redis pipeline
pipeline
Redis 流水线是一种通过一次发出多个命令而不等待每个单独命令的响应来提高性能的技术。大多数 Redis 客户端都支持流水线。本文档描述了流水线旨在解决的问题以及流水线在 Redis 中的工作原理。
请求/响应协议和往返时间 (RTT)
Redis 是使用客户端-服务器模型和所谓的请求/响应协议的 TCP 服务器。
这意味着通常通过以下步骤完成请求:
- 客户端向服务器发送查询,并从套接字中读取,通常以阻塞方式,以获取服务器响应。
- 服务器处理命令并将响应发送回客户端。
这个时间称为 RTT(往返时间)。当客户端需要连续执行许多请求时(例如,将许多元素添加到同一个列表,或使用许多键填充数据库),很容易看出这会如何影响性能。例如,如果 RTT 时间为 250 毫秒(在 Internet 上的链接非常慢的情况下),即使服务器每秒能够处理 10 万个请求,我们也将能够每秒处理最多四个请求。
Redis pipeline
可以实现请求/响应服务器,以便即使客户端尚未读取旧响应,它也能够处理新请求。这样就可以向服务器发送多个命令,而无需等待回复,最后一步即可读取回复。
这被称为流水线,并且是一种广泛使用了几十年的技术。例如,许多 POP3 协议实现已经支持此功能,从而大大加快了从服务器下载新电子邮件的过程。
Redis 从早期就支持流水线,所以无论你运行什么版本,你都可以在 Redis 中使用流水线。
这次我们不再为每次调用支付 RTT 的费用,而是为三个命令支付一次。
重要提示:当客户端使用流水线发送命令时,服务器将被迫使用内存对回复进行排队。因此,如果您需要使用流水线发送大量命令,最好将它们分批发送,每个包含合理数量的命令,例如 10k 个命令,读取回复,然后再次发送另外 10k 个命令,依此类推。速度将几乎相同,但使用的额外内存最多将是对这 10k 命令的回复进行排队所需的数量。
适用场景
流水线不仅仅是一种减少与往返时间相关的延迟成本的方法,它实际上大大提高了您在给定 Redis 服务器中每秒可以执行的操作数量。这是因为在不使用流水线的情况下,从访问数据结构和产生回复的角度来看,为每个命令提供服务非常便宜,但从进行套接字 I/O 的角度来看,它的成本非常高。这涉及调用read()和write()系统调用,这意味着从用户空间到内核空间。上下文切换是一个巨大的速度损失。
使用流水线时,通常使用单个read() 系统调用读取许多命令,并使用单个系统调用传递多个回复write()。因此,每秒执行的总查询数最初随着流水线的延长几乎呈线性增长,最终达到不使用流水线获得的基线的 10 倍,如图所示。
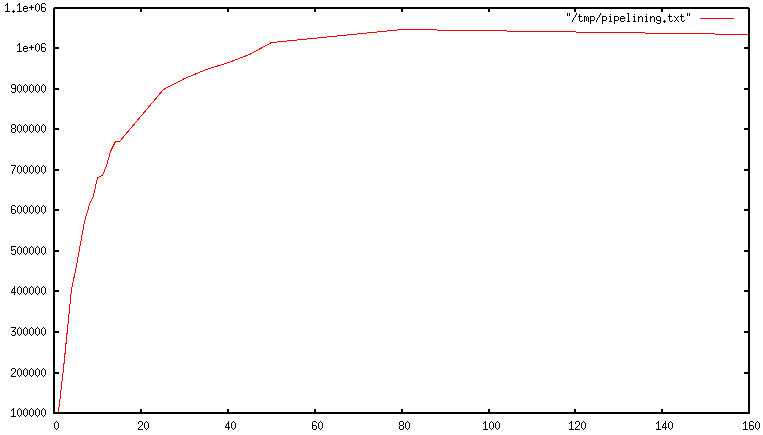
但有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进 redis 了,那这种场景就不适合。
还有的系统,可能是批量的将数据写入 redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入 redis,可能失败了2条无所谓,后期有补偿机制就行了,比如短信群发这种场景,如果一下群发10000条,按照第一种模式去实现,那这个请求过来,要很久才能给客户端响应,这个延迟就太长了,如果客户端请求设置了超时时间5秒,那肯定就抛出异常了,而且本身群发短信要求实时性也没那么高,这时候用 pipeline 最好了。
pepeline的性能
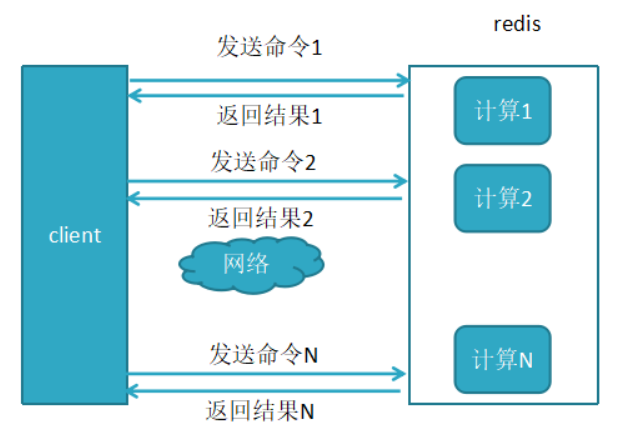
1、未使用pipeline执行N条命令
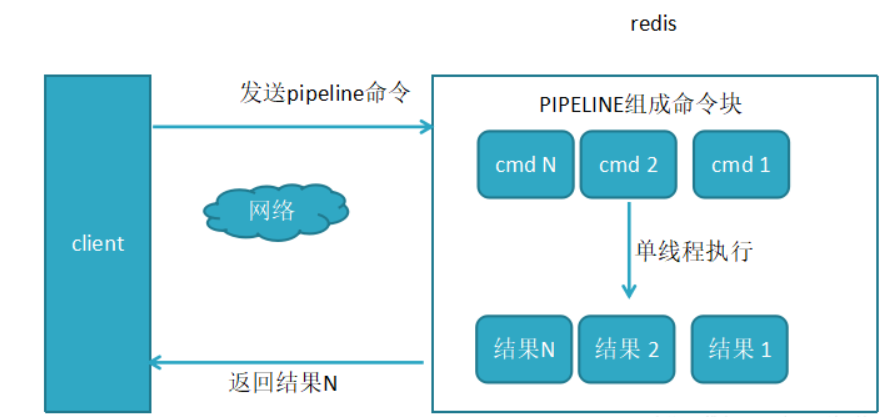
2.使用了pipeline执行N条命令
3.两者性能对比
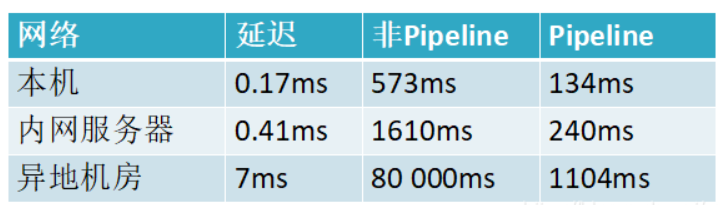
这是一组统计数据出来的数据,使用Pipeline执行速度比逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显。
