muduo buffer
网络模型
-
nonblocking + IO多路复用
原因:
1.nonblock io + 轮询等待事件完成不可取 (耗CPU cycle)
2.IO多路复用不能用block IO,因为read,write会阻塞当前线程,这样就不能单线程处理另外已经就绪的其他connfd IO事件 -
一个线程一个eventloop,高效的eventloop(libevent, libev)
-
多个TCPServer和TCPClient可以共享同一个eventloop
文件传输
- 使用TcpConn::send(),send保证数据会发送给对方,send是非阻塞的(即使output buffer满了,也不会阻塞当前线程),send是线程安全的(消息不会混叠交织,多线程发送顺序不确定)
- 非阻塞网络编程中,发送消息由muduo完成,用户不需调用write或send等系统调用,因此TcpConn需要有output buffer
- send(const Slice&)可以发送string和char,send(Buffer)不用const引用,是因为函数可能用Buffer::swap交换数据,避免内存拷贝(类似右值引用)
muduo buffer
-
为什么nonblock网络编程需要buffer?
因为要避免epoll_wait之外的阻塞,每个tcp socket都要有stateful的inputbuffer(read),outputbuffer(write)
tcpconn需要output buffer,为了避免一次send只发送一部分数据,如80k/100K(因为操作系统write一次只接受80k),注册epoll_out事件,一旦可写就立即发送,写完了就关闭这个事件,如果程序又写了50k,应该把这数据放入buffer而不是直接write,如果buffer还有数据就不能直接关闭连接,而要等待数据发送完
tcpconn需要input buffer,网络库处理socket可读事件时,要一次把socket数据读完(从OS搬到应用层),否则会频繁POLLIN,造成busyloop


-
buffer的结构?
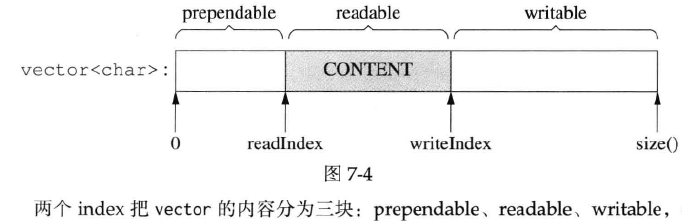
-
Buffer不是线程安全的


-
替换vector
?
可以用circular buffer,可以减少内部挪腾(前面+后面可以填充数据,需要[read_idx~write_idx]挪到前面去) -
zero copy?
原来需要把数据copy进vector,可以参考libevent,用链表把数据块连起来,但高性能的代价是代码不太好懂 -
性能问题?






 浙公网安备 33010602011771号
浙公网安备 33010602011771号