并发代码设计
为了提高线程利用率并最小化开销,必须决定要使用的线程数量,并为每个线程合理分配任务
开始处理之前的线程间数据划分
简单算法最容易并行化,比如要并行化 std::for_each,把元素划分到不同的线程上执行即可。如何划分才能获取最优性能,取决于数据结构的细节,这里用一个最简单的划分为例,每 N 个元素分配给一个线程,每个线程不需要与其他线程通信,直到独立完成各自的处理任务
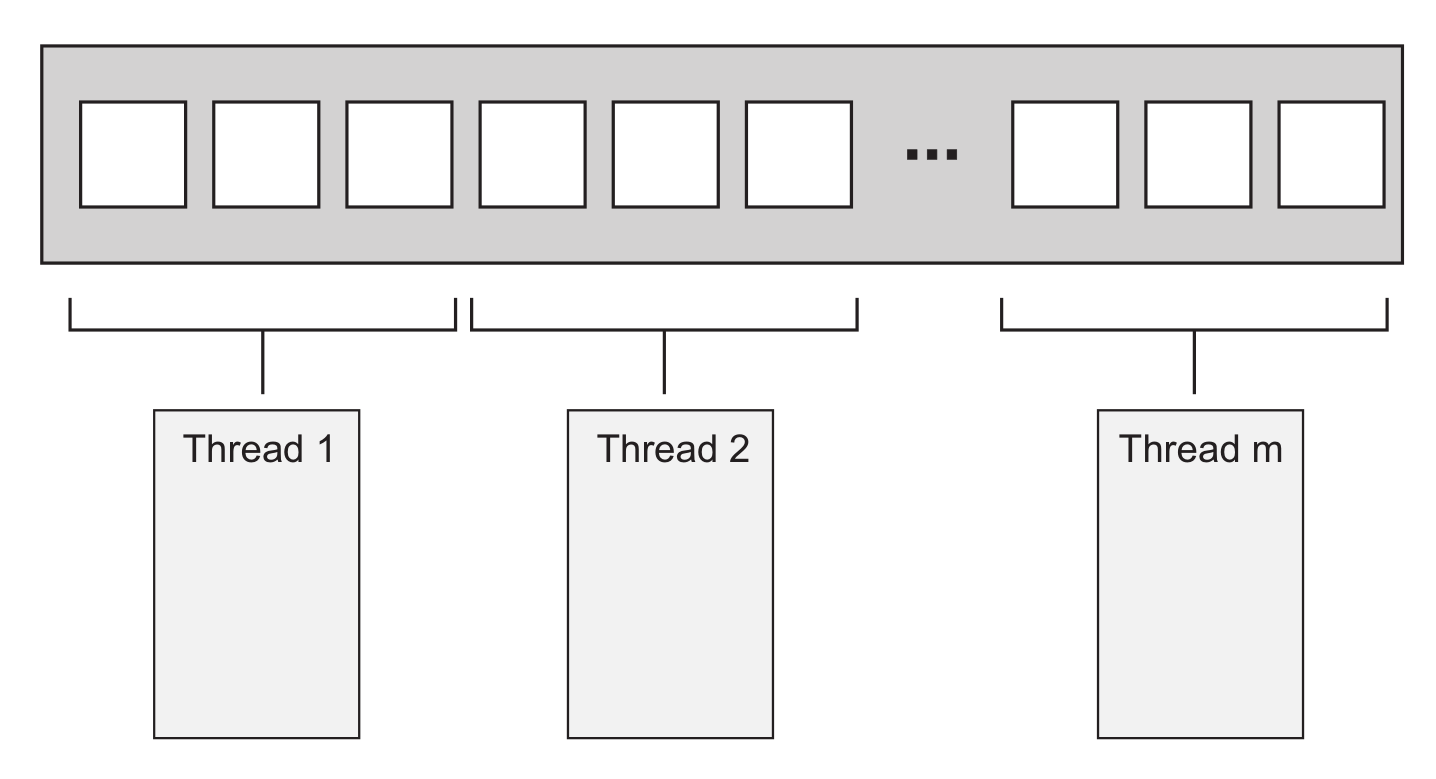
- 如果使用过 MPI 或 OpenMP,会很熟悉这个结构,即把一个任务划分成一系列并行任务,工作线程独立完成任务,最后 reduce 合并结果。不过对 for_each 来说,最后的 reduce 实际不需要执行操作,但对其他需要合并结果的并行算法来说,最后一步很重要
- 尽管这个技术很强大,但不是万能的,有时数据不能灵活划分,只有在处理数据时划分才明显,最能明显体现这点的就是递归算法,比如快速排序
递归划分数据
-
要并行化快速排序,无法直接划分数据,因为只有处理之后才知道某一项应该置于基数的哪一边。因此,很容易想到的是使用递归,其中的递归调用完全独立,各自处理不同的元素集,十分适合并发执行
-
如果数据集很大,为每个递归生成新线程就会生成大量线程,如果线程过多就会影响性能。因此需要严格控制线程数,不过这个问题可以直接抛给 std::async
#include <algorithm>
#include <future>
#include <list>
template <typename T>
std::list<T> parallel_quick_sort(std::list<T> v) {
if (v.empty()) {
return {};
}
std::list<T> res;
res.splice(res.begin(), v, v.begin());
auto it = std::partition(v.begin(), v.end(),
[&](const T& x) { return x < res.front(); });
std::list<T> low;
low.splice(low.end(), v, v.begin(), it);
std::future<std::list<T>> l(
std::async(¶llel_quick_sort<T>, std::move(low)));
auto r(parallel_quick_sort(std::move(v)));
res.splice(res.end(), r);
res.splice(res.begin(), l.get());
return res;
}
基于任务划分
方法1 Soc
如果数据动态生成或来自外部输入,上述划分方式都不适用,此时应该基于任务而非基于数据来划分。一种基于任务的划分方式是让线程针对性处理任务。
每个线程只需要负责完成总任务的某一部分。这就是 SoC(separation of concerns,关注点分离)设计原则
单线程中,如果有多个任务需要执行,只能依次执行任务,任务需要保存完成状态,并周期性地返回控制流给主循环。如果循环中添加了很多任务,就会导致程序变慢,对于一个用户发起的事件可能很久才会响应
这就是使用线程的原因,如果每个任务分离在线程上,保存状态和返回控制流给主循环这些事都抛给了操作系统,此时只需要关注任务本身,并且任务还可以并发运行,这样用户也能及时得到响应
但现实不一定这么顺利。然而,这些后台运行的任务经常需要处理用户请求,因此就需要在完成时更新用户接口,以通知用户。此外,用户还可能想取消任务,这样就需要用户接口发送一条通知后台任务终止的消息。这些情况都要求周全的考虑和设计,以及合适的同步
虽然如此,但关注点仍然是分离的。用户接口线程线程仍处理用户接口,只是可能在被其他线程请求时要更新接口。同理,后台任务线程仍然关注自己的任务,只是允许被其他线程请求终止
