCHAR2是可以存储Unicode字符的Unicode数据类型。 NVARCHAR2的字符集是在数据库创建时指定的国家字符集。
VARCHAR2与NVARCHAR2区别
-
首先,VARCHAR2的最大大小可以是字节或字符,而NVARCHAR2的最大大小只能是字符。 另外,NVARCHAR2的最大字节长度取决于配置的国家字符集。
-
其次,VARCHAR2列只能将字符存储在默认字符集中,而NVARCHAR2则可以存储几乎任何字符
十三、Date数据类型
#Tips:给一个Date数据类型的列赋值,用insert语句, #如: insert into num_name(date_name) values (Date’2017-11-12’); #使用CURRENT_DATE函数的结果指定值 #如: insert into num_name(date_name) values(current_date);
DATE数据类型允许以一秒的精度存储包括日期和时间的时间点值。DATE数据类型存储年份(包括世纪),月份,日期,小时数,分钟数和秒数。
它的范围从公元前4712年1月1日到公元9999年12月31日(共同时代)。 默认情况下,如果未明确使用BCE,则Oracle使用CE日期条目。
Oracle数据库有其自己的专用格式来存储日期数据。它使用7个字节的固定长度的字段,每个字段对应于世纪,年,月,日,时,分和秒来存储日期数据。
-
Oracle日期格式输入和输出的标准日期格式是DD-MON-YY,(年-月-日)
#例如由NLS_DATE_FORMAT参数的值表示为:01-JAN-17。 #以下语句通过使用SYSDATE函数以标准日期格式返回当前日期。 SELECT sysdate FROM dual; #dual是虚拟表
假设想要将标准日期格式更改为YYYY-MM-DD,那么可以使用ALTER SESSION语句来更改NLS_DATE_FORMAT参数的值,如下所示:
ALTER SESSION SET NLS_DATE_FORMAT = 'YYYY-MM-DD';
-
使用TO_CHAR()函数格式化日期TO_CHAR()函数采用DATE值作为参数,根据指定的格式对其进行格式化,并返回一个日期字符串。
#例如,要以特定的格式显示当前的系统日期,请按如下所示使用TO_CHAR()函数: SELECT TO_CHAR( SYSDATE, 'MM/DD/YYYY' ) FROM dual;
3.如果要将当前语言更改为另一个语言(例如FRENCH),请使用ALTER SESSION语句:
ALTER SESSION SET NLS_DATE_LANGUAGE = 'FRENCH'; -- alter session set nls_language='SIMPLIFIED CHINESE
4.以下示例使用TO_DATE()函数将字符串“August 01,2017”转换为相应的日期:
-- alter session set nls_language='SIMPLIFIED CHINESE'; SELECT TO_DATE('2018-10-21', 'YYYY-MM-DD' ) FROM dual;
十四、Oracle TIMESTAMP数据类型
TIMESTAMP数据类型用于存储日期和时间数据,包括年,月,日,时,分和秒。
另外,它存储小数秒,它不是由DATE数据类型存储的。
要定义TIMESTAMP列,请使用以下语法:
column_name TIMESTAMP[(fractional_seconds_precision)] //fractional(译:分数的),precision(译:精确))
fractional_seconds_precision指定SECOND字段小数部分的位数。它的范围从0到9,这意味着可以使用TIMESTAMP数据类型来存储到纳秒的精度。如果省略fractional_seconds_precision,则默认为6。
以下表达式说明了如何定义TIMESTAMP列:
... started_at TMESTAMP(2)
十五、interval数据类型
Oracle提供了两种日期时间数据类型:DATE和TIMESTAMP用于存储时间点数据。另外,它提供INTERVAL数据类型用于存储一段时间。
有两种类型的INTERVAL: //interval(译:间隔)
INTERVAL YEAR TO MONTH # 间隔使用年份和月份。 INTERVAL DAY TO SECOND # 使用包括小数秒在内的天,小时,分钟和秒存储间隔。
十六、插入数据
要将新行插入到表中,请按如下方式使用Oracle INSERT语句:
INSERT INTO table_name (column_1, column_2, column_3, ... column_n) VALUES( value_1, value_2, value_3, ..., value_n); #例: insert into students(sid,sname,sage,grade) values(1,'zhangfei',12,'A');
如果值列表与表列具有相同的顺序,则可以跳过不指定列的列表,但这不被认为是一种好的做法:
