Rocksdb SStable
sstable(sorted string table)是google bigtable中引出的数据结构,在levelDB、RocksDB以及现在各类数据库存储中配合LSM有广泛应用,学习下很有必要,本位以RocksDB中SST的实现来了解SST。
优点
- 空间利用率高:sstable基于sorted string的结构使得他非常适合做压缩,有更好的空间利用率
- 利于合并:key本身是sorted,非常适合采用归并排序来做merge。LSM中利用sstable作为基本存储单元也有这样的考量
存储结构
sstable是sorted string table的缩写,存储结构的设计关键在于sorted string。
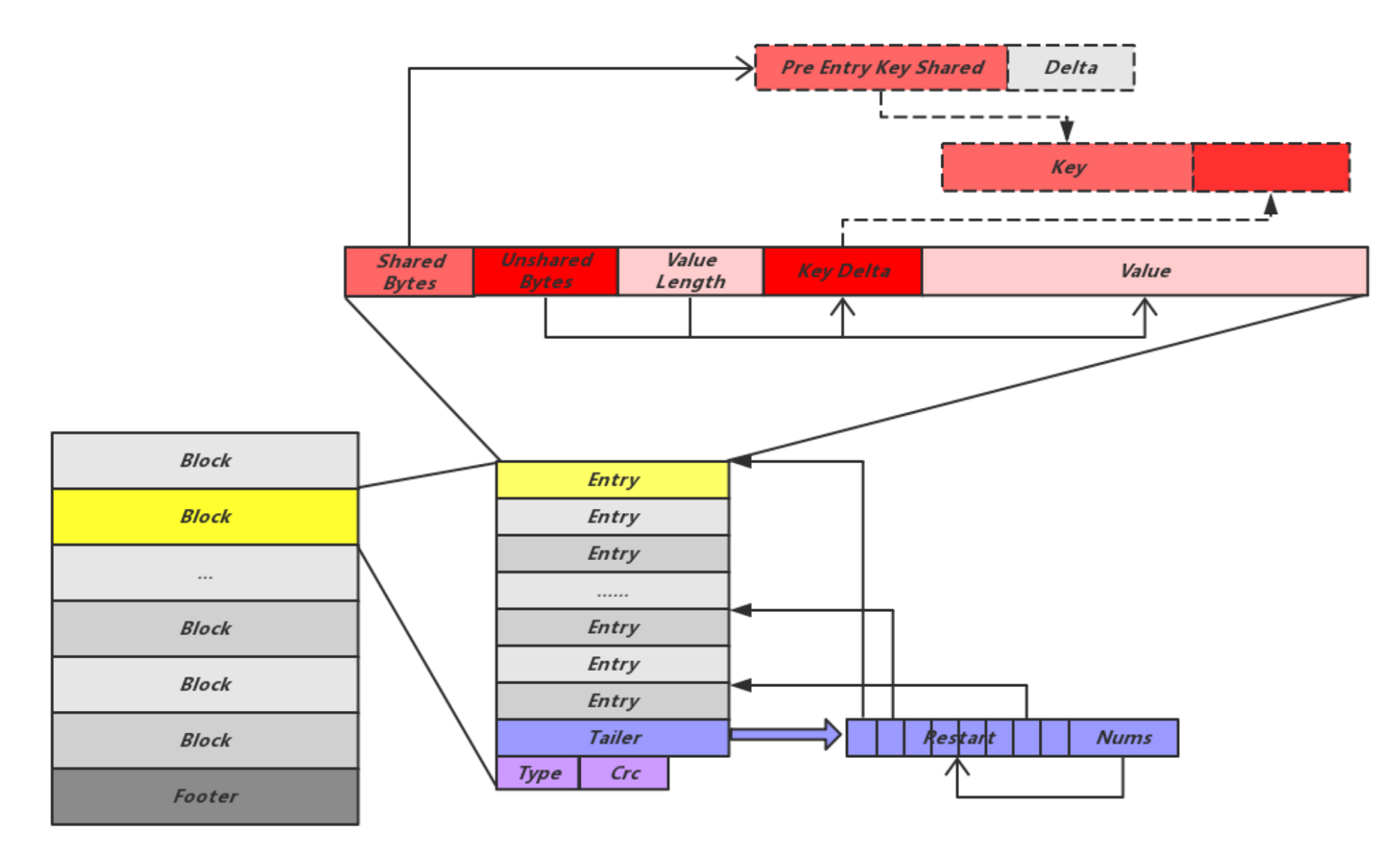
sstable文件内部有多个数据块(block)构成。
一个数据块内多个entry的key是按照字符来排序的,并且充分利用prefix string来减少存储开销。
不过为了避免第一个prefix key导致全部entry损坏,固定entry个数会有一个entry包含完整key信息,这个点称之为restart point。
这个entry的key的shared值重置为0。block结尾的tailer会记录restart point的偏移量信息。
下图来源[1] 展示了SST的基本结构。
Block的定义:
Block 结构是指除了内部的有效数据外,还会有额外的压缩类型字段和校验码字段。
每一个 Block 尾部都会有压缩类型和循环冗余校验码(crcValue),这会要占去 5 字节。压缩算法默认是 snappy ,校验算法是 crc32。
-
