深浅拷贝
昨日回顾
# 小数据池 针对的数据类型: int, str, bool 小数据池可以帮我们缓存一个对象. 当重复使用的时候可以快速的响应. 直接把对象返回. 优点: 快速拿到对象, 节省内存 缺点: 当小数据池中的内容太多的时候. 程序响应速度是很慢的. # is和== is 比较的是内存地址. == 比较的是内容
# 编码转换 encode() : 可以帮我们把字符串转换成bytes类型 decode() : 把bytes类型还原回字符串类型 bytes是字节. 是python中最小的数据单元
今日内容
1. 基础数据类型补充 大多数的基本数据类型的知识.已经学完了 join() "*".join("马虎疼") # 马*虎*疼 把传递进去的参数进行迭代. 获取到的每个元素和前面的*进行拼接. 得到的是字符串 split() 切割. 切割的结果是列表 列表和字典: 都不能在循环的时候直接删除 (##可迭代对象在循环遍历的时候是都不能增加元素也不能删除元素的,列表是删不干净,达不到你要的效果,字典是直接报错. 总之,在自身遍历的同时不能改变自身的长度,但是是可以在遍历的同时对元素进行修改和查询的,这个并不会对对象本身的长度造成改变. 列表的改变一定要用到索引去改变元素,字典一定要使用键,如果是在遍历的过程中直接对列表的元素本身进行修改并赋值,只是改变了中间变量, 并没有塞进原来的列表中.字典同理.字典的key就相当于列表的索引) 把要删除的内容记录在新列表中然后循环这个新列表. 删除旧列表(或旧字典) fromkeys() ##是字典的一个方法 坑1: 返回新字典. 不会更改老字典 坑2: 当value是可变的数据类型. 各个key共享同一个可变的数据类型. 其中一个被改变了. 其他都跟着变 # 程序员找工作和菜市场大妈买白菜是一样的 2. 深浅拷贝(重点, 难点) 1. = 没有创建新对象, 只是把内存地址进行了复制 2. 浅拷贝 lst.copy() 只拷贝第一层.(##第一层的含义是碰见内部的元素是可变的数据类型(比如list, set, dict)时还是只把内存地址进行拷贝) 3. 深拷贝 import copy copy.deepcopy() 会把对象内部的所有内容进行拷贝
一.基础数据类型补充


lst = ["alex", "dsb", "wusir", "xsb"] # 使用前面的字符串. 对后面的列表进行拼接,拼接的结果是一个字符串 s = "_".join(lst) print(s) # split() 根据你给的参数进行切割, 切割的结果是列表.##不传入参数的话,默认是以空白(包括所有的空格,\t,\n)进行分割,长度不相同的空白也当成是相同的分隔符 s = "alex_dsb_wusir_xsb" lst = s.split("_") # 列表 print(lst) # 需要把字符串转化成列表: str.split()==>lst # 把列表转化成字符串: "*".join(lst) ==> str # print("*".join("周润发")) # 用迭代的方式进行的拼接 # 2. 关于删除 lst = ["篮球", "排球" ,"足球", "电子竞技", "台球"] lst.clear() for el in lst: lst.remove(el) print(lst) # 删不干净.原因是: 删除一个. 元素的索引要重新排列, for循环向后走一个. 差一个 for i in range(len(lst)): # 0 1 2 3 4 lst.pop(0) print(lst) lst = ["篮球", "排球" ,"足球", "电子竞技", "台球"] # 最合理的删除方式: # 1. 把要删除的内容写在新列表中. # 2. 循环这个新列表. 删除老列表 # 需求: 删除列表中代球字的运动项目 new_lst = [] for el in lst: if "球" in el: new_lst.append(el) # 记录要删除的内容 # 要删除的列表 print(new_lst) # 循环新列表. 删除老列表 for el in new_lst: # ['篮球', '排球', '足球', '台球'] lst.remove(el) print(lst) # 字典 # 字典在被循环的时候是不能删除的. dic = {"张无忌":"乾坤大挪移", "周芷若":"哭", "赵敏":"卖萌"} for k in dic: # dic.pop(k) # dictionary changed size during iteration dic["灭绝师太"] = "倚天屠龙剑" # dictionary changed size during iteration # 把要删除的key保存在一个新列表中 # 循环这个列表.删除字典中的key:value lst = [] for k in dic: lst.append(k) # 循环列表 # 删除字典中的内容 for el in lst: dic.pop(el) print(dic) s = {"杨逍", "范瑶", "韦一笑", "谢逊"} # set集合 for el in s: s.remove(el) # Set changed size during iteration # 集合和字典是一家人(##字典和集合自己本身都是可变的数据类型,而对于内部的元素都有要求) # 字典: key必须是不可变的. 