INSERT INTO table_name VALUES (value_1, value_2, value_3, ..., value_n);
十七、选择插入语句
insert into select语句概述
有时候,想要将从其它表中选择数据并将其插入到另一个表中。要做到这一点,可使用Oracle INSERT INTO SELECT语句,如下所示:
INSERT INTO target_table (col1, col2, col3) SELECT col1, col2, col3 FROM source_table WHERE condition; #选择一条记录插入(所以要有where条件确定某一条记录) insert into students(sname,sage,) select name,age from persons where id =1;
-
插入所有销售数据示例
#(没有where子句限制插入数据的多少,插入所有数据) #先创建sales表 CREATE TABLE sales ( customer_id NUMBER, product_id NUMBER, order_date DATE NOT NULL, total NUMBER(9,2) DEFAULT 0 NOT NULL, PRIMARY KEY(customer_id, product_id, order_date) ); #以下语句将orders和order_items表中的销售摘要插入到sales表中,参考以下实现语句 insert into sales (customer_id,product_id,order_date,total) select customer_id, product_id, order_date, sum(quantity * unit_price) amount from orders inner join order_items using(order_id) where status = 'Shipped' group by customer_id, product_id, order_date;
十八、插入多行到多表
-
无条件的Oracle INSERT ALL语句将多行插入到表中,要将多行插入到表中,请使用以下Oracle INSERT ALL语句:
INSERT ALL INTO table_name(col1,col2,col3) VALUES(val1,val2, val3) INTO table_name(col1,col2,col3) VALUES(val4,val5, val6) INTO table_name(col1,col2,col3) VALUES(val7,val8, val9) Subquery; #subquery(译:子查询)
在这个语句中,每个值表达式值:val1,val2或val3必须引用由子查询
insert all into table_1(sid,sname) values(1,'ss') into table_2(sid,sname) values(2,'dd') into table_3(sid,sname) values(3,'cc') select 1 from dual; # 返回一条记录即可
Oracle中的截取字符串函数。
#语法如下: substr( string, start_position, [ length ] ) # 参数分析: string # 字符串值 start_position # 截取字符串的初始位置, Number型,start_position为负数时,表示从字符串右边数起。 length # 截取位数,Number型 # 其中,length为可选,如果length为空(即不填)则返回start_position后面的所有字符。 # 意思就是: # 从start_position开始,取出length个字符并返回取出的字符串。 #示例: select * from user_tables where substr(table_name, -6, 6)<='202012';
exec是sqlplus的命令,只能在sqlplus中使用。
call是sql命令,任何工具都可以使用,call必须有括号,即例没有参数
call必须有括号,即例没有参数
十九、排序
要对数据进行排序,请按如下方式将ORDER BY子句添加到SELECT语句中,参考以下语法:
SELECT column_1, column_2, column_3, ... FROM table_name ORDER BY column_1 [ASC | DESC] [NULLS FIRST | NULLS LAST], column_1 [ASC | DESC] [NULLS FIRST | NULLS LAST],
要按列排序结果集,可以在ORDER BY子句之后列出该列。
按照列名是一个排序顺序,可以是:
ASC表示按升序排序DESC表示按降序排序
默认情况下,无论是否指定ASC,ORDER BY子句都按升序对行进行排序。如果要按降序对行进行排序,请明确使用DESC。