原生批命令(mset, mget)与Pipeline对比
1、原生批命令是原子性,pipeline是非原子性
2、原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
3、原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
Pipeline正确使用方式
- 使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成。
- pipeline是多条命令的组合,为了保证它的原子性,redis提供了简单的事务。
pipeline使用
Redis 的 pipeline(管道)功能在命令行redis-cli中没有,但 redis 是支持 pipeline 的,而且在各个语言版的 client 中都有相应的实现。 由于网络开销延迟,就算 redis server 端有很强的处理能力,也会由于收到的 client 消息少,而造成吞吐量小。当 client 使用 pipelining 发送命令时,redis server 必须将部分请求放到队列中(使用内存),执行完毕后一次性发送结果;如果发送的命令很多的话,建议对返回的结果加标签,当然这也会增加使用的内存;
Pipeline 在某些场景下非常有用,比如有多个 command 需要被“及时的”提交,而且他们对相应结果没有互相依赖,对结果响应也无需立即获得(即时性要求不强),那么 pipeline 就可以充当这种“批处理”的工具;而且在一定程度上,可以较大的提升性能,性能提升的原因主要是 TCP 连接中减少了“交互往返”的时间。
使用hiredis pipeline的例子
redisReply *reply;
redisAppendCommand(context,"SET foo bar");
redisAppendCommand(context,"GET foo");
redisGetReply(context,(void**)&reply); // reply for SET
freeReplyObject(reply);
redisGetReply(context,(void**)&reply); // reply for GET
freeReplyObject(reply);
再来分析pipeline加速的原因
每个请求命令发出后 client 阻塞并等待 redis 服务器处理,redis 处理完请求命令后会将结果通过响应报文返回给 client,执行多条命令的时候需要等待上一条命令执行完毕才能执行。比如:
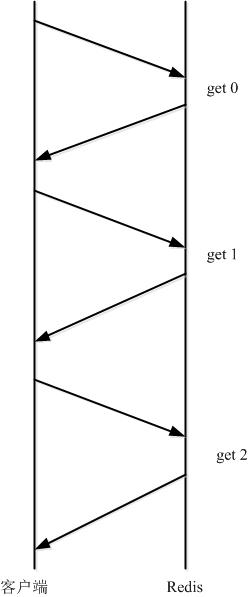
由于通信会有网络延迟,假如 client 和 server 之间的包传输时间需要0.125秒。那么上面的三个命令6个报文至少需要0.75秒才能完成。这样即使 redis 每秒能处理十万个命令,而我们的 client也只能一秒钟发出四个命令。这显然没有充分利用 redis 的处理能力。
而管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline 通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。 Pipeline 的默认的同步的个数为53个,也就是说 arges 中累加到53条数据时会把数据提交。其过程如下图所示:client 可以将三个命令放到一个 tcp 报文一起发送,server 则可以将三条命令的处理结果放到一个 tcp 报文返回。
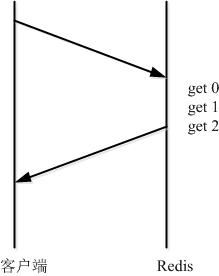
需要注意到是用 pipeline 方式打包命令发送,redis 必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。具体多少合适需要根据具体情况测试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号