可哈希的, (内部的key是)不重复的 # 集合: 元素必须是不可变的. 可哈希的, (内部的元素是)不重复的 ''' 字典:初始化时候就重复写key的话,后面的一个会把前面一个的value覆盖;后面添加已经存在的key的话,是对之前value的修改 集合:初始化时候就重复写元素的话,只会保留一个;后面添加已经存在的元素的话,添加不进去)(所以有一种说法是:集合就是只存储了key的字典 ''' dic = {"韦一笑":"青翼蝠王", "韦一笑":"张无忌"} dic['韦一笑'] = "应天正" # 修改 # 字典的key是唯一的不重复的,对于已经存在的key所做的'添加'是修改 print(dic) # 坑: 大坑, 神坑 # fromkeys() 帮我们创建字典用的 # 把第一个参数进行迭代. 拿到每一项作为key和后面的value组合成字典 d = dict.fromkeys("张无忌", "赵敏") # 创建字典 print(d) # 坑1: 返回新字典. 和原来的字典没有关系 dic = {} d = dic.fromkeys("风扇哥", "很困") print(dic) # {} print(d) # {'风': '很困', '扇': '很困', '哥': '很困'} # # 坑2: 如果value是可变的数据类型, # # 那么其中一个key对应的value执行的更改操作. 其他的也跟着变 d = dict.fromkeys("胡辣汤", []) print(d) # {'胡': [], '辣': [], '汤': []} print(id(d['胡'])) print(id(d['辣'])) print(id(d['汤'])) d['胡'].append("河南特色") print(d) # {'胡': ['河南特色'], '辣': ['河南特色'], '汤': ['河南特色']} v = dict.fromkeys(['s1', 's2'], []) v['s1'].append(123) print(v) # {'s1': [123], 's2': [123]} v['s1'] = 567 print(v) # {'s1': 567, 's2': [123]}
字符串和列表互转
#"拼接符".join(可迭代对象) 用迭代的方式进行的拼接,结果是字符串 li = ["李嘉诚”, ”麻花藤”,”黄海峰”,”刘嘉玲"] s = "_".join(li) # 列表转字符串 print(s) li =“黄花大闺女” s = "_".join(li) # 字符串的迭代拼接 print(s) # str.split("切割符") 根据你给的分割符进行切割(分割符相当于刀口,不会保留), 切割的结果是列表 s = "alex_dsb_wusir_xsb" lst = s.split("_") # 字符串转列表 print(lst)
列表删除元素
循环删除列表中的每一个元素
# 使用remove
li = [11, 22, 33,44] for e in li: li . remove(e) print(li) 结果: [22,44]
分析原因:
for的运行过程会有一个指针来记录当前循环的元素是哪一个.一开始这个指针指向第0个,然后获取到第0个元素,紧接着删除第0个.这个时候原来是第一个的元素会自动的变成第0个.然后指针向后移动一次,指向1元素.这时原来的1已经变成了0,也就不会被删除了.
用del删除试试看:
li = [11, 22,33,44] for i in range(0, len(li)): #range只在程序第一次走到 for循环的时候判断索引范围(此时len(li)=4),接下去就固定了,否则每次都改变的话,每次都只能是0 del li[i] print(li)
# i= 0, 1, 2 删除的时候li[0] 被删除之后. 后⾯一个就变成了第0个.
# 以此类推. 当i = 2的时候. list中只有一个元素. 但是这个时候删除的是第2个 肯定报错啊
经过分析发现. 循环删除都不⾏行行. 不论是用del还是用remove. 都不能实现. 那么pop呢?
for el in li: li.pop() # pop也不⾏ print(li) 结果: [11, 22] # 循环到元素11,删除44;循环到元素22,删除33,再往下就没有元素可以继续了
只有这样才是可以的:
for i in range(0, len(li)): # 循环len(li)次, 然后从后往前删除 li.pop() print(li)
或者. 用另一个列表来记录你要删除的内容. 然后循环删除
li = [11, 22, 33, 44] del_li = [] for e in li: del_li.append(e) for e in del_li: li.remove(e) print(li)
注意:由于删除元素会导致元素的索引改变, 所以容易出现问题. 尽量不要在循环中直接去删除元素. 可以把要删除的元素添加到另一个集合中然后再批量删除.