NULLS FIRST在非NULL值之前放置NULL值,NULLS LAST在非NULL值之后放置NULL值。
ORDER BY子句可以按多列对数据进行排序,每列可能有不同的排序顺序。
请注意,ORDER BY子句总是SELECT语句中的最后一个子句。
select * from users order by sid desc |asc nulls first|nulls last sname desc |asc nulls first|nulls last sage desc |asc nulls first | nulls last grade desc | asc nulls first | nulls last

*Case多语句判断*
#第一种 格式 : 简单Case函数 : #格式说明 case 列名 when 条件值1 then 选择项1 when 条件值2 then 选项2....... else 默认值 end #第二种 格式 :Case搜索函数 #格式说明 case when 列名= 条件值1 then 选择项1 when 列名=条件值2 then 选项2....... else 默认值 end
注意的问题,Case函数只返回第一个符合条件的 值,剩下的Case部分将会被自动忽略。
二十、Distinct子句
再SELECT语句中使用DISTINCT子句来过滤结果集中的重复行。它确保在SELECT子句中返回指定的一列或多列的值是唯一的。
以下说明了SELECT DISTINCT语句的语法:
SELECT DISTINCT #distinct(译:不同的) column_1 FROM table_name; #例: select distinct * from table_name;
DISTINCT将NULL值视为重复值。如果使用SELECT DISTINCT语句从具有多个NULL值的列中查询数据,则结果集只包含一个NULL值。
二十一、Where子句
WHERE子句指定SELECT语句返回符合搜索条件的行记录。下面说明了WHERE子句的语法:
SELECT column_1, column_2, ... FROM table_name WHERE search_condition ORDER BY column_1, column_2;
WHERE子句出现在FROM子句之后但在ORDER BY子句之前。在WHERE关键字之后是search_condition - 它定义了返回行记录必须满足的条件。
除了SELECT语句之外,还可以使用DELETE或UPDATE语句中的WHERE子句来指定要更新或删除的行记录。
-
通过使用简单的相等运算符来查询行记录以下示例仅返回名称为“Kingston”的产品:
SELECT product_name, description, list_price, category_id FROM products WHERE product_name = 'Kingston';

#示范: where id = 1 where id != 1 where id <> 1 where id >1 where id <10 where id >= 1 where id <= 1 where name in ('张三','赵六') #等价于name='张三' or name='赵六' where name not in ('张三','赵六') where nums [not] between 1 and 5 #相当于nums>=1并且nums<=5 where name [not] exists (select * from table_name where id =1); #括号里面是子查询,括号是返回true或false,返回true就where条件成立,返回false则反之。 where name is [not] null
Some在此表示满足其中一个的意义,是用or串起来的比较从句。
Any也表示满足其中一个的意义,也是用or串起来的比较从句,区别是any一般用在非“=”的比较关系中,这也很好理解,英文中的否定句中使用any肯定句中使用sone,这一点是一样的。
All则表示满足其其中所有的查询结果的含义,使用and串起来的比较从句。
3. 选择符合某些条件的行要组合条件,可以使用AND,OR和NOT逻辑运算符。
例如,要获取属于类别编号是4且标价大于500的所有主板,请使用以下语句:
SELECT product_name, list_price FROM products WHERE list_price > 500 AND category_id = 4;

二十二、And子句
AND运算符是一个逻辑运算符,它组合了布尔表达式,如果两个表达式都为真,则返回true。 如果其中一个表达式为假,则AND运算符返回false。
AND运算符的语法如下所示:
expression_1 AND expression_2 #注意:expression_1 和expression_2不能是同一列
通常,在SELECT,DELETE和UPDATE语句的WHERE子句中使用AND来形成匹配数据的条件。 另外,在JOIN子句的谓词中使用AND运算符来形成连接条件。