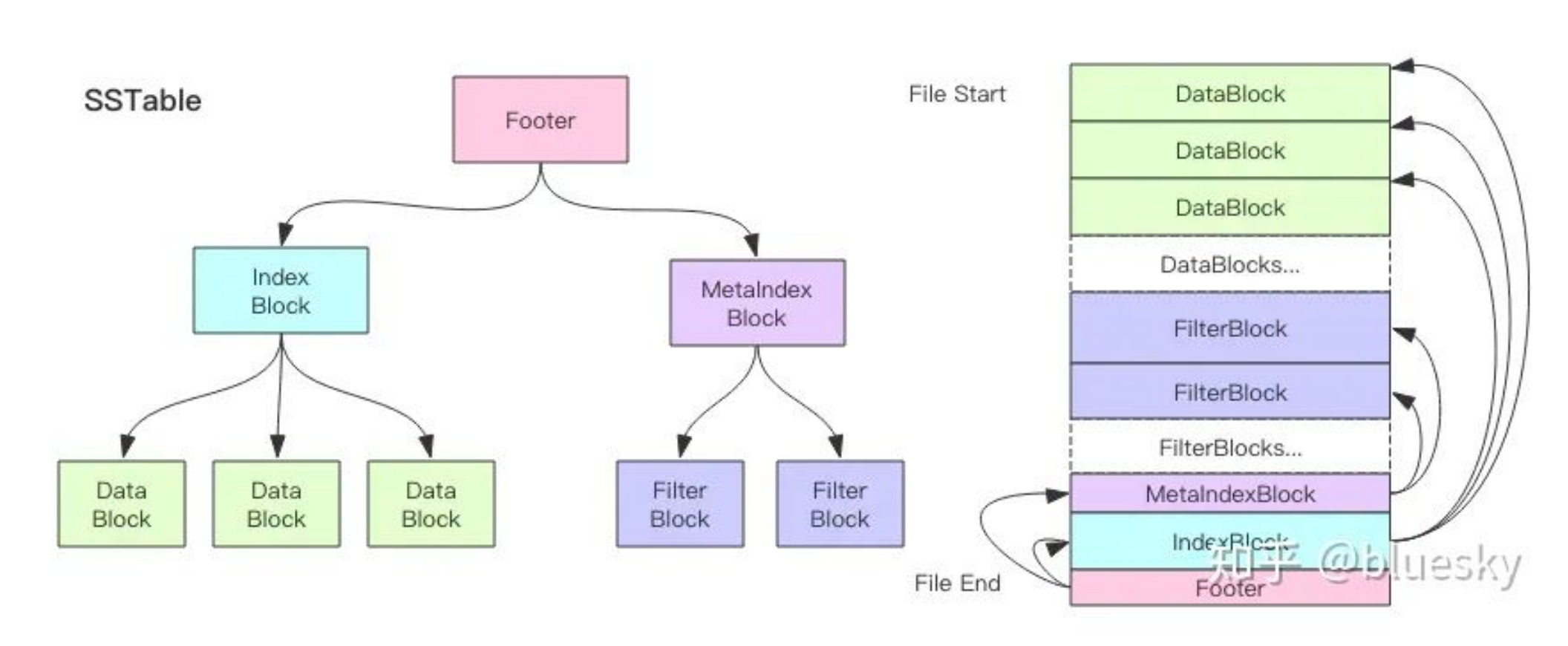
footer:位于ssTable尾部,记录指向Metaindex Block的Handle和指向Index Block的Handle。
所有的Handle是通过偏移量Offset以及Size一同来表示的,用来指明所指向的Block位置。
Footer是解析ssTable文件最开始的地方。通过Footer中记录的这两个关键元信息Block的位置,可以方便的开启之后的解析工作。
另外Footer种还记录了用于验证文件是否为合法SST文件的常数值魔数(maigicnum)。 -
index block: 记录data block的元信息
-
metaindex block: 记录过滤器相关的元信息
-
data block: 保存了kv信息
-
filter block: 现在其实只有一种meta block即filter block。
写入Data Block的数据会同时更新对应Meta Block中的过滤器。
读取数据时也会首先经过布隆过滤器过滤。
Meta Block的物理结构也与其他Block有所不同。bloom filter帮助读操作,确认该sstable内是否包含对应数据。
如果不包含对应数据,则直接避免遍历sstable
RocksDB & LSM
LSM tree (log-structured merge-tree) 是一种对频繁写操作非常友好的数据结构,同时兼顾了查询效率。
LSM tree 是许多 key-value 型、日志型数据库以及新型分布式数据库、OLAP引擎所依赖的核心数据结构,例如 BigTable、HBase、Cassandra、LevelDB、SQLite、Scylla、RocksDB、OceanBase等。由于RocksDB的实现比较有代表性,下面原理的介绍中关于实现部分都以RocksDB的实现为例。