字典的创建和删除元素
字典的创建
dict中的fromkey(),可以帮我们通过list来创建一个dict
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"])
print(dic)
结果: {'jay': ['周杰伦', '麻花藤'], 'JJ': ['周杰伦', '麻花藤']}
前⾯列表中的每一项都会作为key, 后面列表中的内容作为value. 生成dict
好了. 注意:
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"])
print(dic)
dic.get("jay").append("胡⼤大")
print(dic)
结果: {'jay': ['周杰伦', '麻花藤', '胡⼤大'], 'JJ': ['周杰伦', '麻花藤', '胡⼤大']}
代码中只是更改了jay那个列表. 但是由于jay和JJ用的是同一个列表. 所以. 前面那个改了. 后面那个也会跟着改
字典删除元素
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦金金⽼老老板'}
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
del dic[k] # 报错dictionary changed size during iteration, 在循环迭代的时候不允许进⾏删除操作
print(dic)
那怎么办呢? 把要删除的元素暂时先保存在一个list中, 然后循环list, 再删除
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦金金⽼老老板'}
dic_del_list = []
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
dic_del_list.append(k)
for el in dic_del_list:
del dic[el]
print(dic)
二.深浅拷贝
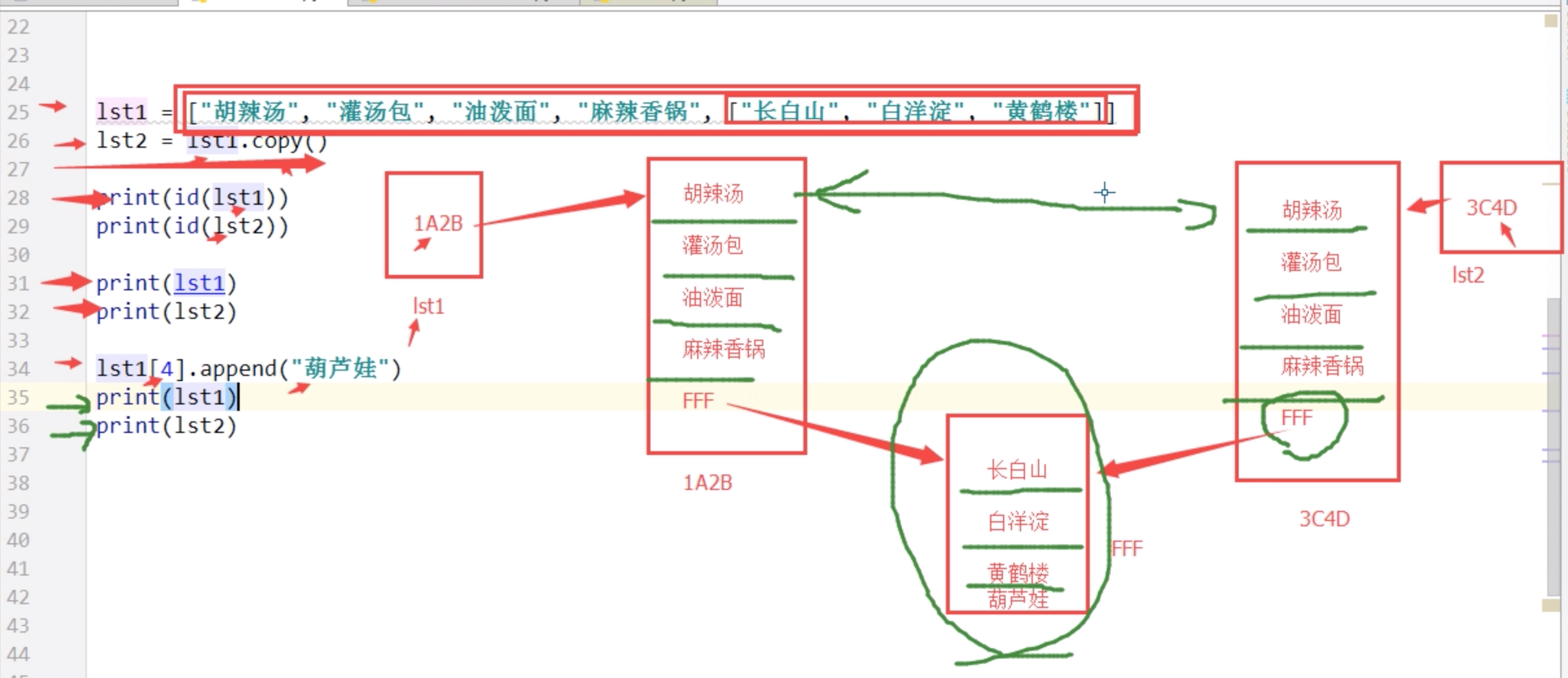
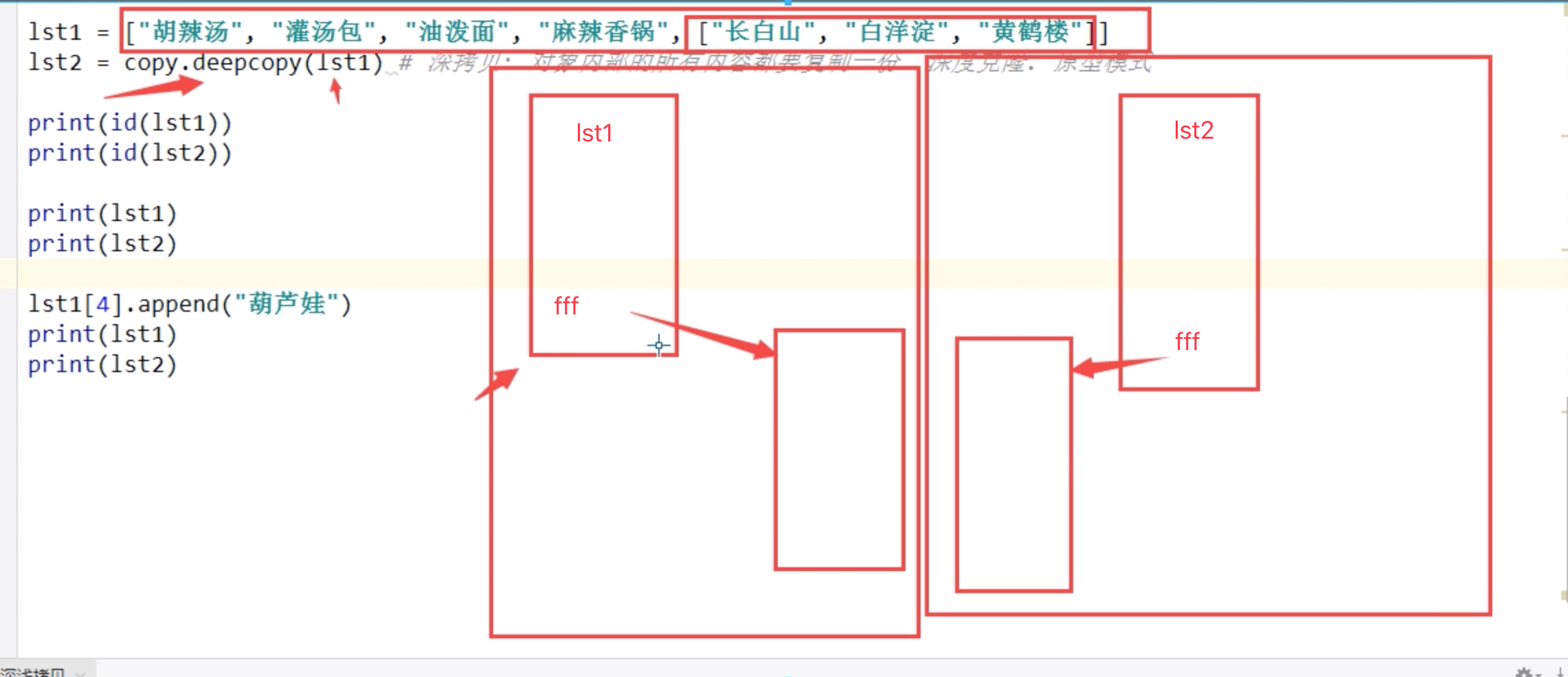
""" 首先注意:拷贝会创建新对象,引用不会创建新对象(一个对象一个不同的内存地址) =:其实就是对象的引用(别名,两者都指向同一个对象),所以会随着原对象的操作而完全同步的变化 深拷贝:完全拷贝了父对象及其子对象,两者是完全独立的,所以完全不会随着原对象的操作而发生任何的变化. 浅拷贝:拷贝父对象,不会拷贝父对象内部的子对象,所以a和b是一个独立的对象,但是他们的子对象还是指向统一的对象(父对象是拷贝,子对象是引用==>父对象是完全独立的,子对象是指向同一个对象的),所以对父对象的操作不会随之变化,对子对象的操作(只有可变数据类型才可以对其元素进行增删改)会随之变化. 一个形象的比喻: =:把我的作业借给你拿给老师检查 浅拷贝:你按照我的作业抄了一份给老师检查,但是少抄了一页,只抄了'见第二页' 深拷贝:你按照我的作业抄了一份给老师检查,连第二页也抄了 """ # = # # 从上到下只有一个列表被创建 lst1 = ["胡辣汤", "灌汤包", "油泼面", "麻辣香锅"] lst2 = lst1 # 并没有产生新对象. 只是一个指向(内存地址)的赋值 # lst2 = lst1[:] # 切片,是浅拷贝 print(id(lst1)) print(id(lst2)) lst1.append("葫芦娃") print(lst1) print(lst2) # 浅拷贝 copy 内部元素都是不可变数据类型 lst1 = ["胡辣汤", "灌汤包", "油泼面", "麻辣香锅"] lst2 = lst1.copy() # 拷贝, 抄作业, 可以帮我们创建新的对象,和原来长的一模一样, 浅拷贝 print(id(lst1)) print(id(lst2)) lst1.append("葫芦娃") print(lst1) print(lst2) # 浅拷贝 copy 内部元素存在可变数据类型 lst1 = ["胡辣汤", "灌汤包", "油泼面", "麻辣香锅", ["长白山", "白洋淀", "黄鹤楼"]] lst2 = lst1.copy() # 浅拷贝. 只拷贝第一层内容 print(id(lst1)) print(id(lst2)) print(lst1) print(lst2) lst1[4].append("葫芦娃") print(lst1) print(lst2) # 深拷贝 deepcopy 不管内部元素是否是可变数据类型,把元素内部的元素完全进⾏拷⻉复制. 不会产⽣一个改变另⼀个跟着 改变的问题 # 引入一个模块 import copy lst1 = ["胡辣汤", "灌汤包", "油泼面", "麻辣香锅", ["长白山", "白洋淀", "黄鹤楼"]] lst2 = copy.deepcopy(lst1) # 深拷贝: 对象内部的所有内容都要复制一份. 深度克隆(clone). 原型模式 print(id(lst1)) print(id(lst2)) # print(lst1) # print(lst2) # # lst1[4].append("葫芦娃") # print(lst1) # print(lst2) # 为什么要有深浅拷贝? 类比于做作业和抄作业,抄作业是不需要思考的,计算复制也一样 # 提高创建对象的速度 # 计算机中最慢的. 就是创建对象. 需要分配内存. # 最快的方式就是二进制流的形式进行复制. 速度最快. # 做作业? 抄作业?