在声明中使用多个逻辑运算符时,Oracle始终首先评估AND运算符。 但是,可以使用括号来更改评估的顺序。
Oracle OR运算符与AND运算符结合使用的示例可以将OR运算符与其他逻辑运算符(如AND和NOT)结合起来,形成一个条件。 例如,以下查询将返回属于客户ID为44并且已取消(Canceled)或挂起(Pending)状态的订单。参考以下查询语句 -
SELECT order_id, customer_id, status, salesman_id, TO_CHAR(order_date, 'YYYY-MM-DD') AS order_date FROM orders WHERE ( status = 'Canceled' OR status = 'Pending') AND customer_id = 44 ORDER BY order_date;
二十三、fetch子句
一些RDBMS(如MySQL和PostgreSQL)使用LIMIT子句来检索查询生成的一部分行记录。
请参阅示例数据库中的产品(products)和库存(inventories)表。两个表的结构和关系如下所示 -
以下查询使用LIMIT子句获得库存量最高的前5个产品:
SELECT product_name, quantity FROM inventories INNER JOIN products USING(product_id) ORDER BY quantity DESC LIMIT 5;
在此示例中,ORDER BY子句按降序对库存数量(quantity)进行排序,LIMIT子句仅返回库存数量最多的前5个产品。
Oracle数据库标准中没有LIMIT子句。 然而,自12c发布以来,它提供了一个类似但更灵活的子句,即行限制子句。
通过使用行限制子句,重写上面的LIMIT子句的查询,如下所示:
SELECT product_name, quantity FROM inventories INNER JOIN products USING(product_id) ORDER BY quantity DESC FETCH NEXT 5 ROWS ONLY; #fetch(译:取来,拿来)
在这个语句中,行限制子句是:
FETCH NEXT 5 ROWS ONLY
与上面使用LIMIT子句的语句类似,行限制子句返回库存量最高的前5个产品
Oracle FETCH子句语法以下说明了行限制子句的语法:
[ OFFSET offset ROWS] #offset(译:抵消) FETCH NEXT [ row_count | percent PERCENT ] ROWS [ ONLY | WITH TIES ] OFFSET子句
OFFSET子句指定在行限制开始之前要跳过行数。OFFSET子句是可选的。 如果跳过它,则偏移量为0,行限制从第一行开始计算。
偏移量必须是一个数字或一个表达式,其值为一个数字。偏移量遵守以下规则:
如果偏移量是负值,则将其视为0。如果偏移量为NULL或大于查询返回的行数,则不返回任何行。如果偏移量包含一个分数,则分数部分被截断。
FETCH子句
FETCH子句指定要返回的行数或百分比。
为了语义清晰的目的,您可以使用关键字ROW而不是ROWS,FIRST而不是NEXT。 例如,以下子句的行为和产生的结果相同:
FETCH NEXT 1 ROWS FETCH FIRST 1 ROW ONLY | WITH TIES选项
仅返回FETCH NEXT(或FIRST)后的行数或行数的百分比。
WITH TIES返回与最后一行相同的排序键。请注意,如果使用WITH TIES,则必须在查询中指定一个ORDER BY子句。如果不这样做,查询将不会返回额外的行。
-
获取前N行记录的示例
FETCH NEXT 5 ROWS ONLY; #order by 后面
2.以下查询使用WITH TIES选项的行限制子句:
FETCH NEXT 10 ROWS WITH TIES;
即使查询请求了10行数据,因为它具有WITH TIES选项,查询还返回了另外两行。 请注意,这两个附加行在quantity列的值与第10行quantity列的值相同。
with ties 填在 only 的位置
-
以百分比限制返回行的示例
以下查询返回库存量最高的前1%的产品:
FETCH FIRST 1 PERCENT ROWS ONLY; # percent(译:百分比)
库存(inventories)表总共有1112行,因此,1112中的1%是11.1,四舍五入为12(行)。
-
OFFSET示例以下查询将跳过库存量最高的前10个产品,并返回接下来的10个产品:
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
注意:这个功能可以用于分页的实现。
二十四、Between子句
expression [not] between low and high
low和hight指定要测试的范围的下限值和上限值。
expression,low和hight的数据类型必须是相同的。
select * from table_name where id between 1 and 5
二十五、Like句