多线程不是一定要 SoC,比如线程间有很多共享数据,或者需要互相等待。对于这样存在过多通信的线程,应该先找出通信的原因,如果所有的通信都关联同一个问题,合并成一个单线程来处理可能更好一些
方法2 pipeline
基于任务划分不要求完全隔离,如果多个输入数据集合适用相同顺序的操作,可以把这个操作序列划分为多个子阶段来分配给每个线程,当一个线程完成操作后就把数据放进队列,供下一线程使用,这就是 pipeline。这也是另一种划分数据的方式,适用于操作开始前输入数据不是完全已知的情况,比如来自网络的数据或者扫描文件系统以识别要处理的文件
// 非 pipeline:每 20 秒 4 个数据(每个数据仍要 20 秒)
线程A:-1- -1- -1- -1- -5- -5- -5- -5-
线程B:-2- -2- -2- -2- -6- -6- -6- -6-
线程C:-3- -3- -3- -3- -7- -7- -7- -7-
线程D:-4- -4- -4- -4- -8- -8- -8- -8-
// pipeline:第一个数据 20 秒,之后每个 5 秒
线程A:-1- -2- -3- -4- -5- -6- -7- -8-
线程B:--- -1- -2- -3- -4- -5- -6- -7-
线程C:--- --- -1- -2- -3- -4- -5- -6-
线程D:--- --- --- -1- -2- -3- -4- -5-
以视频解码为例,第一秒达到 120 帧,卡顿 3 秒后播放下一个 120 帧,这样远不如稳定的每秒 30 帧
影响并发代码性能的因素
1.处理器数量
2.乒乓缓存(cache ping-pong)
- 如果两个线程在不同处理器上并发执行,读取同一数据一般不会带来问题,数据将拷贝到它们的 cache,处理器可以同时处理。
- 但如果一个线程修改数据,这个修改传给其他核的 cache 就需要花费时间,从而可能导致第二个处理器停止以等待改变传到内存硬件,从 CPU 指令的角度来看,这个操作慢到惊人,等价于数百个独立指令
n.fetch_add(1, std::memory_order_relaxed)
每次n自增,处理器都要确保 cache 中的拷贝是最新的
修改值后再告知其他处理器
fetch_add 是读改写RMW操作,每次都要检索最新值
如果另一线程在另一处理器运行此代码
n 的数据就要在两个处理器之间来回传递(fetch new -> write new)
这样 n 增加时两个处理器的 cache 才能有最新值
如果有很多处理器运行此代码,处理器就要互相等待
一个处理器在更新值,另一个更新值的处理器就要等待(fetch new)
直到第一个更新完成并把改变传过来
在类似这样的循环中,n 的数据在 cache 之间来回传递, 这就是 cache ping-pong
要避免乒乓缓存,就要尽量减少多个线程对同一内存位置的竞争。但即使一个特定内存位置只能被一个线程访问,仍然可能存在乒乓缓存,原因就是伪共享
3.伪共享(false sharing)
处理器 cache 不是独立的,而是以 cache line 作为最小单位,一般为64B,因此小数据可能位于同一 cache line。有时这是好事,如果一个线程访问的数据都位于同一 cache line,性能会比分散在多个 cache line 好。但如果 cache line 中的数据项不相关,需要被多个线程访问,就会导致性能问题.
假如有一个 int 数组,一组线程频繁访问和更新其中的数据。通常 int 大小不超过一个 cache line,因此一个 cache line 可以存储多个数据项,此时即使每个线程只访问自己需要的数据,cache 硬件也会造成乒乓缓存。比如访问 0 号数据的线程要更新数据,cache line 的所有权就要被转移到运行这个线程的处理器
数据可能不共享,但 cache line 是共享的,这就是伪共享。
