SPDK详解
导语
众所周知在Linux起源之初,文件系统io栈针对机械盘进行了众多优化,包括page、cache等多种优化方式。内核采用中断的方式进行DMA将数据从内核态拷贝回用户态,再交由用户程序处理,这是机械硬盘时代的io处理方式。
而随着nvme-ssd的出现,如果再采用此种方式就会导致大量的硬盘空闲,浪费硬盘性能。为了帮助上游的应用厂商以及存储厂商更好的发挥ssd磁盘的性能,intel开发了一套基于nvme-ssd的开发套件,SPDK。
SPDK的目标是通过使用Intel的网络,处理,存储技术,将固态存储介质出色的功效发挥到极致。相对于传统IO方式,SPDK运用了两项关键技术:UIO和pooling。
首先,将设备驱动代码运行在用户态,避免内核上下文切换和中断将会节省大量的处理开销,允许更多的时钟周期被用来做实际的数据存储。无论存储算法(去冗,加密,压缩,空白块存储)多么复杂,浪费更少的时钟周期总是意味着更好的性能和时延。这并不是说内核增加了不必要的开销;相反,内核增加了一些与通用计算用例相关的开销,因而可能不适合专用的存储栈。上文也提及到SPDK实际上是为nvme-ssd开发的一套开发组件,并不适用于机械硬盘。
其次,采用轮询模式改变了传统I/O的基本模型。在传统的I/O模型中,应用程序提交读写请求后进入睡眠状态(阻塞),一旦I/O完成,中断就会将其唤醒。
轮询的工作方式则不同,应用程序提交读写请求后继续执行其他工作(立即返回),以一定的时间间隔回头检查I/O是否已经完成(poll_cq处理完成wc,如果没有wc立即返回)。
这种方式避免了中断带来的延迟和开销,并使得应用程序提高了I/O效率。
在机械硬盘时代,中断开销只占整个I/O时间的很小的百分比,因此给系统带来了巨大的效率提升。(因为更多的是读写数据的过程)
然而,在固态设备时代,持续引入更低时延的持久化设备,中断开销成为了整个I/O时间中不可忽视的部分。这个问题在更低时延的设备上只会越来越严重。系统已经能够每秒处理数百万个I/O,所以消除数百万个事务的这种开销,能够快速地复制到多个core中。数据包和数据块被立即分发,因为等待花费的时间变小,使得时延更低,一致性时延更多(抖动更少),吞吐量也得到了提高。
SPDK
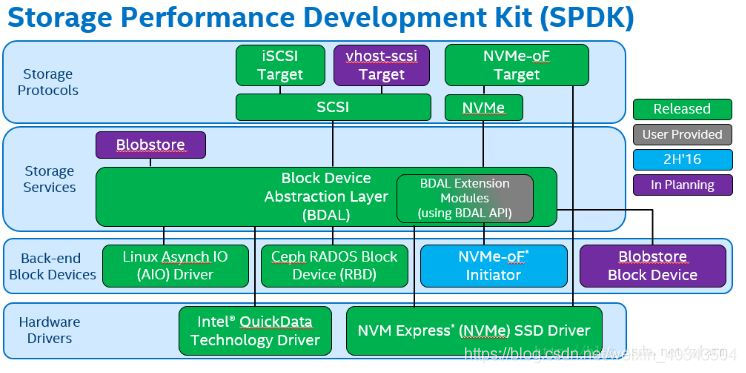
驱动层:
NVMe driver:SPDK的基础组件,高度优化且无锁的驱动提供了前所未有的高扩展性,高效性和高性能
块设备层:
NVMe over Fabrics(NVMe-oF)initiator:本地SPDK NVMe驱动和NVMe-oF initiator共享一套公共的API。本地远程API调用及其简便
Ceph RBD:将rbd设备作为spdk的后端存储。
Blobstore Block Device:基于SPDK技术设计的Blobstore块设备,应用于虚机或数据库场景。由于spdk的无锁机制,将享有更好的性能。
Linux AIO:spdk与内核设备(如机械硬盘)交互。