Oracle LIKE运算符的语法如下所示:
expresion [NOT] LIKE pattern [ ESCAPE escape_characters ]
在上面的语法中,expression - 该表达式是一个列名称或一个表达式,要针对该模式(pattern)进行测试。pattern - 该模式是在表达式中搜索的字符串。此模式包含以下通配符:
-
%(百分号)匹配零个或多个字符的任何字符串。
-
_(下划线)匹配任何单个字符。
escape_character - escape_character是出现在通配符前面的字符,用于指定通配符不应被解释为通配符而是常规字符。
escape_character(如果指定)必须是一个字符,并且没有默认值。
-
%通配符的例子
#查找以st开头的,,//‘%’指任意数量的字符 where name like 'st%' #查找以rl结尾的 where name like '%rl'
要执行不区分大小写的匹配,可以使用LOWER()或UPPER()函数,如下所示:
UPPER( last_name ) LIKE 'ST%' LOWER(last_name LIKE 'st%'
2._ 通配符的例子
#以下示例查找名字具有以下模式“Je_i”的联系人的电话号码和电子邮件: # '_'表示单个任意字符 where first_name like 'Je_i'
模式'Je_i'匹配任何以'Je'开头的字符串,然后是一个字符,最后是'i',例如Jeri或Jeni,但不是Jenni。
-
混合通配符字符的例子
可以在模式中混合通配符。例如,以下语句查找名字以J开头,后跟两个字符,然后是任意数量字符的联系人。换句话说,它将匹配以Je开头并且至少有4个字符的任何姓氏(first_name):
-
ESCAPE子句的例子ESCAPE子句允许查找包含一个或多个通配符的字符串。
#例如,表可能包含具有百分比字符的数据,例如折扣值,折旧率。要搜索字符串25%,可以使用ESCAPE子句,如下所示: LIKE '%25!%%' ESCAPE '!' #escape '!' :可以使“!”后面的一个通配符仅作为字符串表示 #如果不使用ESCAPE子句,则Oracle将返回字符串为25的任何行。 where name like '%s!%%' escape '!' where name like '%K!%' escape'!' where name like ..escape'!'
二十六、group by 子句
GROUP BY子句在SELECT语句中用于按行或表达式的值将行组合到分组汇总的行中。GROUP BY子句为每个分组返回一行。
将多行有共同点的数据分为一组
1.distinct和group by区别:
-
二者返回的结果是一样的
-
仅仅从查询的作用角度看:
distinct 和 group by 都可以用来去重
-
不同之处,distinct 是针对要查询的全部字段去重,而 group by 可以针对要查询的全部字段中的部分字段去重,它的作用主要是:获取数据表中以分组字段为依据的其他统计数据。
-
从性能角度看:
两者执行方式不同,distinct主要是对数据两两进行比较,需要遍历整个表。group by分组类似先建立索引再查索引,当数据量较大时,group by速度要优于distinct。
二十七、Having子句
HAVING子句是SELECT语句的可选子句。它用于过滤由GROUP BY子句返回的行分组。 这就是为什么HAVING子句通常与GROUP BY子句一起使用的原因。
请注意,HAVING子句过滤分组的行,而WHERE子句过滤行。这是HAVING和WHERE子句之间的主要区别。
二十八、子查询
子查询是嵌套在另一个语句(如SELECT,INSERT,UPDATE或DELETE)中的SELECT语句。
通常,可以在任何使用表达式的地方使用子查询。
下面是子查询的主要优点:
-
提供一种替代方法来解决查询需要复杂联接和联合的数据。
-
使复杂的查询更具可读性。
-
允许以一种可以隔离每个部分的方式来构建复杂的查询。
二十九、Exists运算符
Oracle Exists运算符是返回true或false的布尔运算符。EXISTS运算符通常与子查询一起使用来测试行的存在。
如果子查询返回任何行,则EXISTS运算符返回true,否则返回false。 另外,当子查询返回第一行,EXISTS操作符终止子查询的处理。
Oracle EXISTS与INEXISTS操作符在子查询返回第一行时停止扫描行,因为它可以确定结果,而IN操作符必须扫描子查询返回的所有行以结束结果。
另外,IN子句不能与NULL值进行任何比较,但EXISTS子句可以将所有值与NULL值进行比较。
三十、Any/Some运算符
Oracle ANY运算符用于将值与子查询返回的值或结果集列表进行比较。下面举例说明ANY运算符与列表或子查询一起使用时的语法:
operator ANY ( v1, v2, v3) operator ANY ( subquery)
在这个语法中:
ANY运算符前面必须有一个运算符,例如:=,!=,>,>=,<,<=。列表或子查询必须用圆括号包围。
ANY运算符是将值与列表进行比较