赋值
= 没有创建新对象, 只是把内存地址进行了复制
lst1 = ["⾦金金⽑毛狮王", "紫衫⻰龙王", "⽩白眉鹰王", "⻘青翼蝠王"] lst2 = lst1 print(lst1) print(lst2) lst1.append("杨逍") print(lst1) print(lst2) 结果: ['⾦金金⽑毛狮王', '紫衫⻰龙王', '⽩白眉鹰王', '⻘青翼蝠王', '杨逍'] ['⾦金金⽑毛狮王', '紫衫⻰龙王', '⽩白眉鹰王', '⻘青翼蝠王', '杨逍'] dic1 = {"id": 123, "name": "谢逊"} dic2 = dic1 print(dic1) print(dic2) dic1['name'] = "范瑶" print(dic1) print(dic2) 结果: {'id': 123, 'name': '谢逊'} {'id': 123, 'name': '谢逊'} {'id': 123, 'name': '范瑶'} {'id': 123, 'name': '范瑶'}
对于list, set, dict来说, 直接赋值. 其实是把内存地址交给变量. 并不是复制一份内容. 所以. lst1的内存指向和lst2是一样的. lst1改变了, lst2也发生了改变
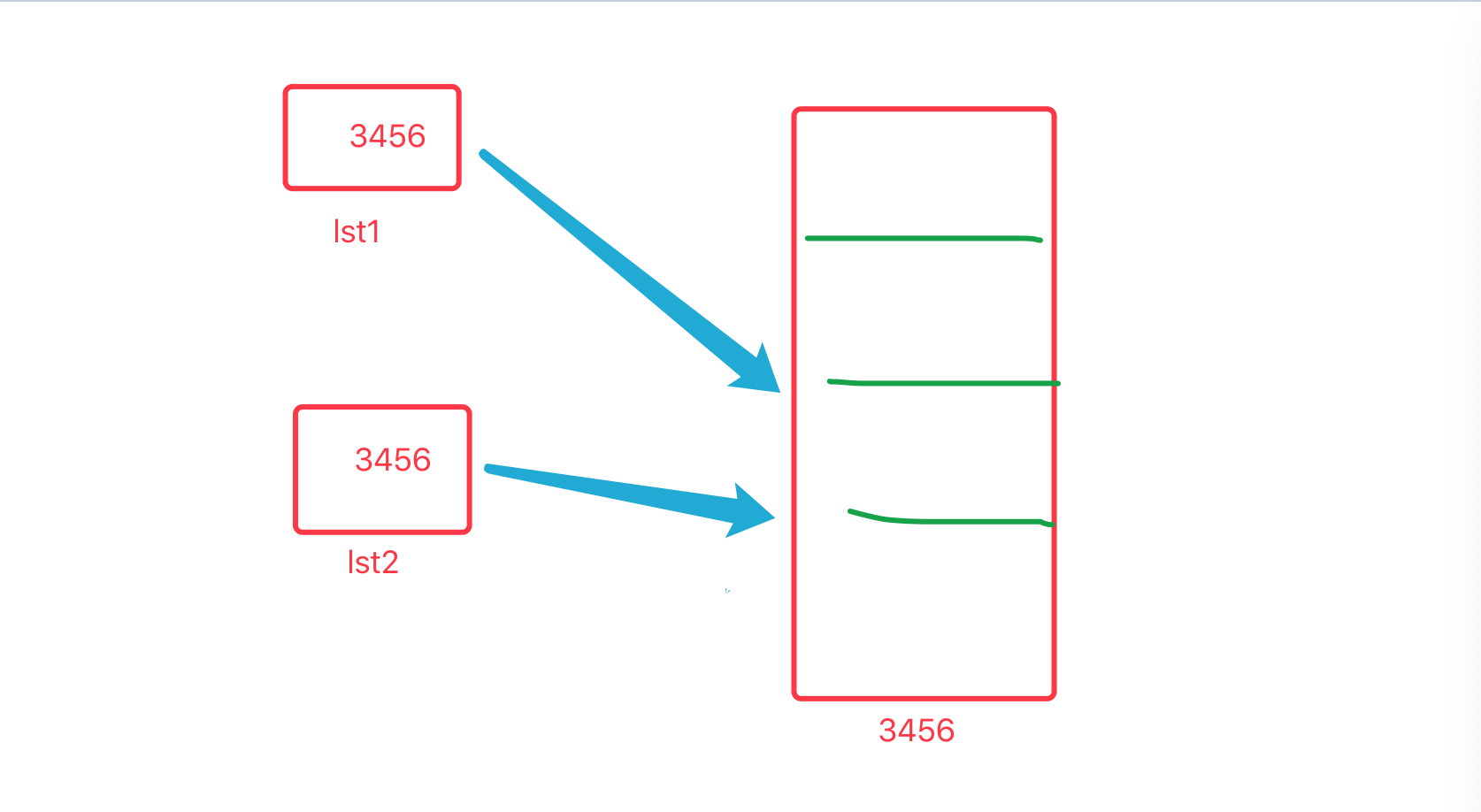
浅拷⻉
lst1 = ["何炅", "杜海海涛","周渝⺠民"] lst2 = lst1.copy()
# 或者
# import copy
# lst2 = copy.copy(lst1) # 使用 copy 模块的 copy.copy( 浅拷贝 ) lst1.append("李李嘉诚") print(lst1) print(lst2) print(id(lst1), id(lst2)) 结果: 两个lst完全不一样. 内存地址和内容也不一样. 发现实现了内存的拷⻉ lst1 = ["何炅", "杜海海涛","周渝⺠民", ["麻花藤", "⻢马芸", "周笔畅"]] lst2 = lst1.copy() lst1[3].append("⽆无敌是多磨寂寞") print(lst1) print(lst2) print(id(lst1[3]), id(lst2[3])) 结果: ['何炅', '杜海海涛', '周渝⺠民', ['麻花藤', '⻢马芸', '周笔畅', '⽆无敌是多磨寂寞']] ['何炅', '杜海海涛', '周渝⺠民', ['麻花藤', '⻢马芸', '周笔畅', '⽆无敌是多磨寂寞']] 4417248328 4417248328
浅拷⻉. 只会拷贝第一层. 第二层的内容不会拷贝. 所以被称为浅拷⻉
深拷贝