使用场景
我们都知道的一个客观事实是——磁盘或内存的连续读写性能远高于随机读写性能。
LSM由于避免了随机读写,在读写性能上其实都有还不错的表现,尤其在写性能上很突出。
适合于面向写多读少的场景。下图展示了磁盘内存随机、顺序读写的差异。

结构说明
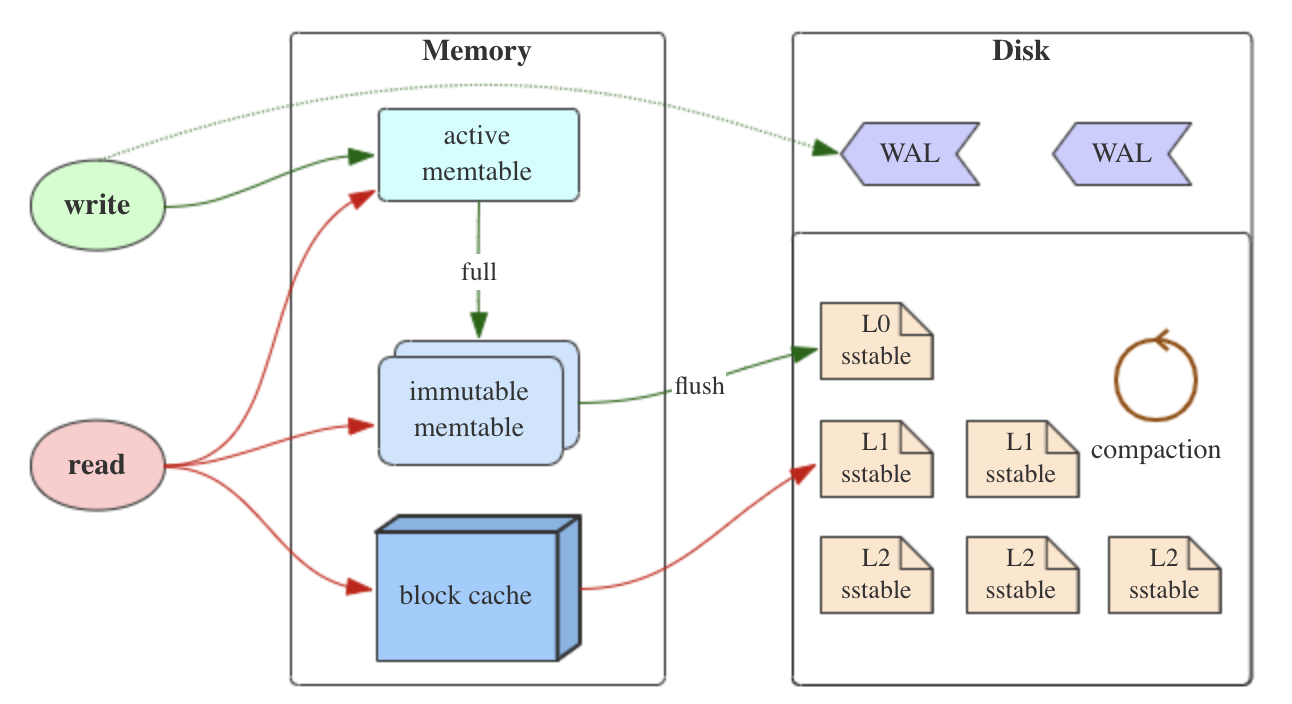
读取数据过程:
查找对象顺序为:
active memtable -> immutable memtable ->L0 ->L1 … ->Ln
-
L0层key重复: L0有多个sst file,由于是memory直接flush出来的,level 0上的sst file key是有重复的,所以L0上的查找是遍历查找,不过会结合bloom filter提升读取效率。可见L0容易产生读取瓶颈,rocksDB也有限制L0层文件数
-
二分查找0层以上SST文件:L0以后的都是经过compaction的,所以没有重复key,可以用二分查找
当数据位于内存时(mem,imm),查找过程中随机访问的时间微乎其微;但当数据保存到硬盘后,将 Sorted Table (sst文件)载入内存的 IO 时间就比较长了。
Sorted Table 使用多级迭代器来缓和这个问题,首先完整地读取了 Index Block 到内存中;进行查找时1.首先在 Index Block 上二分,2.确定 Data Block 的位置后再进行必要的 IO 读取,并且通过3.缓存 Data Block的方式提升读取的性能。
写入数据过程:
写WAL->写memtable
memtable -> L0的过程称之为minor compaction,L0往上的合并称之为major compaction。
Compaction过程
其实Compaction有很多种类,参考Choose a Compaction Strategy,下面介绍比较主流的level compaction和tiered compaction。
基本概念
- 读放大: 每次读请求带来的读盘次数
- 写放大: 每写1byte数据带来n bytes的数据写盘,写放大为n。例如写1K数据需要写一个block,如果block是32K,那么写入放大就是32倍。像B+树的写放大就是叶子节点page size/数据大小。
- 空间放大:所占空间大小/实际数据量大小,空间放大主要与未回收的过期数据量(old version/deleted entries)相关,这个在LSM结构中是普遍存在的。
- 临时空间:compaction任务运行时需要临时空间(新table),compaction完成后旧数据才可以删除。与compaction任务的拆分粒度相关。
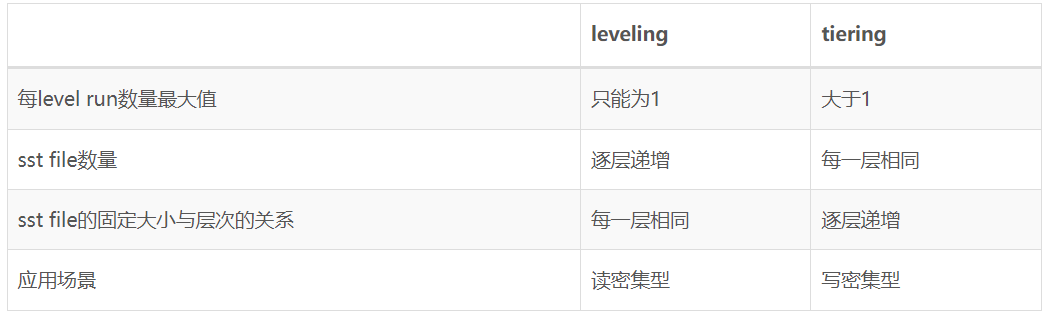
- run:可以理解每个run里KV对具有key有序和不重叠(non-overlapping)的特点。
RocksDB默认使用的compaction策略是level-compaction。Level compaction适合读密集型场景。业界采用Leveling作为Compaction策略的有LevelDB、RocksDB等KV数据库。
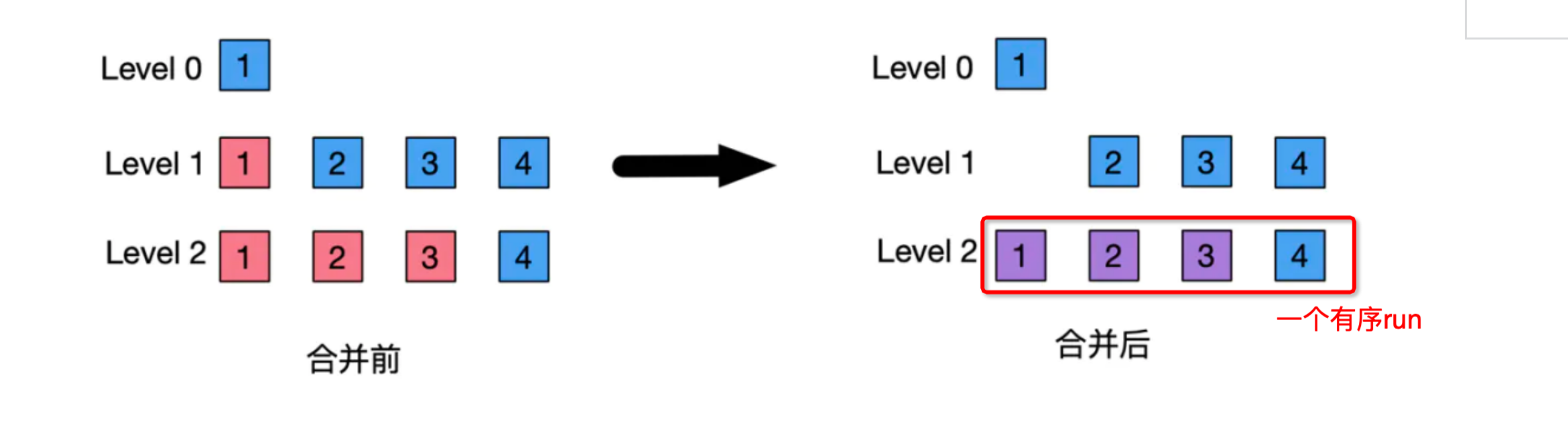