Oracle将初始条件扩展到列表的所有元素,并使用OR运算符将它们组合,如下所示:
SELECT * FROM table_name WHERE c > ANY ( v1, v2, v3 ); #Oracle将上述查询转换为以下内容: SELECT * FROM table_name WHERE c > v1 OR c > v2 OR c > v3;
在Oracle中,SOME和ANY的行为完全相同,因此它们完全可以互换。
三十一、内连接
#语法: select * from t1 inner join t2 on join_predicate; #predicate(译:谓语,依据)
t1表示主表,
t2表示连接表,
inner join ... on是连接语句,on是指两个表有一个列且列值是共同值,共同值的列名不同就用on
join_predicate是连接的条件,需要两个表中来连接,例:两个表都有相同的ID值。
除ON子句外,还可以使用USING子句指定在连接表时要测试哪些列的相等性。
inner join using (sid,sname,...) #两个表中都有有一个列且列值是共同值,共同值的列名相同就用using
-
INNER JOIN多表连接示例
SELECT * FROM orders INNER JOIN order_items USING(order_id) INNER JOIN customers USING(customer_id) ...
注意:表中数据只有当join_predicate一致时,记录就连接,join_predicate不一致时的记录就不出现
三十二、左连接
以下语句说明连接两个表T1和T2时的LEFT JOIN子句的语法:
SELECT column_list FROM T1 LEFT JOIN T2 ON join_predicate; #左连接以t1作为主表,根据主页查询,没有与主表条件一致的,连接表 #那行记录都为null
注意:表中数据当join_predicate一致时,记录连接数据,join_predicate不一致时的记录,将连接表该行数据都改为null值出现。
三十三、右连接
设有两个表T1和T2,以下语句显示了如何使用Oracle中的RIGHT OUTER JOIN子句连接这两个表:SELECT column_list FROM T1 RIGHT OUTER JOIN T2 ON #右连接以t2作为主表,根据主页查询,没有与主表条件一致的,连接表 join_predicate; #那行记录都为null #在这个语句中,T1和T2分别是左表和右表。 right outer join #outer是可选关键字
注意:表中数据当join_predicate一致时,记录连接数据,join_predicate不一致时的记录,将连接表该行数据都改为null值出现。
三十四、笛卡尔积连接
在数学中,给定两个集合A和B,A x B的笛卡尔乘积是所有有序对(a,b)的集合,属于A,b属于B。
要在Oracle中创建表的笛卡尔乘积,可以使用CROSS JOIN子句。 以下说明了CROSS JOIN子句的语法:
SELECT column_list FROM T1 CROSS JOIN T2;
三十五、All运算符
Oracle ALL操作符用于将值与子查询返回的值列表或结果集进行比较。
以下显示了与列表或子查询一起使用的ALL运算符的语法:
operator ALL ( v1, v2, v3) operator ALL ( subquery)
值与all括号里的列表,即与其所有值一一比较
在这个语法中,
ALL运算符前面必须有一个运算符,例如:=,!=,>,>=,<,<=,后跟一个列表或子查询。列表或子查询必须用圆括号包围。
some/any与all的区别:
-
all是指值与all括号里的列表(即该所有值)一 一比较
-
some/any是指与括号里的列表(即该所有值任意一个值)比较
oracle中 some、any、all 三者的区别
-
select count from nums where id > any(1,5,7) where id = 4; -
id 大于any括号里的任意一个,返回true;some同any用法,,但是any大多用于非的环境里。
-
select count from nums where id >all(1,2,3) where id = 4; -
id 大于all括号里的每一个(所有),返回true
三十六、视图
可以通过创建表的视图来表现数据的逻辑子集或数据的组合。视图是基于表或宁一个视图的逻辑表,
一个视图并不包含它自己的数据,它像一个窗口,通过该窗口可以查看或改变表中的数据。
视图包含查询语句,调用视图查看查询结果集
对视图进行DML操作,实际上是对表进行DML
DML:是指update,insert,delete
1、简单视图:包含一个表,没有函数,没有分组
-
create table table_name as 和create view view_name as 不同,
-
create table table_name as是创建一个新表并存储查询到的数据,
-