存储服务层:
bdev:通用的块设备抽象。连接到各种不同设备驱动和块设备的存储协议,类似于文件系统的VFS(实际块存储为块设备层的某一种)。在块层提供灵活的API用于额外的用户功能(磁盘阵列,压缩,去冗等)。
Blobstore:SPDK实现一个高精简的类文件的语义(非POSIX)。这可为数据库,容器,虚拟机或其他不依赖于大部分POSIX文件系统功能集(比如用户访问控制)的工作负载提供高性能支撑。
存储协议层
iSCSI target:现在大多使用原生iscsi
vhost-scsi target:KVM/QEMU的功能利用了SPDK NVMe驱动,使得访客虚拟机访问存储设备时延更低,使得I/O密集型工作负载的整体CPU负载有所下降。
NVMe-oF target:实现了新的NVMe-oF规范。虽然这取决于RDMA硬件,NVMe-oF target可以为每个CPU核提供高达40Gbps的流量。
SPDK线程模型
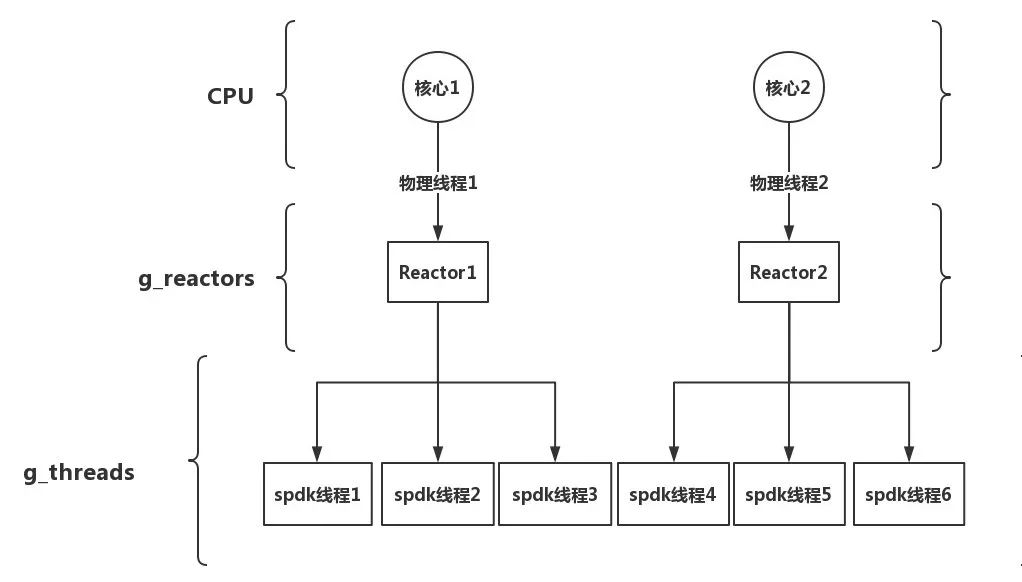
Reactor – 单个CPU Core抽象,主要包含了:
- Lcore对应的CPU Core id
- Threads在该核心下的线程
- Events 这是一个spdk ring,用于事件传递接收
Thread – 线程,但它是spdk抽象出来的线程,主要包含了:
- io_channels资源的抽象,可以是bdev,也可以是具体的tgt
- tailq 线程队列,用于连接下一个线程
- name 线程的名称
- Stats 用于计时统计闲置和忙时时间的
- active_pollers 轮询使用的poller,非定时
- timer_pollers 定时的poller
- messages 这是一个spdk ring,用于消息传递接收
- msg_cache 事件的缓存
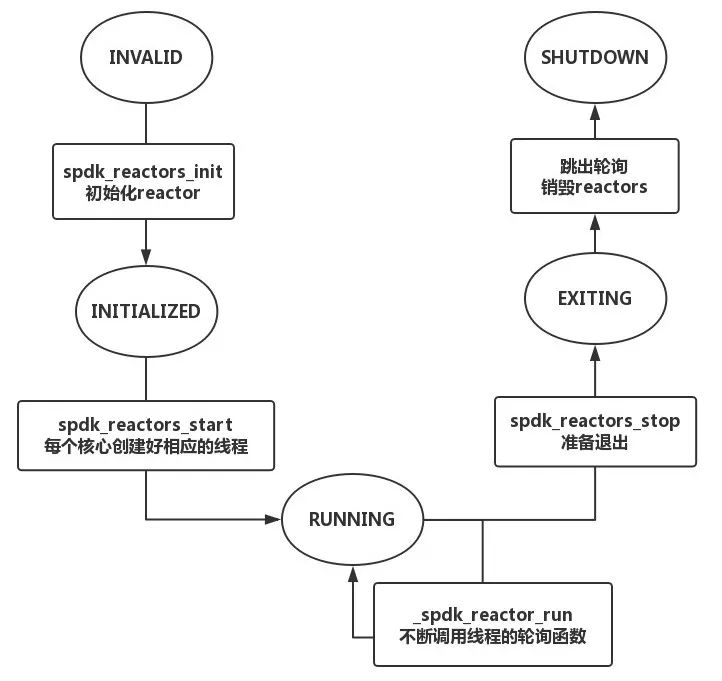
对象g_reactor_state有五个状态对应了应用中reactors运行运行状态,
enum spdk_reactor_state {
SPDK_REACTOR_STATE_INVALID = 0,
SPDK_REACTOR_STATE_INITIALIZED = 1,
SPDK_REACTOR_STATE_RUNNING = 2,
SPDK_REACTOR_STATE_EXITING = 3,
SPDK_REACTOR_STATE_SHUTDOWN = 4,
};
初始情况下是:
SPDK_REACTOR_STATE_INVALID状态,在spdk app(任意一个target,比如nvmf_tgt)启动时,即调用了spdk_app_start方法,会调用spdk_reactors_init,在这个方法中将会初始化所有需要被初始化的reactors(可以在配置文件中指定需要使用的Core,CPU Core 和reactor是一对一的)。并且会将g_reactor_state设置为SPDK_REACTOR_STATE_INITIALIZED。