下图可以看到每一层定义的数据大小阈值,当新写入的sst file超过level设定的数据大小阈值时会触发compaction。level-compaction每一层都有固定的较小的sst file构成。总结下Level-Compaction的核心特点主要是:
- 每层只有一个run
- 满足层次设定大小阈值时触发compaction
- 多层的sst file大小固定
L0->L1 使用tiered compaction
合并条件&合并方式
当level满足该层大设定的数据大小阈值时,触发compaction。数据合并到下一层的时候直接和下一层的数据合并形成一个run。这也是level compaction写放大严重的问题。下图演示了level-compaction的过程,关键在于理解compaction构建的是一个有序run。
多个level都需要compaction则会计算score,一般而言,实际sst file size超过该level预设的大小阈值越多时,分数越高。
优点&缺点
相比别的compaction,level-compaction优缺点主要如下:
- 较低程度空间放大(优点):同一层level内只有一个run,各个sst file之间没有重复,所以冗余数据只发生在相邻level之间。空间的冗余占用最多是一个sst file的大小。
- 较低程度读放大(优点):读盘次数每一层1次即可,每一层直接扫描一个有序的run即可。也就是说,run总个数越多,读放大越厉害。
- 写放大(缺点):如果只是在level层直接append,那是没有什么写放大的,比如我要写1K数据,直接append 1K到磁盘上。我们一般指level compaction的写放大问题主要是写入时由于要确保下一层产生一个run,最坏情况会把当前层所有数据全部写入下一层。
