metafs分区思想
分片思想
-
客户端 pinode -> pinode_hash
XXHash(pinode) % (一个region大小 * server数量),总共Hash范围应该不超过(一个region大小 * server数量),因为server初始化时总的范围只有这么大 -
客户端计算该pinode属于哪个region
遍历Region Map,如果pinode_hash在某Region的范围内(start边界值<=hashval<=end边界值),返回region id
- Region Map的各个Region边界值怎么划分的?
服务器初始化时划分,客户端初始化时会通过RPC获取这个Region Map并保存在本地
servier初始时,每个server有一个regionid等于初始线程id的region,每个Region的Key范围为[region_id * PINODE_HASH_RANGE, (region_id + 1) * PINODE_HASH_RANGE)
即每个region所管理的key范围是一样大的,等间距的
- 计算该regionid属于哪个server
JumpConsistentHash(regionid, server数量)会返回对应的server_id,即[0,servernum)的其中一个值
- JumpConsistentHash可以保证region均衡划分到各个server,并且增加节点时保证原来的region只会迁移到新的server或保持不变
4.这样就完成了文件或目录请求指定server,保证负载均衡
再分片(迁移)思想
-
Redis使用固定数量的shard,即创建比节点数多几倍的shard,并为每个节点分配多个shard。当添加新节点时,新节点可以从原来节点随机抽取部分shard。
这样,shard在节点之间移动,总的shard数量没变,Hash(key)对应的shardid也不变。唯一改变的时shard所属的server。
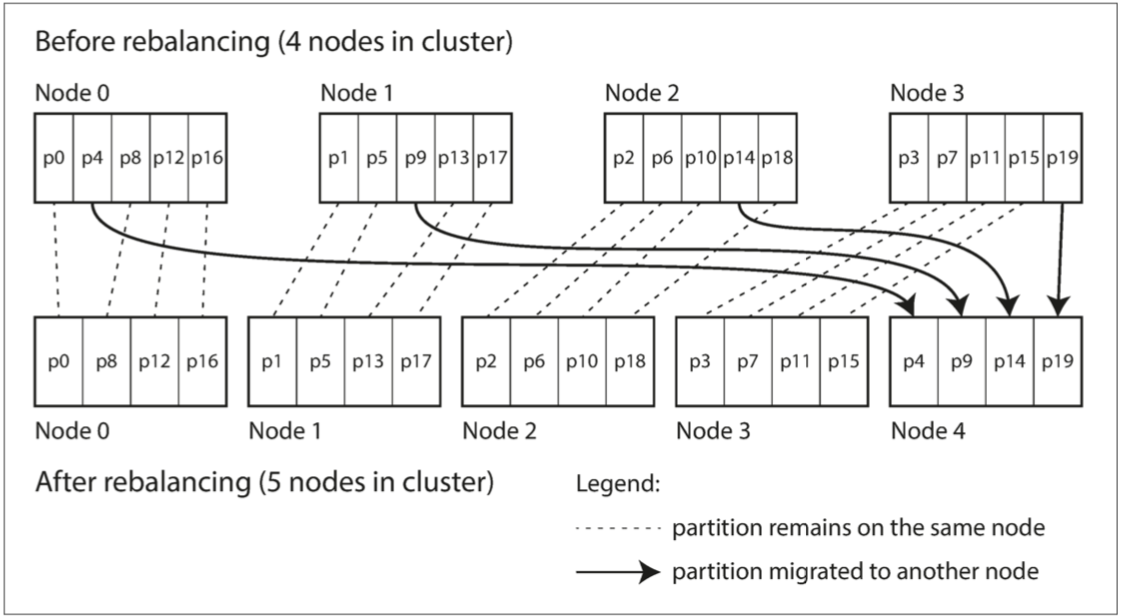
-
MetaFS不使用固定数量的shard,而是一种动态分区的思想。每个server首先分配一个region,当这个region所包含的key数量过多或者负载过大,就会将region对半拆分,生成两个region,并将新的一个region通过JumpConsistentHash分配给另一个server
-
动态分区的一个优点是分区数量适应总数据量。如果只有少量的数据,少量的分区就足够了,所以开销很小。如果数据很大时,每个分区的大小被限制在一个阈值。
路由思想
前面提到了MetaFS使用动态分区,那么我们怎么知道key所属的region在哪一个server上呢?
- 在客户端通过key得到regionid后,通过JumpConsistentHash得到serverid(因为分裂的时候也使用的JumpConsistentHash,所以只要regionid是正确的,那么serverid就是正确的),但是分裂后客户端的regionMap和server的regionMap不同,分裂完成后会要求客户端重新rpc读取相关的region。
如下图所示,metafs使用第三种策略
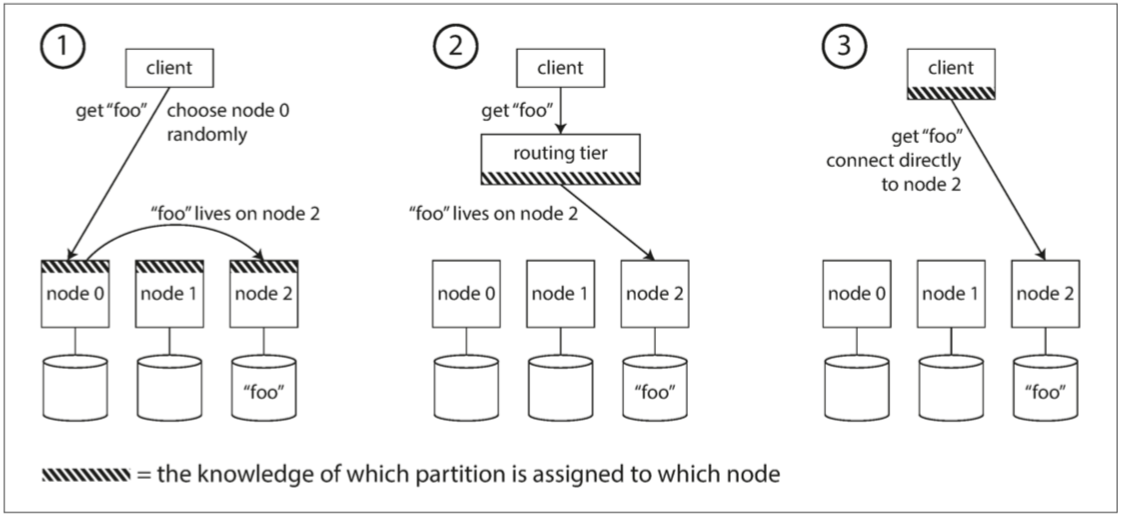
- 允许客户联系任何节点(例如,通过循环策略的负载均衡(Round-Robin Load Balancer))。如果该节点恰巧拥有请求的分区,则它可以直接处理该请求;否则,它将请求转发到适当的节点,接收回复并传递给客户端。
- 首先将所有来自客户端的请求发送到路由层,它决定了应该处理请求的节点,并相应地转发。此路由层本身不处理任何请求;它仅负责分区的负载均衡。
- 客户端知道分区和节点的分配。在这种情况下,客户端可以直接连接到适当的节点,而不需要任何中介。(metafs通过regionmap可以准确知道key的regionid,通过JumpConsistentHash准确知道regionid的serverid)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号