spdk_reactors_init方法中调用了spdk_thread_lib_init方法传入了创建thread的spdk_reactor_schedule_thread方法,在调用spdk_thread_create会回调该方法。这个方法它主要的功能就是告诉这个新创建的线程绑定创建该线程的reactor。
总结一下reactors和CPU core以及spdk thread关系应该如图所示
Reactor生命周期流程图则如图所示
当Reactors进行轮询时,除了处理自己的事件消息之外,还会调用注册在该reactor下面的每一个线程进行轮询。不过通常一个reactor只有一个thread,在spdk应用中,更多的是注册多个poller而不是注册多个thread。
Io_device 和 io_channel在thread中也是非常重要的概念。它们的实现都在thread.c中,io_device是设备的抽象,io_channel是对该设备通道的抽象。一个线程可以创建多个io_channel . io_channel只能和一个io_device绑定,并且这个io_channel是别的线程使用不了的。
io_device实际上只提供了一些自身io_device的操作和io_channel相关的方法,具体的io_device实体其实是那个名字叫io_device的void指针。因为thread中的io_device只提供了thread这一层接口,具体的io操作每一个设备很难被抽象出来,所以这一层的接口只负责管理io_channel的创建、销毁和绑定等。
虽然io_channel看起来是很简单的结构体,实际上在创建一个io_device的时候,会要求使用者传入一个io_channel_ctx的大小作为调用的参数,而在给io_channel分配内存的时候,除了分配本身io_channel结构体的大小外,还会额外分配一个io_channel_ctx的大小,这个context可以理解成一个void指针,当用户在使用io_channel的时候,实际上还是通过context的部分去访问io_device。
spdk thread 模型是spdk无锁化的基础,在一个线程中,当分配一个任务后,一直会运行到任务结束为止,这确保了不需要进行线程之间的切换而带来额外的损耗。同时,高效的spdk ring提供了不同线程之间的消息传递,这就使得任务结束的结果可以高效的传递给别的处理线程。而io_device和io_channel的设计保证了资源的抽象访问以及独立的路径不去争抢资源池,并且块设备由于是对块进行操作的所以也十分适合抽象成io_device。正是因为以上几点才让spdk线程模型能够达到无锁化且为多个target提供了基础线程框架的支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号