import copy lst1 = ["何炅", "杜海海涛","周渝⺠民", ["麻花藤", "⻢马芸", "周笔畅"]] lst2 = copy.deepcopy(lst1) lst1[3].append("⽆无敌是多磨寂寞") print(lst1) print(lst2) print(id(lst1[3]), id(lst2[3])) 结果: ['何炅', '杜海海涛', '周渝⺠民', ['麻花藤', '⻢马芸', '周笔畅', '⽆无敌是多磨寂寞']] ['何炅', '杜海海涛', '周渝⺠民', ['麻花藤', '⻢马芸', '周笔畅']] 4447221448 4447233800
深度拷⻉. 把元素内部的元素完全进⾏拷贝复制. 不会产⽣生一个改变另一个跟着改变的问题
注意:
针对可变类型而言,浅拷贝只是拷贝"第一层",深拷贝就是拷贝所有层级中的可变类型.
不可变的数据类型深浅拷贝是一样的效果,都不会产生一个改变另一个跟着改变的结果.
lst1 = ["胡辣汤", "灌汤包", "油泼面", ["麻辣香锅"]] lst2 = lst1 # 并没有产生新对象. 只是一个指向(内存地址)的赋值 print(id(lst1)) print(id(lst2)) lst1.append("葫芦娃") lst1[3].append("葫芦娃") print(lst1) print(lst2) print("---------------------------------------------------------") lst1 = ["胡辣汤", "灌汤包", "油泼面", ["麻辣香锅"]] lst2 = lst1[:] # 切片,是浅拷贝,通过切片创建新对象,再赋值给lst2 print(id(lst1)) print(id(lst2)) lst1.append("葫芦娃") lst1[3].append("葫芦娃") print(lst1) print(lst2) """ 结果: 4361847880 4361847880 ['胡辣汤', '灌汤包', '油泼面', ['麻辣香锅', '葫芦娃'], '葫芦娃'] ['胡辣汤', '灌汤包', '油泼面', ['麻辣香锅', '葫芦娃'], '葫芦娃'] --------------------------------------------------------- 4361848072 4361806280 ['胡辣汤', '灌汤包', '油泼面', ['麻辣香锅', '葫芦娃'], '葫芦娃'] ['胡辣汤', '灌汤包', '油泼面', ['麻辣香锅', '葫芦娃']] """
最后我们来看一个面试题:
a = [1, 2] a[1] = a print(a[1]) # [1, [...]]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号