tiered-compaction
level-compaction是根据每层设定的数据量大小阈值来触发compaction,而tiered-compaction是根据每层设定的sstable个数阈值来触发compaction(每一层sst file是固定大小,不过每层的sst file固定大小都会大大增加)
- 个数满足阈值后,整一层作为一个新的sstable file放到下一层
- compaction后,下一层会多一个sorted run
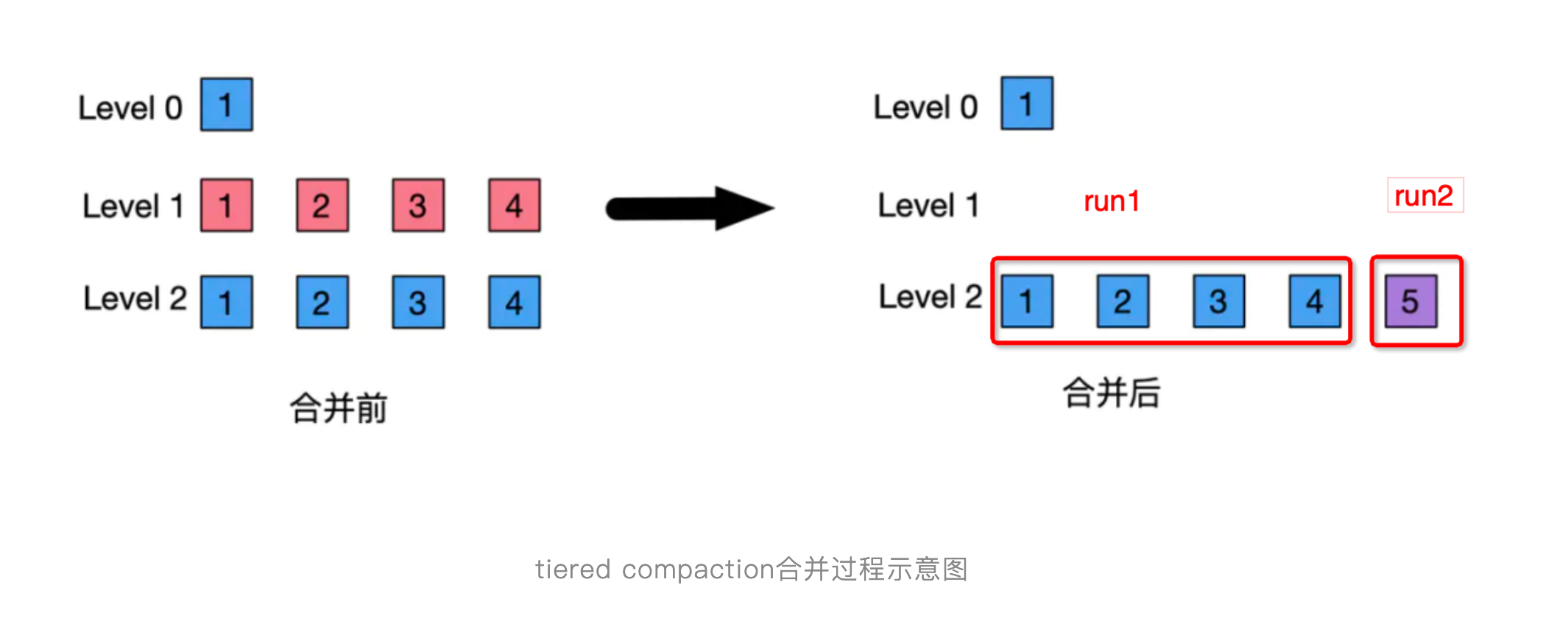
总结下tiered-Compaction的核心特点主要是:
- 每层有多个run
- 多层的sst file个数固定
- 满足层次设定sst file个数阈值时触发compaction
优点&缺点
- 空间放大(缺点):由于各个层次内有多个run,有大量的数据冗余;此外高层次内的sst file文件比较大,很久可能都不会触发合并,这都导致了空间放大。这种空间放大 严重的时候会有10倍以上
- 读放大(缺点):每个level sorted run个数较多,总run个数较多,导致读放大。
- 临时空间放大(缺点):主要是归并合并的时候临时空间的开销。tiering较粗粒度的sst file大小增加了合并时临时空间的开销。
- 较低程度写放大(优点):compaction过程上层数据merge后的run直接append到下一层,相比level-compaction来说写放大程度较低。
Level vs Tiered
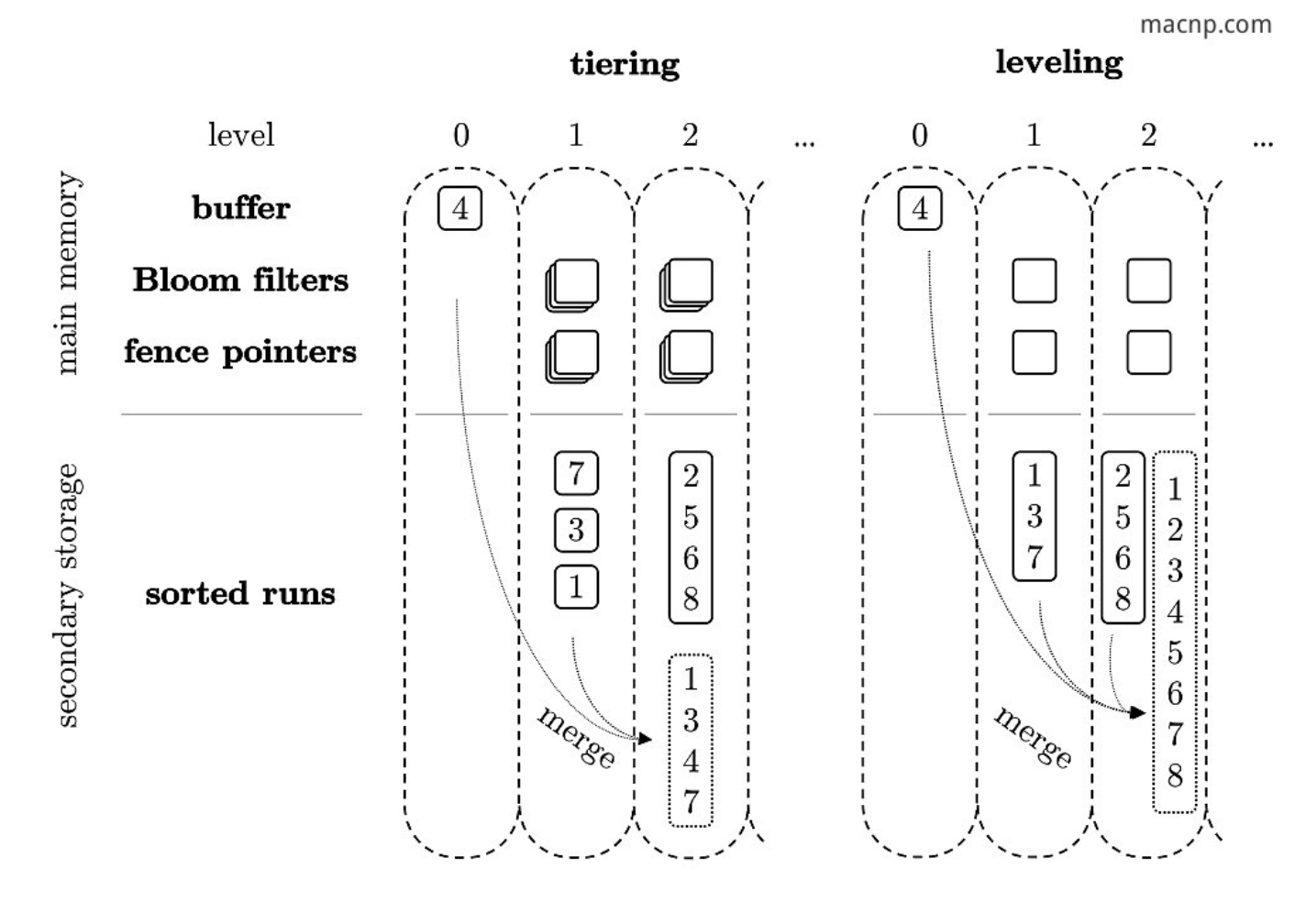