create view view_name as,是创建一个视图,但这个视图不会存储数据,查询这个视图时,实际是查询创建视图时的那串查询语句结果
#例: create view view_name as select col1,col2, from table_name;
2、复杂视图:包含两个表及两个表以上,有函数,有分组,这三点满足任何一点就是复杂视图。
#例: create view view_name(name,minsal,maxsal,avgsal) #根据后面select 数据的顺序为view定义别名 as select d.department_name ,max(e.salary),min(e.salary) , avg(e.salary) #对于函数,创建view要为函数加别名max(e.salary) max,avg(e.salary) avg from employees e, departments d where e.department_id = d.department_id #两个表用等值连接 group by d.department_name;
3、视图中DML操作的执行规则
如果视图中包含下面的部分就不能修改数据:
-
组函数
-
GROUP BY子句
-
DISTINCT关键字
-
用表达式定义的列(如,表达式:对某个列进行运算)
4、简单视图拒绝DML操作
create view v_view as select * from table with read only;
5、删除视图
drop view view_name
删除视图不会丢失数据,因为视图是基于数据库中的基本表的。
三十七、内建视图
内建视图是一个带有别名的可以在SQL语句中使用的子查询。
一个主查询的在from子句中指定的子查询就是一个内建视图。
内建视图由位于from子句中命名了别名的子查询创建。该子查询定义一个可以在主查询中引用数据源。
显示那些雇员低于他们部门最高薪水的雇员的名字、薪水、部门号和他们部门最高的薪水:
select em.last_name,em.salary,em.department_id,e.maxsal from employees em, (select e.department_id,max(e.salary) maxsal from employees e group by e.department_id) e #子查询,即内建视图,根据相同
部门号来确认同部门的最高薪水
where em.department_id = e.department_id #子查询用括号包住相当于一个内建视图 and em.salary < e.maxsal;
在Top-N分析里和分页查询会用到内建视图
1、Top-N分析:Top-N查询在需要基于一个条件,从表中显示最前面的n条记录或最后面的n条
记录时是有用的。该结果可以用于进一步分析。Top-N分析包括内建视图和外查询。
Top-N两个字就是-----排名
例如,用Top-N分析你可以执行下面的查询类型:
a.在公司中挣钱最多的三个人
b.在公司中最新的四个成员
c.销售产品最多的两个销售代表
d.过去6个月中销售最好的3种产品
外查询包含:
·rownum伪劣:表中不存在的列,但加了之后会在每一行从1开始返回一个连续序号;
·一个where子句,它指定被返回的n行,外where子句必须用一个<或<=操作
select rownum ,name from table
Top-N示例一:
#从employees表中显示挣钱最多的三个人的名字及薪水: select rownum ,last_name,salary from (select last_name,salary from employees order by salary desc) where rownum <=3;
示例二:
#从company显示公司中4个年龄最老的雇员: select rownum ,c.age ,c.name from (select age,name from company order by age desc) c where rownum <=4;
Top-N内建视图做的是查询排名,外查询的工作是查多少条,显示什么列。
三十八、分页查询

#查询1到10共10条记录 select * from (select rownum rn,e.* from employees e) em where em.rn between 1 and 10 #查询11到20共10条记录 select * from (select rownum rn,e.* from employees e) em where em.rn between 11 and 20 #rownum放到内建视图里,在外查询对rownum判断
参考资料:
■免责申明
⒈ 本站是纯粹个人学习网站,与朋友交流共赏,不存在任何商业目的。
⒉ 本站利用了部分网络资源,版权归原作者及网站所有,如果您对本站所载文章及作品版权的归属存有异议,请立即通知我们,我们将在第一时间予以删除,同时向你表示歉意!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号