这个问题的解决方案是,构造数据,让能被同一线程访问的数据项位于内存中的临近位置(放在一起),让能被不同线程访问的数据在内存中相距很远(例如间隔cacheline大小)。C++17 提供了 std::hardware_destructive_interference_size 来指定当前编译目标伪共享的最大连续字节数,只要数据间隔大于此字节数就可以避免伪共享
OneCacheLiner { // occupies one cache line
std::atomic_uint64_t x{};
std::atomic_uint64_t y{};
} oneCacheLiner;
struct TwoCacheLiner { // occupies two cache lines
alignas(hardware_destructive_interference_size) std::atomic_uint64_t x{};
alignas(hardware_destructive_interference_size) std::atomic_uint64_t y{};
} twoCacheLiner;
// two thread
oneCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
oneCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
// two thread
twoCacheLiner.x.fetch_add(1, std::memory_order_relaxed);
twoCacheLiner.y.fetch_add(1, std::memory_order_relaxed);
OUTPUT
sizeof( OneCacheLiner ) == 64
sizeof( TwoCacheLiner ) == 128
oneCacheLinerThread() spent 634.25 ms
oneCacheLinerThread() spent 651.55 ms
oneCacheLinerThread() spent 990.23 ms
oneCacheLinerThread() spent 1033.94 ms
oneCacheLinerThread() spent 838.14 ms
oneCacheLinerThread() spent 883.25 ms
oneCacheLinerThread() spent 873.02 ms
oneCacheLinerThread() spent 914.26 ms
Average T1 time: 852 ms
twoCacheLinerThread() spent 119.22 ms
twoCacheLinerThread() spent 127.91 ms
twoCacheLinerThread() spent 114.17 ms
twoCacheLinerThread() spent 126.41 ms
twoCacheLinerThread() spent 125.17 ms
twoCacheLinerThread() spent 126.06 ms
twoCacheLinerThread() spent 117.94 ms
twoCacheLinerThread() spent 129.03 ms
Average T2 time: 122 ms
Ratio T1/T2:~ 6.98
建议:
- 调整线程间的数据分布,让同一线程访问的数据尽量紧密
- 尽量减少线程所需的数据量
- 依据 std::hardware_destructive_interference_size,确保不同线程访问的数据距离足够远,以避免伪共享

 浙公网安备 33010602011771号
浙公网安备 33010602011771号