一般可以考虑tiering+leveling混合的方式。如果我们假设,近期数据是写密集型,远期数据是读密集型,可以在低level用tiering,高level用level compaction。像rocksDB就是level0用tiering
LSM优化
LSM的优化在学术界也是一个比较火热的议题,像Dostoevsky: Better Space-Time Trade-Offs for LSM-Tree Based Key-Value Stores via Adaptive Removal of Superfluous Merging中提到的lazy leveling 有兴趣也可以了解下。
里面作者详细的用公式列出来不同的 Compaction 策略对不同的操作的 I/O 影响,以及空间占用,从而指导作者做了相关的优化,构建了 Dostoevsky。
LSM和B+树的比较
相对于B+树,LSM有更好的写性能,但是在读取性能上来说是不如B+树的,主要原因是由于:
- L0层遍历开销:L0层数据遍历,虽然有bloom filter加速,但是其读取性能仍然是不稳定的,最坏情况需要遍历所有 sst file,相当于O(n)
- 范围查询效率不高:不像B+树排序好的叶子节点很容易也很高效做范围查询,LSM做遍历查询需要遍历多个SST file,对L0还需要做合并才能获取到最终准确的数据。这也影响了LSM结构上数据的查询性能。
不过现在实现LSM的数据库基本也都会优化LSM的读取性能,更好的支持范围查询。大家需要更加理性地看待LSM适合写多读少这句话的含义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号